我的结论(仅仅代表个人观点)
* 2020年2月的论文
* 论文没有公开代码(20200525),网络计算量,无法确定。
* 分辨率不高,16*16 or 32*32/--------------128*128
* 适用于正脸,不适用于侧脸
* 恢复出来的遮挡区域,依旧模糊
* 关键点,图卷积 and FPN结构
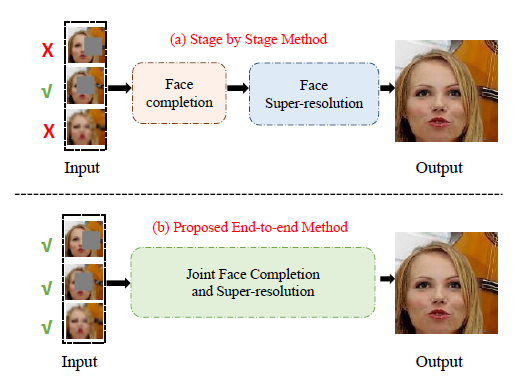
1、题目
《Joint Face Completion and Super-resolution using Multi-scale Feature Relation Learning》
作者:

2、创新点
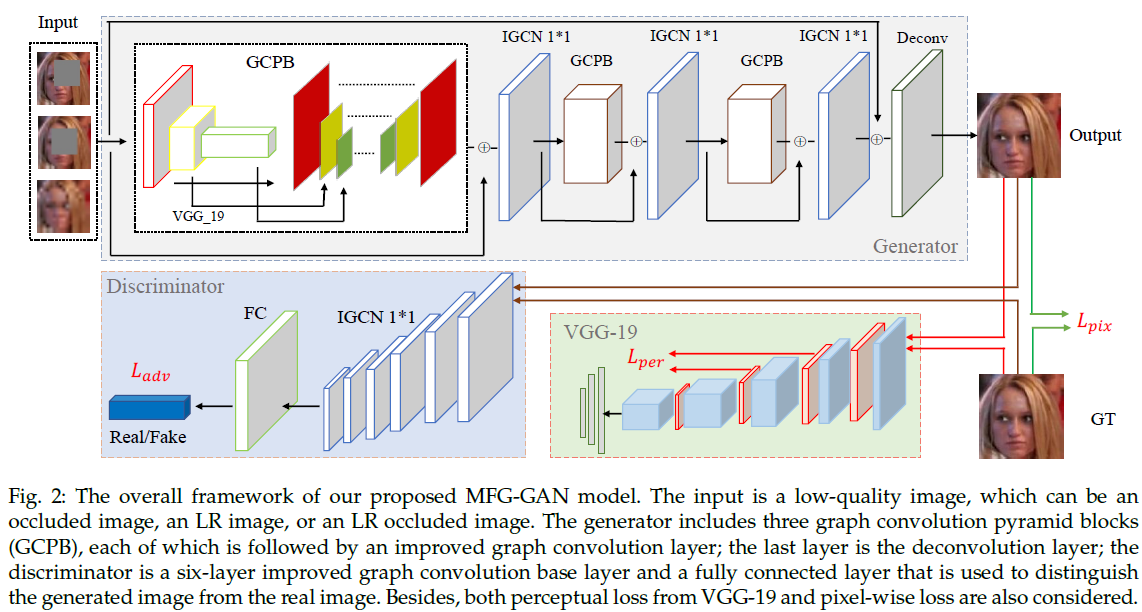
3、网络框架

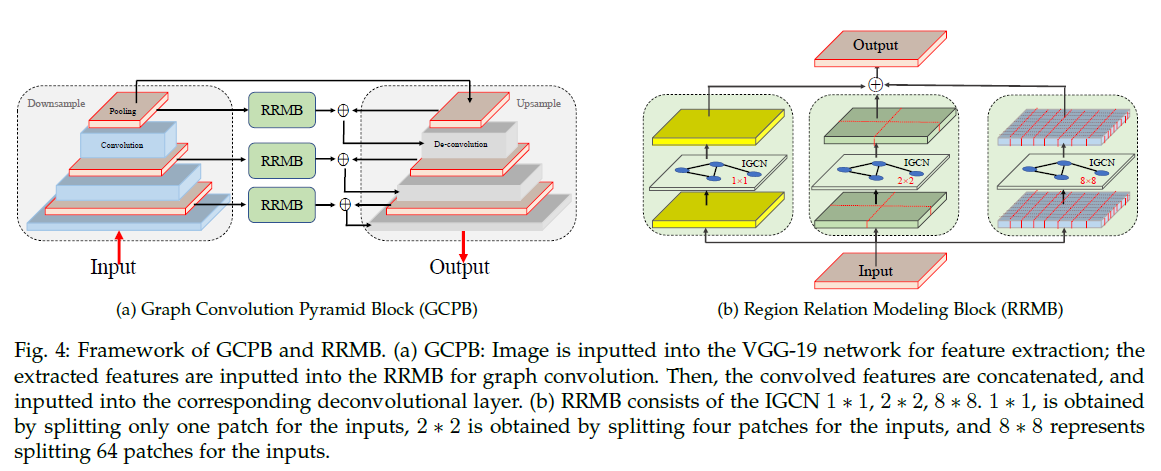
4、loss函数
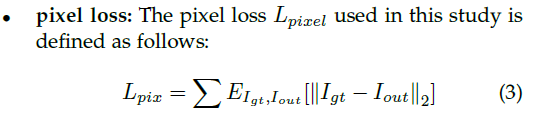

在论文的实验中,参数是![]()
5、实验
AA、实验数据集
a、CelebA数据集:
数据:10177图,202599个脸
划分:162770训练,19867验证,19962测试。
b、Helen数据集:
数据:2330个脸
划分:2000训练,300测试。
CelebA数据集,进行模型的训练、测试和验证。Helen数据集,交叉验证,对模型进行进一步的评估。
BB、实验细节
* Adam优化算法,学习率10.^(-4),kernel size=3, batch size=24
* CeleA数据对齐到144*144大小,然后随机裁剪得到128*128图像。
* Helen采用MTCNN检测人脸特征点,做5点对齐,然后resize脸到128*128*3。
a、the multitask experiments(又要做遮挡,又要做超分辨率)

做了两个实验:
* 4倍下采样,实验SRFC*4
bicubic interpolation method,resize128*128图像,到32*32,随机加入一个binary mask,32*32图中binary mask大小是8*8
* 8倍下采样,实验SRFC*8
bicubic interpolation method,resize128*128图像,到16*16,随机加入一个binary mask,16*16图中binary mask大小是4*4
b、the face completion experiments(做遮挡)

给128*128图像,加入一个binary mask,binary mask大小是32*32
c、the face super-resolution experiments(做遮挡)
八倍下采样,bicubic interpolation method,resize128*128图像,到16*16
CC、结果评价指标

用眼睛看,or用数据说话。
6、实验结果
a、the multitask experiments

b、the face completion experiments

论文给出的结论是:

(仅仅代表个人观点)But,通过图,观察不到这个结论啊。
遮挡面积越小,固定不动的区域越多,观察整个图的视觉效果好,是因为不动区域多引起的,并不是说遮挡区域的恢复能力变好了啊。
把遮挡区域单拿出来看,遮挡部位得到的恢复,都一样的模糊。
c、the face super-resolution experiments
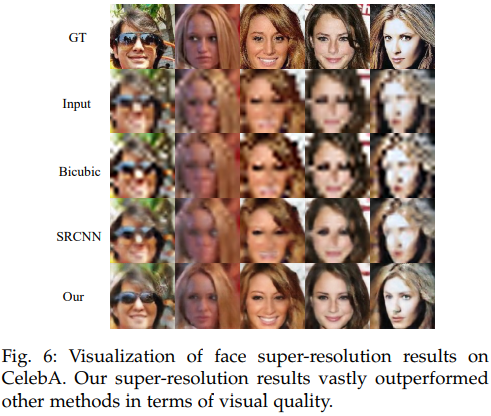
d、Others
M1:含有FPN
M2:含有图卷积
M3:含有IGCN和FPN
******************************************************************
没有FPN结构,效果不好
采用传统的卷积而不采用图卷积,效果不好

**************************

**************************************

************************************************
