Transformer简介
特点:
1、注意力机制
不需要循环和卷积,计算量相对较小,可为训练节省时间。
解决了由输入句子较长造成中间向量难以存储足够信息的问题。注意力机制允许解码器随时查阅输入句子中的部分单词或片段,因此不需要在中间向量中存储所有信息。
2、可并行化设计
对上一层的网络的依赖较小,易设计成并行化。
一、Transformer的网络结构图
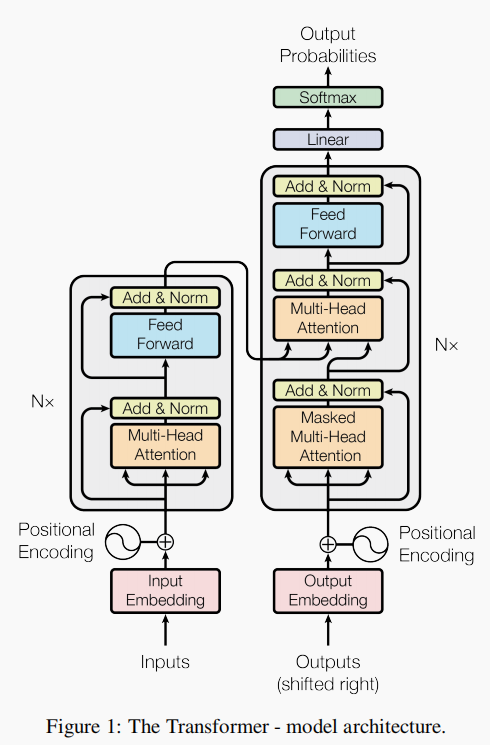
二、Transformer的网络结构介绍
1、Encoder
Encoder网络结构介绍

1-1 Input Embedding
首先将原始词通过one-hot编码转换为可计算的词向量。但是该种方法会让词向量矩阵变得非常稀疏,导致模型精度下降,所以还要对初始生成的词向量矩阵进行Word Embedding。将初始生成的词向量矩阵乘以一个待训练的权重矩阵W,可将原始生成的高维稀疏得词向量矩阵转换成一个低维稠密的词向量矩阵。
1-2 Positional Encoding
尽管我们获得了词向量矩阵,但是词与词之间的顺序并不确定,需要添加词与词之间的位置信息,可以使用不同频率得正弦或余弦函数进行映射。得到的位置信息与词向量矩阵相加得到带有位置信息的词向量矩阵。其中 pos 表示位置index, i 表示dimension index。
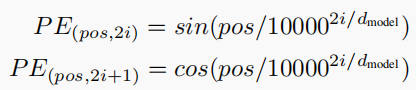
1-3 Multi-Head Attention
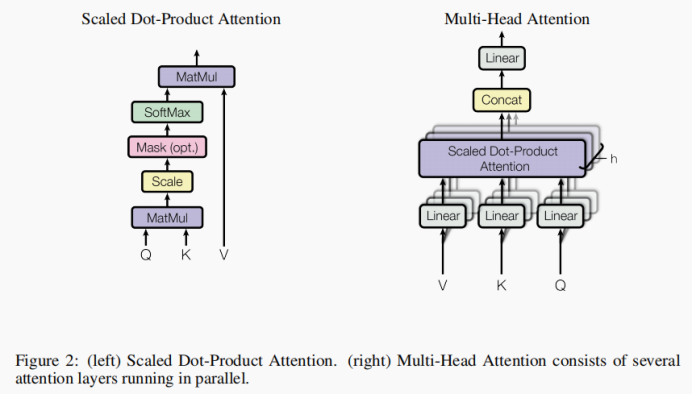
Scaled Dot-Product Attention,将Q矩阵乘上K矩阵的转置然后再进行缩放,得到的矩阵经softmax()函数归一化,最后再乘上矩阵V。
为什么要进行缩放?这里举一个小例子。假设q、k的分量是均值为0,方差为1的独立随机变量,则
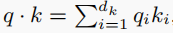
均值为0,方差为dk。
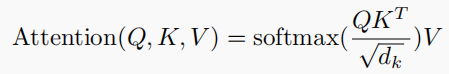
Multi-Head Attention,先对Q、K、V进行相应的线性变换,其次再使用注意力函数进行处理,然后将单个的注意力机制处理获得矩阵进行拼接,最后再进行线性变换处理。

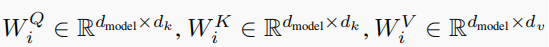

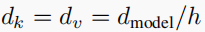
1-4 Feed Forward
前馈神经网络,对经过注意力函数处理的词向量矩阵进行线性变换。
1-5 ADD&Norm
LayerNorm中的Sublayer为LayerNorm的上一层网络,x表示Sublayer的上一层网络的输出。
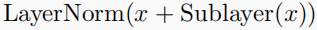
2、中间过渡部分
3、Decoder
Decoder网络结构介绍