讲授Boosting算法的原理,AdaBoost算法的基本概念,训练算法,与随机森林的比较,训练误差分析,广义加法模型,指数损失函数,训练算法的推导,弱分类器的选择,样本权重削减,实际应用。
AdaBoost算法它最典型的应用是视觉的目标检测,比如说人脸检测、行人检测、车辆检测等等。在深度学习流行之前,用这些简单的特征加上AdaBoost分类器来做目标检测,始终是我们工业界的一个主流的方案,在学术界里边它发的论文也是最多的。
大纲:
实验环节
应用简介
VJ框架简介
分类器级联
Haar特征
训练算法的原理
训练自己的模型
VJ框架的各种改进型
整体总结
实验环节:
可以选择不同的训练样本集和训练参数,如弱分类器的数量、弱分类器的参数如决策树的深度参数,配置完参数之后来训练它。可以体验这么几个内容:弱分类器的数量T对精度有什么影响;弱分类器的规模,决策树深度对分类结果的影响。调整参数,训练不同的模型,观看分类结果的精度值。
如果使用决策树做弱分类器,AdaBoost的预测函数是分段常数函数,以下是使用决策树为弱分类器的AdaBoost解决异或问题(训练时需要指定弱分类器的数量,决策树的参数如最大深度等):
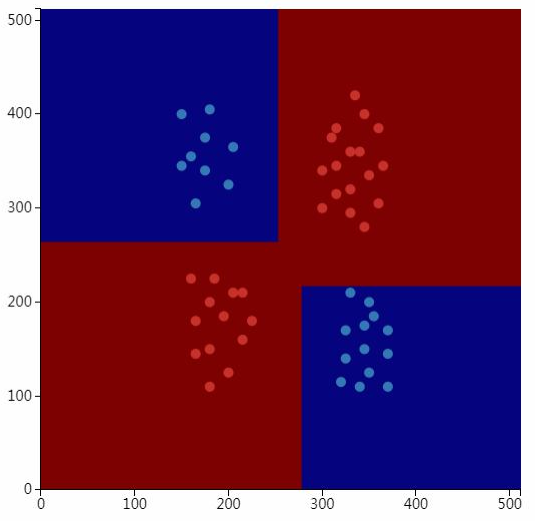
观察算法运行的中间过程的实验:训练每个弱分类的时候,循环里包含几个过程:训练一个弱分类器;计算弱分类器的准确率;更新样本的权重。可以构造一些样本来来观看训练的过程。
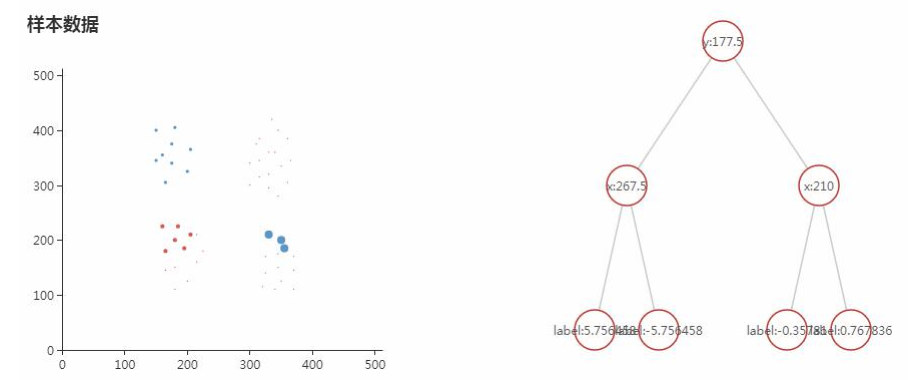
被前面的弱分类器正确分类的样本权重会减小,错误分类的样本权重会增大。
应用简介:
AdaBoost算法最成功的应用是视觉目标检测,2001~2014,直到2014年卷积神经网络大规模用于目标检测以后才把它的江湖地位给取代掉,流行了13年之久,用AdaBoost算法做目标检测,速度非常快而且精度也挺高。除了用于人脸检测外,在工业上还可以用来做行人检测,如人的头部和肩部,还有其他的一些目标,如车牌检测、车辆检测等等。
它在数据分析里边也得到成功的应用,用来解决二分类问题,当然AdaBoost的扩展版本可以用来解决多分类问题。
另外一个典型的应用就是人脸识别,在卷积神经网络大规模的用于人脸识别之前,它也广泛的被用来做人脸识别,这时候的人脸识别要转化为人脸验证问题,也就是判断两张照片是不是属于同一个人,如果是同一个人它是正样本否则它是负样本,只要把特征提出来以后,最后用AdaBoost算法来判断一遍就可以了,把这两个样本(两张照片)特征合起来就形成一个大的特征向量,告诉分类器是正样本还是负样本,训练一个模型之后,最后用来预测就OK了。
VJ框架简介:
P.Viola and M.Jones. Rapid object detection using a boosted cascade of simple features. In Proceedings IEEE Conf.on Computer Vision and Pattern Recognition, 2001.
VJ框架这种方法是人脸检测历史上的一个里程碑,历史上第一个大的突破,2001年由Viola和Jones发布于CVPR上面的,将他们名字简写称为VJ框架,它奠定了目标检测的一个经典的框架,AdaBoost+人工特征+滑动窗口技术,这是长期以来一个经典的方案,直到后来被卷积神经网络给取代掉。
这是一篇很经典的文章。
目标:保证检测精度的前提下具有实时的速度,即使在当时那种计算条件下而且不用GPU只用简单的CPU就能达到实时。
它主要有两个创新点:使用级联的AdaBoost分类器;能快速计算的Haar特征。
人脸检测的两个核心的指标:
检测率 = 检测出的人脸数/实际的人脸数
误报率 = 误判为人脸的图像数/负样本总数
显然我们的检测器它要在低误报率的前提下拥有高的检测率,即ROC曲线下的面积越大越好。
滑动窗口技术:
目标检测中,如人脸检测,一张图片中任何地方都可能出现人脸,因此需要对图像从上到下,从左到右进行扫描--解决人脸可能出现在图像任何一个位置的问题。用一个固定大小的框,慢慢往右往下滑,然后框住的区域是人脸还是不是人脸,这样就转化为二分类的问题了,正样本就是人脸,负样本就是非人脸。
人脸可能有不同的大小,要把图像缩小,总有一张人脸在缩放之后是24*24的大小。
这就是滑动窗口核心的一个做法,有了滑动窗口之后,就可以用一个固定大小的框把图像框住,反复判断被框住的区域是人脸还是不是人脸,下边级联的AdaBoost算法就是来解决这个问题的。扫描一张图像所有的窗口来判读是人还是非人脸,这个运算量大得惊人,一般都是1百万这样级别的窗口数,所以说要求我们的二分类算法要速度非常快并且精度非常高,这样级联的AdaBoost算法就是为了满足这两个指标而设计出来的一种算法。
分类器级联的原理:
分类器级联cascade后边还被用来和CNN或其他算法相结合来做目标检测,它是基于什么样的思想呢?人脸在图像中的出现是一个小概率事件,用简单分类器快速把不是人脸的大部分窗口排除掉。
一个窗口图像如果通过了每一级分类器,则认为是人脸;如果被其中任何一级分类器否定掉,则不是人脸。
级联具体是怎么做的呢?VJ原论文中的图可以解释这一过程。

所有要判断是否是人脸的24*24的图像块都送到分类器中,每个分类器都是强分类器,一号分类器可能有1棵决策树,2号分类器可能有10棵决策树,3号分类器可能有100棵决策树,规模是越来越复杂,但是他们判断的结果是越来越准确的。将图像块送到第一个分类器,若判断是人脸则继续下一个分类器判断,否则就扔掉了,即判断为是人脸的唯一路径是通过所有分类器的筛选以后才能判断是人脸,中间任何一个强分类器不通过则判定为非人脸。
因此就可以得到一些指标:
检测率: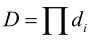 ,检测率随着级数增加而下降。
,检测率随着级数增加而下降。
误报率: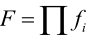 ,误报率随着级数增加而下降。
,误报率随着级数增加而下降。
强分类器带有阈值: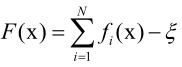 ,阈值来调节灵敏度。
,阈值来调节灵敏度。
Haar特征:
VJ框架第二个创新点是使用了简单的Haar特征,弱分类器总要输入一个特征向量,这个特征用Haar特征。
Haar源自于小波分析(小波分析是傅里叶变换的一种发展,它有两种解释,第一种是信号的多尺度的分解分析第二种是时空的分析,小波也有很多种)中的Haar小波(Haar小波是把信号反复的取均值和差异,然后分解得到一个多尺度分解的目的,在图像里边Haar特征是两块相邻的或间隔的矩形区域,它们像素值的和的差值)变换,Haar小波是最简单的小波函数,用于对信号进行均值、细节分解。
Haar特征定义为图像中相邻矩形区域像素之和的差值。
Haar特征是白色矩形框内的像素值之和,减去黑色区域内的像素值之和。

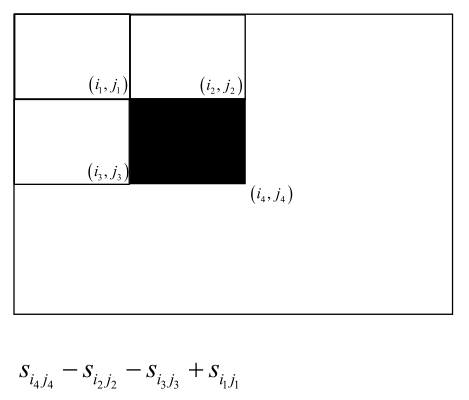
积分图是指图像上任意一点左上的图像的所有像素点之和,给一张图像从左往右滑从上往下滑就可以算出它的积分图。
根据积分图就可以快速的把Haar特征算出来,比如计算下图的黑色矩形框要三次运算,两个矩形,再相减,共7次运算,通过7次运算可以把任何一个两个矩形框的Haar特征给计算出来,三个矩形框就稍微多几次运算。
积分图是一种非常巧妙的方式,后边把VJ发扬光大的时候,设计了一些新的特征,如HoG特征(2005年发明的,设计最初不是用来和AdaBoost整合的,是和SVM整合的)。
计算出一个Haar特征之后就可以送到弱分类中来判断fi(x),判断完之后就可以得到他的预测结果了。
训练算法的原理:
前面讲了Haar特征还有分类器级联的这种方案,任何一个矩形区域它的Haar特征计算出来之后送到每一级强分类器中去判断,然后得到一个最终的输出结果,用级联分类器来判断它最终是人脸还是不是人脸。
说完了这种检测算法之后,我们来说训练算法。
这些级联的强分类器怎么训练出来的呢?每个强分类器就是标准的AdaBoost算法训练流程,给它一些正样本负样本来训练就可以了,算法是依次训练每一级强分类器,每一级都是一个AdaBoost分类器,把Haar特征提出来来训练每一个弱分类器。
这里的正负样本是有讲究的,每一级强分类器在训练时使用所有的人脸样本作为正样本,并用上一级强分类器对负样本图像进行扫描,把找到的虚警中被判定为人脸的区域截取出来作为下一级强分分类器的负样本。
F(x)=Σaifi(x) + ε,其中ε是阈值,阈值取多少合适呢?还有弱分类器个数取多少合适呢?其实这两个问题是一起解决的,在训练过程中,不停的去训练弱分类器,弱分类器数量越多的话,强分类器算法的精度会越高(检测率会上升误报率会下降),每训练一个弱分类器用强分类器来判断一便,把所有的分类样本算一遍,然后把强分类器不考虑阈值时的预测值把正样本、负样本从高到低排序。排好之后,对于正样本卡检测率d,选一个阈值,即大于阈值的样本数满足检测率指标,则选择该值做阈值。得到ε阈值之后,对于负样本,卡阈值,大于该阈值的样本都是被误报的样本,看该样本数是否满足误报率,如果不满足则继续增加弱分类器,直到满足误报率,则这一轮的强分类器和阈值都已经训练出来了,否则继续下一轮循环再训练一个弱分类器把它加进来使得更准确一些。
即弱分类器的数量、级联阈值通过检测率和误报率指标进行确定。首先确保检测率,得到级联阈值,然后计算该阈值下的误报率,如果得到要求,则终止本级强分类器的训练。
训练自己的模型:
说完了原理以后,怎么训练自己的模型呢?开源库opencv提供了一个训练程序叫opencv_traincascade,它可以训练自己的检测器,这里它支持各种形式的AdaBoost算法,上面我们讲的是离散型的AdaBoost算法,除此之外还有实数型的等等,除了支持Haar特征之外,还支持其他特征,如HoG特征、LBP形式的特征等等供你选择。
训练模型的时候,主要有以下步骤:
1.准备正样本图像,对于人脸检测,正样本就是人脸,把所有的人脸图像缩放到同样的大小,比如64*64,并且保存到同一个目录下边去。
2.准备负样本图像,一般选择一些背景图像,只要不包含人脸的那种大图像都可以用来做负样本,算法训练的时候会从这些大图像里边抽样,抽64*64小窗口出来来做负样本用。
3.生成正负样本列表文件,这是一种文本格式的文件,文件中的每一行都描述了一个训练样本,对于正样本就是文件的路径名加上里边正样本的数量、正样本的左上角坐标、人脸的高度宽度等。
4.生成.vec文件,为上边正样本文件生成一个.vec的描述文件。
5.训练分类器,生成描述文件之后就可以用分类器的训练算法opencv的traincascade来训练了。
正样本是要检测的目标,如人脸。所有正样本都要缩放到同样的大小,并且需将这些图像放到同一个目录下(如pos)。
负样本是不包括要检测的目标的任何图像。它的尺寸可以很大,程序在使用负样本图像时会进行裁剪采样。负样本图像放到同一个目录下(如neg)。
在准备好正负样本图像之后,接下来我们生成它们的描述文件。首先,我们在命令行中切换到正样本图像所在的目录下,输入如下命令:
dir/b>posfiles.txt
文件每一行为该目录下的一个图像文件名,注意,posfiles.txt这个文件名也会出现在这个文件中,我们需要把这一行找到删掉。在文件的每一行后面,我们还需要加入1 0 0 w h,其中,w和h是正样本图像的高度和宽度,如64*64,1表示该正样本中只有一张人脸,00表示人脸左上角坐标是(0,0)。
以同样的方式生成负样本描述文件,不过不需要在每一行后面加上1 0 0 w h。
在生成正负样本的列表文件之后,再用opencv_createsamples程序生成样本描述文件,因为opencv的训练程序必须要求正样本描述文件是要满足它的格式的,命令如下:
opencv_createsamples.exe -info posfiles.txt -vec pos.vec -num 1024 -w 64 -h 64,其中posfiles.txt是正样本的列表文件,pos.vec是保存的结果文件,1024是正样本的个数,64、64是高度和宽度,命令执行完之后会生成pos.vec文件。
最后一步用opencv的opencv_traincascade程序进行训练:
opencv_traincascade.exe -data model -vec pos.vec -bg negfiles.txt -numPos 700 -numNeg 2100 -featureType HOG -w 64 -h 64 -numStages 20,其中model是模型生成的文件名,pos.vec是正样本的描述文件,negfiles.txt是负样本的列表文件,训练每一级强分类器它需要的正样本的数量以及负样本的数量,还有你使用的什么特征如HOG用Haar也可以,64、64是模板的高度和宽度,numStages是要训练多少级强分类器。
敲完此命令之后屏幕上会不停的输出每一级强分类器的结果,最后他会生成XML格式的文件,把它合并成一个大的模型文件,后边可以把这个模型文件读进来,来用它做目标检测。
VJ框架的各种改进型:
VJ框架出现之后统治江湖十几年之久,直到被CNN在很多地方给取代掉,VJ框架出现了很多改进型,在VJ框架的这篇文章基础之上主要有以下方面的改进:
新的特征如LBP,ICF,ACF,其他类型的AdaBoost分类器如实数型和Gentle型,新的分类器级联结构如soft cascade(之前介绍的硬级联结构,即被任一级强分类器否定了就认定不是人脸),用于解决多视角人脸检测问题的金字塔级联和树状级联。
总结:
回顾三节课的内容,首先讲了集成学习的思想,然后介绍了和Bagging算法不一样的另一种算法叫Boosting算法的基本思想,在它基础之上介绍了AdaBoost算法它的基本思想(强分类器、弱分类器的概念,以及强分类器是怎么做预测的),然后介绍AdaBoost的训练算法,然后对训练算法进行解释,训练误差的分析即随着弱分类器增加强分类器误差呈指数级下降,然后又从理论上推到了AdaBoost算法的训练算法的依据(广义加法模型,指数损失函数,由这两点就可以导出AdaBoost算法的训练算法的依据了,包括样本权重的计算公式、弱分类器是怎么生成的、弱分类器的权重是怎么计算出来的),介绍完训练算法的推导过程以后,讲了几个实现细节的问题,包括弱分类器的选择、若分类器数量的确定、样本的权重削减,然后做了一些实验,观看训练的效果和过程,然后讲了算法的应用,主要是VJ框架在视觉目标检测里边的应用,包括最后解释了怎么训练自己的模型,而VJ框架两个核心的创新点,即分类器的级联结构cascade、Haar特征。