前言
1,背景介绍
数据给出四千张图像作为训练集。每个图像中只有一个图像,要么是圆形,要么是正方形。你的任务根据这四千张图片训练出一个二元分类模型,并用它在测试集上判断每个图像中的形状。
2,任务类型
二元分类,图像识别
3,数据文件说明
train.csv 训练集 文件大小为19.7MB
test.csv 预测集 文件大小为17.5MB
sample_submit.csv 提交示例 文件大小为25KB
4,数据变量说明

训练集中共有4000个灰度图像,预测集中有3550个灰度图像。每个图像中都会含有大量的噪点。图像的分辨率为40*40,也就是40*40的矩阵,每个矩阵以行向量的形式被存放在train.csv 和test.csv中。train.csv 和test.csv 中每行数据代表一个图像,也就是说每行都有1600个特征。
下面左图为train.csv第一行样本所对应的图像(方形),右图为train.csv第二行样本所对应的图像(圆形)。
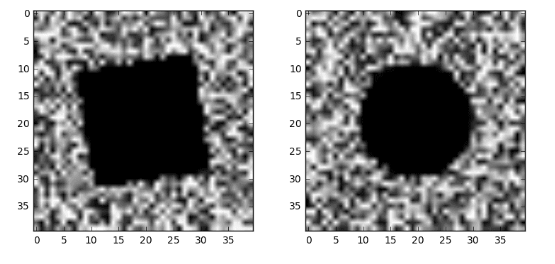
选手的任务是提交预测集中的每个图像的标签(而非概率),标签以 0 或者 1 表示,格式应与sample_submit.csv一致。
train.csv test.csv 均为逗号分隔形式的文件。在Python中可以通过如下形式读取。
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
5,评估方法
提交的结果为每行的预测标签,也就是 0 或者 1 。评估方法为F1 score。
F1 score 的取值范围是0到1,越接近1,说明模型预测的结果越佳。F1-score的计算公式如下:

其中precision为精度,recall为召回,他们可以根据混淆矩阵计算得到。
6,混淆矩阵介绍
可以参考博文:机器学习笔记:常用评估方法
混淆矩阵是用来总结一个分类器结果的矩阵,对于K元分类,其实它就是一个k x k 的表格,用来记录分类器的预测结果。
对于最常见的二元分类来说,它的混淆矩阵是2 * 2的,如下:

TP = True Postive = 真阳性; FP = False Positive = 假阳性
FN = False Negative = 假阴性; TN = True Negative = 真阴性
下面举个例子
比如我们一个模型对15个样本预测,然后结果如下:
预测值:1 1 1 1 1 0 0 0 0 0 1 1 1 0 1
真实值:0 1 1 0 1 1 0 0 1 0 1 0 1 0 0
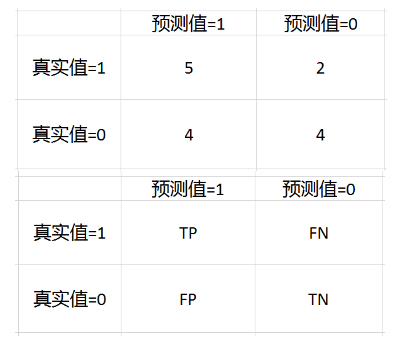
上面的就是混淆矩阵,混淆矩阵的这四个数值,经常被用来定义其他的一些度量。
准确度(Accuracy) = (TP+TN) / (TP+TN+FN+TN)
在上面的例子中,准确度 = (5+4) / 15 = 0.6
精度(precision, 或者PPV, positive predictive value) = TP / (TP + FP)
在上面的例子中,精度 = 5 / (5+4) = 0.556
召回(recall, 或者敏感度,sensitivity,真阳性率,TPR,True Positive Rate) = TP / (TP + FN)
在上面的例子中,召回 = 5 / (5+2) = 0.714
特异度(specificity,或者真阴性率,TNR,True Negative Rate) = TN / (TN + FP)
在上面的例子中,特异度 = 4 / (4+2) = 0.667
F1-值(F1-score) = 2*TP / (2*TP+FP+FN)
在上面的例子中,F1-值 = 2*5 / (2*5+4+2) = 0.625
7,完整代码,请移步小编的github
传送门:请点击我
数据预处理
1,准备工作
PIL详细文档
The most important class in the Python Imaging Library is the Image class, defined in the module with the same name. You can create instances of this class in several ways; either by loading images from files, processing other images, or creating images from scratch.
Python映像库中最重要的类是Image类,定义在具有相同名称的模块中。您可以通过多种方式创建该类的实例;通过从文件加载图像,处理其他图像,或从头创建图像/。
使用之前先按照pillow的包
pip install pillow
2,利用python进行矩阵与图像之间的转换
下面左图为train.csv第一行样本所对应的图像(方形),右图为train.csv第二行样本所对应的图像(圆形)。是我们使用代码进行还原,和上面的结果一样。
import numpy as np
import pandas as pd
from scipy.misc import imsave
def loadData():
# 读取数据
train_data = pd.read_csv('data/train.csv')
data0 = train_data.iloc[0,1:-1]
data1 = train_data.iloc[1, 1:-1]
data0 = np.matrix(data0)
data1 = np.matrix(data1)
data0 = np.reshape(data0, (40, 40))
data1 = np.reshape(data1, (40, 40))
imsave('test1.jpg', data0)
imsave('test1.jpg', data1)
if __name__ =='__main__':
loadData()
结果:

3,使用二值化处理,去噪
灰度化:在RGB模型中,如果R = G = B时,则彩色表示一种灰度颜色,其中R = G = B的值叫灰度值,因此灰度图像每个像素只需要一个字节存放灰度值(又称强度值,亮度值),灰度范围为0-255.一般常用的是加权平均法来获取每个像素点的灰度值。
二值化:图像的二值化,就是将图像的响度点的灰度值设置为0或者255,也就是将整个图像呈现出明显的只有黑和白的视觉效果。
这里参考讨论区网友的意见,在CNN标杆模型中加一个median filter,去除背景中的噪音,把图形变为binary图像,就能加快收敛,Accuracy能达到1。
from scipy.ndimage import median_filter
def data_modify_suitable_train(data_set=None, type=True):
if data_set is not None:
data = []
if type is True:
np.random.shuffle(data_set)
data = data_set[:, 0: data_set.shape[1] - 1]
else:
data = data_set
data = np.array([np.reshape(i, (40, 40)) for i in data])
data = np.array([median_filter(i, size=(3, 3)) for i in data])
data = np.array([(i>10)*100 for i in data])
data = np.array([np.reshape(i, (i.shape[0], i.shape[1], 1)) for i in data])
return data
这里我们对数据进行测试一下,我的测试代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.ndimage import median_filter
def loadData(trainFile, show_fig=False):
train = pd.read_csv(trainFile)
data = np.array(train.iloc[1, 1:-1])
origin_data = np.reshape(data, (40, 40))
# 做了中值滤波
median_filter_data = np.array(median_filter(origin_data, size=(3, 3)))
# 二值化
# binary_data = np.array((origin_data > 127) * 256)
binary_data = np.array((origin_data > 1) * 256)
if show_fig:
# fig = plt.figure(figsize=(8, 4))
plt.subplot(1, 3, 1)
plt.gray()
plt.imshow(origin_data)
plt.axis('off')
plt.title('origin photo')
plt.subplot(1, 3, 2)
plt.imshow(median_filter_data)
plt.axis('off')
plt.title('median filter photo')
plt.subplot(1, 3, 3)
plt.imshow(binary_data)
plt.axis('off')
plt.title('binary photo')
if __name__ == '__main__':
trainFile = 'datain/train.csv'
loadData(trainFile, True)
效果图如下:


我们发现,做了二值处理,效果更佳明显。我们可以看http://sofasofa.io/forum_main_post.php?postid=1002062 的讨论,我直接把讨论内容抠出来了,如下:
所以10和100是作者随手写的,所以我这里做了很多测试,看图的效果,发现1和256很不错。所以后面使用了二值处理(1, 256)做了,结果如下:

效果和(10, 100)没啥区别,可能是运气不太好吧。。。。
模型训练及其结果展示
1,逻辑回归模型(标杆代码)
Logistic回归是机器学习中最常用最经典的分类方法之一,有人称之为逻辑回归或者逻辑斯蒂回归。虽然他称为回归模型,但是却处理的是分类问题,这主要是因为它的本质是一个线性模型加上一个映射函数Sigmoid,将线性模型得到的连续结果映射到离散型上。它常用于二分类问题,在多分类问题的推广叫softmax。
该模型预测结果的F1 score 为0.97318
# -*- coding: utf-8 -*-
from sklearn.linear_model import LogisticRegression
import pandas as pd
import numpy as np
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
train.drop('id', axis=1, inplace=True)
test.drop('id', axis=1, inplace=True)
train_labels = train.pop('y')
clf = LogisticRegression()
clf.fit(train, train_labels)
submit = pd.read_csv('sample_submit.csv')
submit['y'] = clf.predict(test)
submit.to_csv('my_LR_prediction.csv', index=False)
我修改的代码:
#_*_cioding:utf-8_*_
import pandas as pd
from numpy import *
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
# load data
def loadDataSet(trainname,testname):
'''
对于trainSet 数据,每行前面的值分别是X1...Xn,最后一个值对应的类别标签
:param filename:
:return:
'''
datafile = pd.read_csv(trainname)
testfile = pd.read_csv(testname)
print(type(datafile))
dataMat , labelMat = datafile.iloc[:,1:-1] , datafile.iloc[:,-1]
testMat = testfile.iloc[:,1:]
return dataMat , labelMat,testMat
def sklearn_logistic(dataMat, labelMat,testMat,submitfile):
trainSet,testSet,trainLabels,testLabels = train_test_split(dataMat,labelMat,
test_size=0.3,random_state=400)
classifier = LogisticRegression(solver='sag',max_iter=5000)
classifier.fit(trainSet, trainLabels)
test_accurcy = classifier.score(testSet,testLabels) * 100
print(" 正确率为 %s%%" %test_accurcy)
submit = pd.read_csv(submitfile)
submit['y'] = classifier.predict(testMat)
submit.to_csv('my_LR_prediction.csv',index=False)
return test_accurcy
if __name__ == '__main__':
TrainFile = 'data/train.csv'
TestFile = 'data/test.csv'
SubmitFile = 'data/sample_submit.csv'
dataMat, labelMat, testMat = loadDataSet(TrainFile,TestFile)
sklearn_logistic(dataMat , labelMat,testMat,SubmitFile)
结果:
![]()
2,卷积神经网络(标杆代码)
该模型预测结果的F1 score为:0.98632
我提交的结果是 0.99635

# -*- coding: utf-8 -*-
from keras.callbacks import TensorBoard
from keras.layers import Dense, Dropout, MaxPooling2D, Flatten, Convolution2D
from keras.models import Sequential
from keras import backend as K
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
def load_train_test_data(train, test):
np.random.shuffle(train)
labels = train[:, -1]
data_test = np.array(test)
#
data, data_test = data_modify_suitable_train(train, True), data_modify_suitable_train(test, False)
train_x, test_x, train_y, test_y = train_test_split(data, labels, test_size=0.7)
return train_x, train_y, test_x, test_y, data_test
def data_modify_suitable_train(data_set=None, type=True):
if data_set is not None:
data = []
if type is True:
np.random.shuffle(data_set)
data = data_set[:, 0: data_set.shape[1] - 1]
else:
data = data_set
data = np.array([np.reshape(i, (40, 40)) for i in data])
data = np.array([np.reshape(i, (i.shape[0], i.shape[1], 1)) for i in data])
return data
def f1(y_true, y_pred):
def recall(y_true,y_pred):
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
possible_positives = K.sum(K.round(K.clip(y_true, 0, 1)))
recall = true_positives / (possible_positives + K.epsilon())
return recall
def precision(y_true,y_pred):
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
predicted_positives = K.sum(K.round(K.clip(y_pred, 0, 1)))
precision = true_positives / (predicted_positives + K.epsilon())
return precision
precision = precision(y_true, y_pred)
recall = recall(y_true, y_pred)
return 2 * ((precision * recall) / (precision + recall))
def built_model(train, test):
model = Sequential()
model.add(Convolution2D(filters=8,
kernel_size=(5, 5),
input_shape=(40, 40, 1),
activation='relu'))
model.add(Convolution2D(filters=16,
kernel_size=(3, 3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(4, 4)))
model.add(Convolution2D(filters=16,
kernel_size=(3, 3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(4, 4)))
model.add(Flatten())
model.add(Dense(units=128,
activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(units=1,
activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy', f1])
model.summary()
return model
def train_model(train, test, batch_size=64, epochs=20, model=None):
train_x, train_y, test_x, test_y, t = load_train_test_data(train, test)
if model is None:
model = built_model(train, test)
history = model.fit(train_x, train_y,
batch_size=batch_size,
epochs=epochs,
verbose=2,
validation_split=0.2)
print("刻画损失函数在训练与验证集的变化")
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='valid')
plt.legend()
plt.show()
pred_prob = model.predict(t, batch_size=batch_size, verbose=1)
pred = np.array(pred_prob > 0.5).astype(int)
score = model.evaluate(test_x, test_y, batch_size=batch_size)
print(score)
print("刻画预测结果与测试集结果")
return pred
if __name__ == '__main__':
train, test = pd.read_csv('train.csv'), pd.read_csv('test.csv')
train = np.array(train.drop('id', axis=1))
test = np.array(test.drop('id', axis=1))
pred = train_model(train, test)
submit = pd.read_csv('sample_submit.csv')
submit['y'] = pred
submit.to_csv('my_CNN_prediction.csv', index=False)
我修改的CNN代码:
#_*_coding:utf-8
from keras.callbacks import TensorBoard
from keras.layers import Dense, Dropout, MaxPooling2D, Flatten, Convolution2D
from keras.models import Sequential
from keras import backend as K
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from scipy.ndimage import median_filter
def load_train_test_data(train, test):
np.random.shuffle(train)
labels = train[:, -1]
data_test = np.array(test)
data, data_test = data_modify_suitable_train(train, True),data_modify_suitable_train(test, False)
train_x, test_x, train_y, test_y = train_test_split(data, labels, test_size=0.7)
return train_x, train_y, test_x, test_y, data_test
def data_modify_suitable_train(data_set = None, type=True):
if data_set is not None:
data = []
if type is True:
np.random.shuffle(data_set)
data = data_set[:, 0: data_set.shape[1] - 1]
else:
data = data_set
data = np.array([np.reshape(i, (40,40)) for i in data])
data = np.array([median_filter(i, size=(3, 3)) for i in data])
data = np.array([(i>10) * 100 for i in data])
data = np.array([np.reshape(i, (i.shape[0], i.shape[1],1)) for i in data])
return data
def f1(y_true, y_pred):
def recall(y_true, y_pred):
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
possible_positives = K.sum(K.round(K.clip(y_true, 0, 1)))
recall = true_positives / (possible_positives + K.epsilon())
return recall
def precision(y_true, y_pred):
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0 ,1)))
predicted_positives = K.sum(K.round(K.clip(y_pred, 0, 1)))
precision = true_positives / (predicted_positives + K.epsilon())
return precision
precision = precision(y_true, y_pred)
recall = recall(y_true, y_pred)
return 2 * ((precision * recall) / (precision + recall))
def bulit_model(train, test):
model = Sequential()
model.add(Convolution2D(filters= 8,
kernel_size=(5, 5),
input_shape=(40, 40, 1),
activation='relu'))
model.add(Convolution2D(filters=16,
kernel_size=(3, 3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(4, 4)))
model.add(Convolution2D(filters=16,
kernel_size=(3,3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(4,4)))
model.add(Flatten())
model.add(Dense(units=128,
activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(units=1,
activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy',f1])
model.summary()
return model
def train_models(train, test, batch_size = 64, epochs=20, model=None):
train_x, train_y, test_x, test_y, t = load_train_test_data(train, test)
if model is None:
model = bulit_model(train, test)
history = model.fit(train_x, train_y,
batch_size=batch_size,
epochs=epochs,
verbose=2,
validation_split=0.2)
print("刻画损失函数在训练与验证集的变化")
plt.plot(history.history['loss'], label= 'train')
plt.plot(history.history['val_loss'], label= 'valid')
plt.legend()
plt.show()
pred_prob = model.predict(t, batch_size = batch_size, verbose=1)
pred = np.array(pred_prob > 0.5).astype(int)
score = model.evaluate(test_x, test_y, batch_size=batch_size)
print("score is %s"%score)
print("刻画预测结果与测试集结果")
return pred
if __name__ == '__main__':
train = pd.read_csv('data/train.csv')
test = pd.read_csv('data/test.csv')
# train = train.iloc[:,1:]
# test = test.iloc[:,1:]
print(type(train))
train = np.array(train.drop('id', axis=1))
test = np.array(test.drop('id', axis=1))
print(type(train))
pred = train_models(train, test)
submit = pd.read_csv('data/sample_submit.csv')
submit['y'] = pred
submit.to_csv('my_CNN_prediction.csv', index=False)
结果如下:

而如果只是加了中值滤波降噪的话,效果不如降噪与将图像变为二维图像。

我后面做了尝试。将卷积神经网络模型更改,加深一点点,看看效果。模型代码如下:
def bulit_model_new(train, test):
n_filter = 32
model = Sequential()
model.add(Convolution2D(filters=n_filter,
kernel_size=(5, 5),
input_shape=(40, 40, 1),
activation='relu'))
model.add(Convolution2D(filters=n_filter,
kernel_size=(5, 5),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(filters=n_filter,
kernel_size=(5, 5),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(filters=n_filter,
kernel_size=(3, 3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(units=128,
activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy', f1])
model.summary()
return model
得分如下:

算了,放弃将准确率提升到1。
3,Xgboost分类
代码:
#_*_cioding:utf-8_*_
import pandas as pd
from numpy import *
from sklearn.model_selection import train_test_split
import xgboost as xgb
from sklearn.metrics import accuracy_score
# load data
def loadDataSet(trainname,testname):
'''
对于trainSet 数据,每行前面的值分别是X1...Xn,最后一个值对应的类别标签
:param filename:
:return:
'''
datafile = pd.read_csv(trainname)
testfile = pd.read_csv(testname)
print(type(datafile))
dataMat , labelMat = datafile.iloc[:,1:-1] , datafile.iloc[:,-1]
testMat = testfile.iloc[:,1:]
from sklearn.preprocessing import MinMaxScaler
dataMat = MinMaxScaler().fit_transform(dataMat)
testMat = MinMaxScaler().fit_transform(testMat)
return dataMat , labelMat,testMat
def xgbFunc(dataMat, labelMat,testMat,submitfile):
trainSet,testSet,trainLabels,testLabels = train_test_split(dataMat,labelMat,
test_size=0.3,random_state=400)
xgbModel = xgb.XGBClassifier(
learning_rate=0.1,
n_estimators=1000,
max_depth=5,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
objective='binary:logistic',
nthread=4,
seed=27
)
xgbModel.fit(trainSet, trainLabels)
# 对测试集进行预测
test_pred = xgbModel.predict(testSet)
print(test_pred)
from sklearn.metrics import confusion_matrix
test_accurcy = accuracy_score(testLabels,test_pred)
# test_accurcy = xgbModel.score(testLabels, test_pred) * 100
print(" 正确率为 %s%%" %test_accurcy)
submit = pd.read_csv(submitfile)
submit['y'] = xgbModel.predict(testMat)
submit.to_csv('my_XGB_prediction.csv',index=False)
# return test_accurcy
if __name__ == '__main__':
TrainFile = 'data/train.csv'
TestFile = 'data/test.csv'
SubmitFile = 'data/sample_submit.csv'
dataMat, labelMat, testMat = loadDataSet(TrainFile,TestFile)
xgbFunc(dataMat , labelMat,testMat,SubmitFile)
测试集结果:
[1 0 1 ... 1 1 0] 正确率为 0.9975%
预测的结果为0.99635。
![]()
Xgboost调参后的结果:
![]()
4,KNN算法
在讨论区,看见网友们说,KNN不调参都可以达到99%的准确率,我这里就尝试了一下。
代码:
#_*_cioding:utf-8_*_
import pandas as pd
from numpy import *
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# load data
def loadDataSet(trainname,testname):
datafile = pd.read_csv(trainname)
testfile = pd.read_csv(testname)
print(type(datafile))
dataMat , labelMat = datafile.iloc[:,1:-1] , datafile.iloc[:,-1]
testMat = testfile.iloc[:,1:]
return dataMat , labelMat,testMat
def sklearn_logistic(dataMat, labelMat,testMat,submitfile):
trainSet,testSet,trainLabels,testLabels = train_test_split(dataMat,labelMat,
test_size=0.2,random_state=400)
classifier = KNeighborsClassifier()
classifier.fit(trainSet, trainLabels)
test_accurcy = classifier.score(testSet,testLabels) * 100
print(" 正确率为 %.2f%%" %test_accurcy)
submit = pd.read_csv(submitfile)
submit['y'] = classifier.predict(testMat)
submit.to_csv('my_KNN_prediction.csv',index=False)
return test_accurcy
if __name__ == '__main__':
TrainFile = 'data/train.csv'
TestFile = 'data/test.csv'
SubmitFile = 'data/sample_submit.csv'
dataMat, labelMat, testMat = loadDataSet(TrainFile,TestFile)
sklearn_logistic(dataMat , labelMat,testMat,SubmitFile)
这里提交的是Nearest-Neighbors的测试结果 0.99062:
![]()
5,使用随机森林等8种算法尝试
之前在随机森林算法笔记里(传送门:机器学习笔记——随机森林)尝试了随机森林算法与其他算法对比的优势,这里觉得题目简单,就来尝试一下,结果发现确实有好几种优秀的算法可以对此二分类,话不多说,直接看结果。
代码:
#_*_cioding:utf-8_*_
import pandas as pd
from numpy import *
from sklearn.model_selection import train_test_split
import xgboost as xgb
from sklearn.metrics import accuracy_score
# load data
def loadDataSet(trainname,testname):
'''
对于trainSet 数据,每行前面的值分别是X1...Xn,最后一个值对应的类别标签
:param filename:
:return:
'''
datafile = pd.read_csv(trainname)
testfile = pd.read_csv(testname)
print(type(datafile))
dataMat , labelMat = datafile.iloc[:,1:-1] , datafile.iloc[:,-1]
testMat = testfile.iloc[:,1:]
from sklearn.preprocessing import MinMaxScaler
dataMat = MinMaxScaler().fit_transform(dataMat)
testMat = MinMaxScaler().fit_transform(testMat)
return dataMat , labelMat,testMat
def AlgorithmFunc(dataMat, labelMat,testMat,submitfile):
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier,ExtraTreesClassifier
from sklearn.naive_bayes import GaussianNB
trainSet, testSet, trainLabels, testLabels = train_test_split(dataMat,labelMat,
test_size=0.3,random_state=400)
names = ['Nearest-Neighbors','Linear-SVM', 'RBF-SVM','Decision-Tree',
'Random-Forest', 'AdaBoost', 'Naiva-Bayes', 'ExtraTrees']
classifiers = [
KNeighborsClassifier(),
SVC(kernel='rbf', C=50, max_iter=5000),
SVC(gamma=2, C=1),
DecisionTreeClassifier(),
RandomForestClassifier(),
AdaBoostClassifier(),
GaussianNB(),
ExtraTreesClassifier(),
]
for name,classifiers in zip(names, classifiers):
classifiers.fit(trainSet, trainLabels)
score = classifiers.score(testSet, testLabels)
print('%s is %s'%(name, score))
# from sklearn.metrics import confusion_matrix
# test_accurcy = accuracy_score(testLabels,test_pred)
# # test_accurcy = xgbModel.score(testSet, test_pred) * 100
# print(" 正确率为 %s%%" %test_accurcy)
submit = pd.read_csv(submitfile)
submit['y'] = classifiers.predict(testMat)
submit.to_csv('my_'+ str(name) +'_prediction.csv',index=False)
# return test_accurcy
if __name__ == '__main__':
TrainFile = 'data/train.csv'
TestFile = 'data/test.csv'
SubmitFile = 'data/sample_submit.csv'
dataMat, labelMat, testMat = loadDataSet(TrainFile,TestFile)
AlgorithmFunc(dataMat , labelMat,testMat,SubmitFile)
测试结果:
Nearest-Neighbors is 0.9925 Linear-SVM is 0.9758333333333333 RBF-SVM is 0.5233333333333333 Random-Forest is 0.9975 Decision-Tree is 0.9825 AdaBoost is 0.9808333333333333 Naiva-Bayes is 0.8858333333333334 ExtraTrees is 0.9891666666666666
这里打算提交随机森林的结果,看看测试集的精度:
![]()