---恢复内容开始---
1 把列看成变量来使用。(查询模型)
---恢复内容结束---
where 查询 模型(很重要)
理解 列就是变量 在每一行上,列的值都在变化 where 条件是表达式。在
哪一行上表达式为 真,哪一行就可以取出来 。
2 group 与统计函数
count 函数
select count(*) from t 查询的是绝对的行数,哪怕某一行字段全部为null
而 select count(列名) from t 查询的是该列不为null的所有行数。
那么用count(1) 和count(*) 那个更好些呢?
其实对于 myisam 引擎的表来说没有区别,这种引擎内部有一个计数器维护着行数
Innodb的表,用count(*) 直接读取行数效率很低,因为Innodb真的去要数一遍。
count函数要与分组函数合用功能更多。
3 group 分组函数 分完组后在统计
下列 sql语句
select goods_id sum(goods_number) from goods; 在mysql的低版本中是可以查询出结果的在高版本中会报错的
对于sql标准来说这是一个错误的语句不能执行的,
思考问题:
全班同学排队,校长对老师说要统计同学的姓名和平均年龄 只能返回一行数据,这句话是有问题的
1。只返回一行数据,要把谁的名字和平均年龄一起返回呢?
在myslq的低版本中是把查到的第一条数据的姓名返回的。出于可移植性的考虑不建议这样写,
严格的讲 group by a,b,c 为列 则select 的列 只能在a,b,c 里选择,语义上才没有矛盾。
2 group by 默认 取出 在分组后每一组的第一条信息,因此,如果我们要的数据不是第一条数据,需要用到子查询语句。
4 where 子句的 having 子句 可以对结果集再次筛选,排序等,,排序是针对最终的结果集, 所 以 order by 要放在 where/group by/having 的后面,顺序不能乱。排序 关键字 asc ,desc
5 limit 关键字 有两个参数,(offset,N)---offset表示从哪一行开始,N表示要取出的行数,如果offset
为0 的话可以省略...
6 mysql 的子查询。
where 型子查询: 指的是把内层查询的结果作为外层查询的比较条件
典型题: 如 查询最大的商品,最贵的商品.
如果 where 列=(内层sql) 则内层sql返回的必须是单行单列单个值
如果 where 列 in (内层 sql) 则内层sql只返回单列,可以多个行。
注: 查询的结果集可以再作为一张表来对待。
from 子查询: 即 ,内层sql的查询结果当成是临时表,供外层sql再次查询
典型题 :查询每个栏目下的最新/最贵的商品
Exists子查询:把外层的查询结果,拿到内层,看内层的查询是否成立,
典型题:查询有商品的栏目。
7 为什么建表时加 not null default ''/ default 0? 因为不想列的值为 null
null 是空类型,null的比较需要用 is null ,is not null ,碰到其他运算符一律返回null
效率不高,影响效果,因此在建表时避免字段为null
------------------------------------------------------2019-04-28------------------------------------------------------------------------------------------
8 集合的知识
高中学过的集合知识
集合的特性
1 无序性,
2 唯一性。
, 3 集合的运算,求并集,交集,笛卡尔积(不是数学中的相乘)
一道数学题 集合A 有M个元素,集合B 有N个元素,
那么 A*B有几个元素,答:有 N * M个元素。
----------------------------------------------------
表与集合的关系 ,一张表就是一个集合,每一行就是一个元素,
疑问?集合不能有重复数据,但是在表中可以有重复的数据。(错误,因为数据库中有默认的rowid)
注:在数据
库中如何完成集合相乘的效果,答:直接用“,”隔开表名查询即可。
9. 两表做相乘,
从行的角度说就是2表的每一行两两组和,
从列的角度来看,结果集中的列是两表的列名的相加。
两张表相乘在数据库中比如 a表 10000行,b表10000行,做全相乘的话
10000 * 10000 会在数据库服务器端生成一张很大的临时表,占用了很大的内存,极大的影响了数据库的效率。l另外,没有利用索引,效率很低的。
10 左连接的语法:
假设A表在左,B表在A表的右边互动,A表与B表通过一个关系来筛选B表的行。
语法: A表 left join B on 条件 如果条件为真,则B 表对应的行取出
那么 A表 left join B on 条件 查询的结果集可以看成是一张表 ,设为C,既如此,可以多C表进行查询,where group by having order by limit 等,都是可以使用的。
问: C表的列有哪些呢? 答 :A,B表的列都可以查询到。
11 .左右连接和内连接的区别?
left join on / right join on 没有太大的区别。
内连接的特点:内连接是左右连接的交集。
在mysql中不支持 外连接。。。
12 Union :联合 合并2条或多条数据。sql1 union sql2;
能否把两张表使用Union ? 可以的。
列的名称不一样能不能使用Union ? 可以的 查询结果以第一个sql的列名为主。
不能使用Union的条件? 当两个查询列的数量不一致时。
列的类型也可以不一样。
Union后的结果集能否在排序? 可以的。注意 order by 是针对最后的结果集排序。
外层语句还要对最终的结果再次排序,因此内层的语句的排序就没有意义了,
内层的order by A语句单独使用不会影响结果集,仅排序在执行期间就被Mysql的代码分析器给优化掉了,内层的order by 必须能够影响结果时才有意义,比如配合 limit使用。
Union 会默认去重复的数据,如果不想去掉重复的数据 使用 Union all
13 一个面试题目
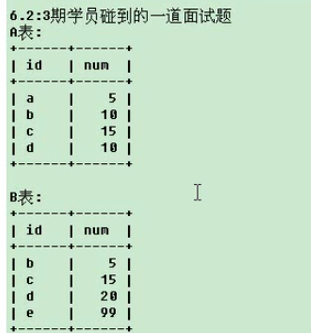
需要查询出如下图结果
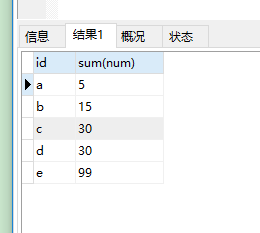
参考答案,select id , sum(num) from (select a.* from a union all select b.* from b ) temp group by id .这里使用了 sum函数和union all