讲授LDA基本思想,寻找最佳投影矩阵,PCA与LDA的比较,LDA的实际应用
前边讲的数据降维算法PCA、流行学习都是无监督学习,计算过程中没有利用样本的标签值。对于分类问题,我们要达到的目标是提取或计算出来的特征对不同的类有很好的区分度,由于没有用样本的标签值,会导致一个问题,不同的两类样本,如A和B类投影之后交杂在一起无法区分开来,所以这种投影结果对于分类是不利的。线性判别分析LDA是以分类为目的的降维投影技术,把向量X变换为Y,Y的维数更低 ,Y要对分类比较有利能把不同的类有效的区分开来。
大纲:
LDA的思想
寻找最佳投影方向
推广到高维
与PCA的比较
实验环节
实际应用
LDA的思想:
主成分分析,流形降维算法都是无监督学习,整个计算过程中没有利用样本标签值,它们投影的结果对分类未必有利
能不能有一种算法,对数据投影之后,能够更便于分类?
分类要达成的目标:
区分不同的类,同一类的样本特征要尽量相似,不同类之间要尽可能不同,线性判别分析就是达成这种目标的一种线性算法。
目标最直观的表达是,最大化类间差异,最小化类内差异,数学的语言来表达就是方差比较小,使同类样本投影后聚集在一起,不同类样本离得尽可能远。
一维映射y=wTx:
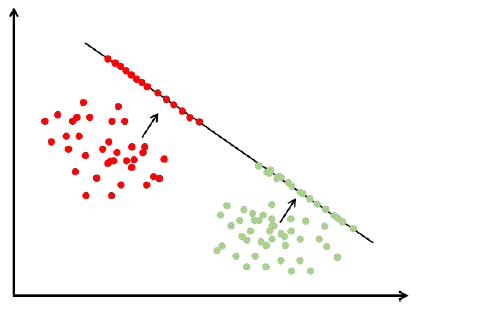
寻找最佳投影方向:
问题的关键是如何得到最佳投影矩阵。
同PCA一样,首先考虑映射到一维的情况,然后考虑映射到高维的情况。
①一维的情况:
整个样本集xi,n个样本,分属两个类,分别是类C1、样本集D1、样本集个数n1,类C2、样本集D2、样本集个数n2,像一维空间投影y=wTx(w矩阵这里为一维向量),投影后得到两组标量Y1、Y2。
类间差异用两个类的均值之差来衡量-类间散布
类内差异用方差来衡量-类内散布
定义变量:
投影之前均值向量:
投影之后的均值向量: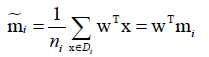
投影之后的类间散布: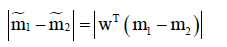
类内散布: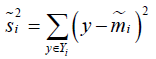 ,是方差的n倍
,是方差的n倍
总类内散布:
则优化目标为: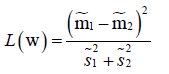 ,类间散布绝对值不好算这里用平方代替,优化目标就是最大化类间散布和最小化类内散布,即分子最大化分母最小化,也可以用分子减去分母来表示误差但是效果没有相除好。
,类间散布绝对值不好算这里用平方代替,优化目标就是最大化类间散布和最小化类内散布,即分子最大化分母最小化,也可以用分子减去分母来表示误差但是效果没有相除好。
定义两个矩阵来简化以上问题表述:
类内散布矩阵:

类间散布矩阵:

那么,优化目标就变为:

显然优化目标有冗余,即w是最优解、kw也会是最优解,即最优解不唯一。为了消掉冗余,简化问题表述,加上一个约束条件:wTSww=1,把分母干掉了,优化分子就行了。
优化的目标变为:max wTSBw,wTSww=1。带等式的约束怎么求解呢?用拉格朗日乘子法来求解。
构造拉格朗日乘子L = wTSBw + λ(wTSww - 1),然后对w和λ求导:
对w求导:SBw+λSww=0,即Sw-1SBw=λw(如果总类内散布矩阵可逆的话,λ是否加负号无所谓它只是一个常数),问题又转换为求一个矩阵的特征值和特征向量问题,即Sw-1SB矩阵最大特征值对应的特征向量就是最佳投影方向。由于SB是一个列向量与行向量的乘积,所以它的秩小于等于一,所以Sw-1SB矩阵的秩小于等于一,它的特征值要么全为0要么有一个非零,即目标是取不为0的唯一的最大特征值对应的特征向量就是最佳投影方向。
②高维的情况:同PCA一样推广到高维,同理定义类内散布矩阵、类间散布矩阵
类内散布矩阵: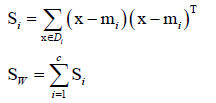
类间散布矩阵: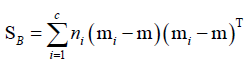
优化目标: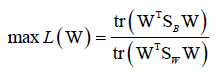
同样的优化目标也是有冗余的,加上约束条件WTSWW=I,化简得到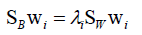 ,最终求解得到W矩阵(这里是W矩阵而非一维向量,m×n,m<n),投影
,最终求解得到W矩阵(这里是W矩阵而非一维向量,m×n,m<n),投影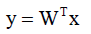 ,将n维向量x投影到m维。
,将n维向量x投影到m维。
LDA与PCA的比较:
两者有一定的相似性,归根到底都是求解矩阵的特征值和特征向量,而且它们推导过程中都用到了拉格朗日乘数法,导致最优解就是矩阵的特征值和特征向量。而且它们两个构造模型过程中都用到了散布矩阵的概念,只不过PCA它没有带类别标签它没有类间散布矩阵和类内散布矩阵一说,而LDA是分开了两个矩阵分别是类间散布矩阵和类内散布矩阵。
它们两个的本质不同是,LDA是有监督学习,而PCA是无监督学习算法;它们投影的目标是不一样的,LDA投影目标是最大化类间差异、最小化类内差异,PCA是最小化重构误差。LDA本身只是一种降维投影技术,x——>y,不能用来分类,后面如果想分类的话可以用别的分类器,如KNN、贝叶斯分类器等,此时分类的效果会更好一些,因为LDA它已经让类更好区分了。
LDA可能面临的一个主要问题是,类内散布矩阵可能不可逆的,这是LDA是失效的。
实验环节:

可以看出LDA是线性分类器。
实际应用:
流形学习虽然看上去很美,但实际应用的并不多,而PCA和LDA是被大规模使用的。
LDA可以用来做分类(非直接做分类),可以用LDA做一个投影之后+一个分类器联合起来做一个分类任务。
PCA和LDA一个最经典的应用是在人脸识别方面的使用,
[1] Matthew Turk,Alex Pentland. Eigenfaces for recognition. Journal of Cognitive Neuroscience, 1991.特征脸算法
[2] Peter N Belhumeur J P Hespanha David Kriegman. Eigenfaces vs. Fisherfaces: recognition using class specific linear projection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1997.
它们两个可以结合起来使用,先用PCA,再用LDA,这些算法代表了最早的一批经典的人脸识别算法:子空间算法,把人脸图像投影到d维空间做分类。投影矩阵每一行代表一个脸的特征叫做一个特征脸,LDA会面临矩阵不可逆,所以可以先用PCA降维的低维空间再用LDA继续降维然后再用KNN或其他分类器进行分类。
本集总结:
LDA的基本思想。
投影到1维、高维,构造散布矩阵求特征值、特征向量。
LDA与PCA的不同,PCA和流形学习都是无监督的数据降维算法,没有用到样本标签。
实际应用的介绍,人脸识别里边的子空间算法,可以用PCA降维+分类器进行分类,也可以用LDA降维+分类器进行分类,还可以用PCA+LDA+分类器进行分类。