前言:
场景感知其实不分三维场景和二维场景,可以使用通用的方法,不同之处在于数据的形式,以及导致前期特征提取及后期在线场景分割过程。场景感知即是场景语义分析问题,即分析场景中物体的特征组合与相应场景的关系,可以理解为一个通常的模式识别问题。
论文系列对稀疏编码介绍比较详细...本文经过少量修改和注释,如有不适,请移步原文
如有评论,请拜访原文。原文链接:http://blog.csdn.net/jwh_bupt/article/details/9837555
参考文章:稀疏编码及其改进(ScSPM,LLC,super-vector coding)
正文
稀疏编码算法是一种无监督学习方法,它用来寻找一组“超完备”基向量来更高效地表示样本数据。稀疏编码算法的目的就是找到一组基向量 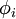 ,使得我们能将输入向量
,使得我们能将输入向量 表示为这些基向量的线性组合:
表示为这些基向量的线性组合:
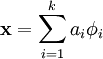
虽然形如主成分分析技术(PCA)能使我们方便地找到一组“完备”基向量,但是这里我们想要做的是找到一组“超完备”基向量来表示输入向量 (也就是说,k >n)。超完备基的好处是它们能更有效地找出隐含在输入数据内部的结构与模式。然而,对于超完备基来说,系数 ai 不再由输入向量 唯一确定。因此,在稀疏编码算法中,我们另加了一个评判标准“稀疏性”来解决因超完备而导致的退化(degeneracy)问题。
(也就是说,k >n)。超完备基的好处是它们能更有效地找出隐含在输入数据内部的结构与模式。然而,对于超完备基来说,系数 ai 不再由输入向量 唯一确定。因此,在稀疏编码算法中,我们另加了一个评判标准“稀疏性”来解决因超完备而导致的退化(degeneracy)问题。
这里,我们把“稀疏性”定义为:只有很少的几个非零元素或只有很少的几个远大于零的元素。要求系数 ai 是稀疏的意思就是说:对于一组输入向量,我们只想有尽可能少的几个系数远大于零。选择使用具有稀疏性的分量来表示我们的输入数据是有原因的,因为绝大多数的感官数据,比如自然图像,可以被表示成少量基本元素的叠加,在图像中这些基本元素可以是面或者线。同时,比如与初级视觉皮层的类比过程也因此得到了提升。
使用稀疏编码算法学习基向量集的方法,是由两个独立的优化过程组合起来的。第一个是逐个使用训练样本 来优化系数ai ,第二个是一次性处理多个样本对基向量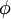 进行优化。
进行优化。
如果使用 L1 范式作为稀疏惩罚函数,对 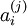 的学习过程就简化为求解 由L1 范式正则化的最小二乘法问题,这个问题函数在域 内为凸,已经有很多技术方法来解决这个问题(诸如CVX之类的凸优化软件可以用来解决L1正则化的最小二乘法问题)。如果S(.) 是可微的,比如是对数惩罚函数,则可以采用基于梯度算法的方法,如共轭梯度法。
的学习过程就简化为求解 由L1 范式正则化的最小二乘法问题,这个问题函数在域 内为凸,已经有很多技术方法来解决这个问题(诸如CVX之类的凸优化软件可以用来解决L1正则化的最小二乘法问题)。如果S(.) 是可微的,比如是对数惩罚函数,则可以采用基于梯度算法的方法,如共轭梯度法。
稀疏编码学习基向量需要大量的计算过程,相对于前馈网络需要更多的学习时间,但对于有超级计算能力的显卡来说,也不是什么大的问题。
Sparse Representatio稀疏编码
稀疏编码系列:
---------------------------------------------------------------------------
上一篇提到了SPM(SPM[1]全称是Spatial Pyramid Matching,出现的背景是bag of visual words模型被大量地用在了Image representation中,但是BOVW模型完全缺失了特征点的位置信息。匹配利用对比比较阈值获取类别标记,分类使用内积获得类别数字)。
这篇博客打算把ScSPM和LLC一起总结了。ScSPM和LLC其实都是对SPM的改进。这些技术,都是对特征的描述。它们既没有创造出新的特征(都是提取SIFT,HOG, RGB-histogram et al),也没有用新的分类器(也都用SVM用于最后的image classification),重点都在于如何由SIFT、HOG形成图像/场景的特征(见图1)。从BOW,到BOW+SPM,都是在做这一步。
说到这,怕会迷糊大家------SIFT、HOG本身不就是提取出的特征么,它们不就已经形成了对图像的描述了吗,为啥还有我后面提到的各种BOW云云呢
 。这个问题没错,SIFT和HOG它们确实本身已经是提取到的特征了,我们姑且把它们记为x。而现在,BOW+SPM是对特征x再进行一层描述,就成了Φ(x)——这相当于是更深一层(deeper)的model。一个十分相似的概念是SVM里面的核函数kernel,K=Φ(x)Φ(x),x是输入的特征,Φ(x)则对输入的特征又做了一层抽象(不过我们用核函数没有显式地对Φ(x)做定义罢了)。根据百度的余凯老师在CVPR2012的那个Tutorial上做的总结[5]:Deeper model is preferred,自然做深一层的抽象效果会更好了。而Deep Learning也是同样的道理变得火了起来。
。这个问题没错,SIFT和HOG它们确实本身已经是提取到的特征了,我们姑且把它们记为x。而现在,BOW+SPM是对特征x再进行一层描述,就成了Φ(x)——这相当于是更深一层(deeper)的model。一个十分相似的概念是SVM里面的核函数kernel,K=Φ(x)Φ(x),x是输入的特征,Φ(x)则对输入的特征又做了一层抽象(不过我们用核函数没有显式地对Φ(x)做定义罢了)。根据百度的余凯老师在CVPR2012的那个Tutorial上做的总结[5]:Deeper model is preferred,自然做深一层的抽象效果会更好了。而Deep Learning也是同样的道理变得火了起来。
再次盗用一些余凯老师在CVPR2012的那个Tutorial上的一些图:
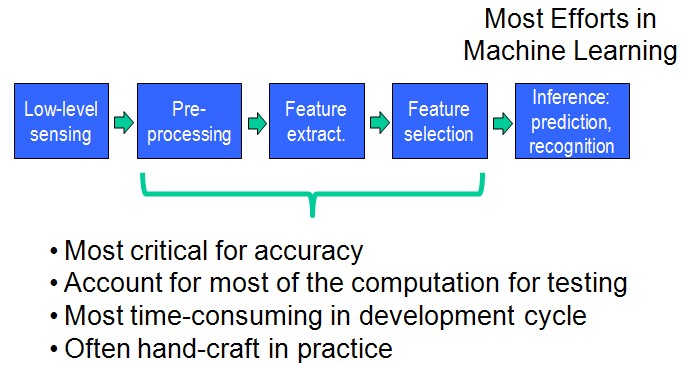
图 (1)
SPM,ScSPM,LLC所做的工作也都集中在design feature这一步,而不是在Machine Learning那一步。值得注意的是,我们一直在Design features,而deep learning则是design feature learners。
BOW+SPM的整体流程如图(2)所示:
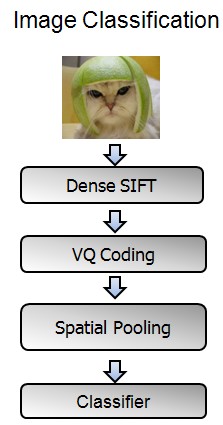
图(2)
Feature Extraction的整体过程就是先提取底层的特征(SIFT,HOG等),然后经过coding和pooling,得到最后的特征表示。
----Coding: nonlinear mapping data into another feature space
----Pooling: obtain histogram
而SIFT、HOG本身就是一个coding+pooling的过程,因此BOW+SPM就是一个两层的Coding+Pooling的过程。所以可以说,SIFT、SURF等特征的提出,是为了寻找更好的第一层Coding+Pooling的办法;而SPM、ScSPM、LLC的提出,是为了寻找更好的第二层Coding+Pooling的办法。而ScSPM和LLC所提出的更好的Coding办法就是Sparse Coding。
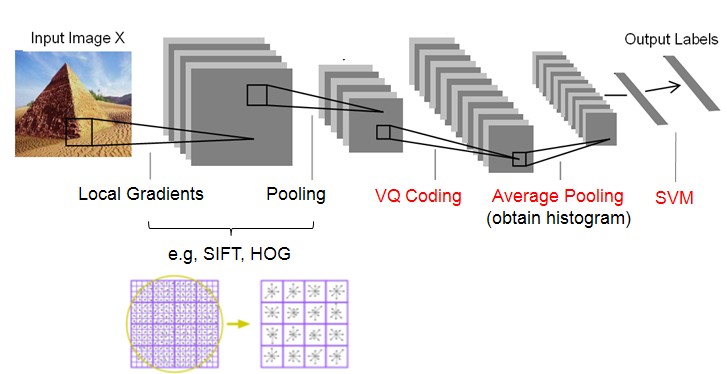
图(3)
在总结ScSPM之前又要啰嗦些话。为啥会有SPM→ScSPM呢?原因之一是为了寻找better coding + better pooling的方式提高性能,原因之二就是提高速度。如何提高速度?这里的速度,不是Coding+Pooling的速度,而是分类器的速度。
SPM设计的是一个Linear feature,在文章中作者用于实验则是用了nonlinear SVM(要用Mercer Kernels)。相比linear SVM,nonlinear SVM在training和testing的时候速度会慢的。至于其原因,我们不妨看看SVM的对偶形式:
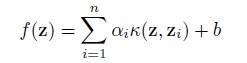
如果核函数是一个线性的kernel:K(z, zi)=zTzi,那么SVM的决策函数就可以改写为:
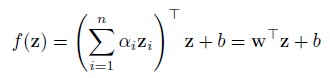
从两式可以看见,抛开训练和存储的复杂度不说,对于测试来说,(1)式对每个测试样本要单独计算K(z, zi),因此testing的时间复杂度为O(n)。而(2)式的wT可以一次性事先算出,所以每次testing的时间复杂度为O(1)。此外,linear classifier的可扩展性会更好。
因此,如果能在coding+pooling后设计得到线性可分的特征描述,那就最好了。因此能否设计一个nonlinear feature + linear SVM得到与 linear feature + nonlinear SVM等效甚至更好的效果,成为ScSPM和LLC的研究重点。
SPM在coding一步采用的是Hard-VQ,也就是说一个descriptor只能投影到dictionary中的一个term上。这样就造成了明显的重建误差(worse reconstruction,large quantization errors)。这样,原本很相似的descripors经过coding之后就会变得非常不相似了(这违背了压缩投影的近邻哈希特性)。ScSPM为此取消了这一约束,它认为descripor可以投影到某几个terms上,而不仅仅是一个。因此,其目标函数变成了:
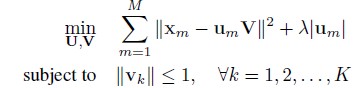
其中M是descriptor的数目,Um表示第m个descriptor在字典V上的投影系数。
它对投影系数用L1-norm做约束实现了稀疏。求解问题称为LASSO (least absolute shrinkage and selection operator,是一种压缩估计。它通过构造一个罚函数得到一个较为精炼的模型,使得它压缩一些系数,同时设定一些系数为零。因此保留了子集收缩的优点,是一种处理具有复共线性数据的有偏估计。Lasso 的基本思想是在回归系数的绝对值之和小于一个常数的约束条件下,使残差平方和最小化,从而能够产生某些严格等于0 的回归系数,得到可以解释的模型 ),在得到稀疏结果的同时,它无法得到解析解,因此速度肯定是很慢的。关于L1-norm和LASSO问题,可以参看这里。
为什么Sparse Coding好,主要有以下几个原因:
1)已经提到过的重建性能好(近邻哈希性能好);[2]
2)sparse有助于获取salient patterns of descripors描述子的显著模式;[2]
3)image statistics方面的研究表明image patches都是sparse signals;[2]
4)biological visual systems的研究表明信号的稀疏特征有助于学习;[4]
5)稀疏的特征更加线性可分。[2]
总之,"Sparse coding is a better building block“。
Coding过后,ScSPM采用的Pooling方法是max pooling:Zj=max Uij。相比SPM的average pooling:Zj=1/M *Σ Uij。可以看见average pooling是一个linear feature representation,而max pooling是nonlinear的。我是这么理解再前言中提到的linear和nonlinear feature的。(@13.08.11:今天在写理解sparse coding的时候发现这里搞错了。不光是pooling的函数是线性的,VQ的coding得到的u关于x好像也是线性的。)
作者在实验中得出max pooling的效果好于average pooling,原因是max pooling对local spatial variations比较鲁棒。而Hard-VQ就不好用max pooling了,因为U中各元素非0即1。
另外实验的一个有趣结果是发现ScSPM对大的codebook size表现出更好的性能,反观SPM,codebook大小对SPM结果影响不大。至于为啥,我也不懂。
LLC(Kai Yu等发在NIPS09上面的文章《Nonlinear learning using local coordinate coding》,作者做实验发现,稀疏编码的结果往往具有局部性,也就是说非零系数往往属于与编码数据比较接近的基。作者提出的局部坐标编码(LCC)鼓励编码满足局部性,同时从理论上指出在一些特定的假设下,局部性比稀疏性更加必要,对于一些非线性学习能够获得非常成功的结果)和ScSPM差不多了,也是利用了Sparsity。值得一说的是,其实Hard-VQ也是一种Sparse Coding,只不过它是一种重建误差比较大的稀疏编码。LLC对ScSPM的改进,则在于引入了locality。为了便于描述,盗用一下论文的图:
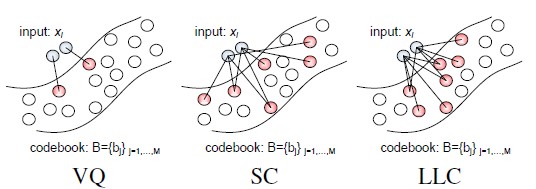
图(4)
这个图实在是太棒了,太能解释问题了。VQ不用说,重点在于SC和LLC之间,LLC引入了locality的约束,即不仅仅是sparse要满足,非零的系数还应该赋值给相近的dictionary terms。作者在[4]中解释到,locality 很重要是因为:
1)nonlinear function的一阶近似要求codes是local的;
2)locality能够保证codes的稀疏性,而稀疏却不能保证locality;
3)稀疏的coding只有再codes有局部性的时候有助于learning。
总之,"locality is more essential than sparsity"。(近邻/局部特性要求是特征提取思想LSH的基本原则)
LLC的目标函数是:
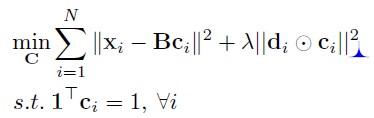
和(3)一样,(4)可以按照加号的前后分成两部分:加号前的一项最小化是为了减少量化误差(学习字典、确认投影系数);加号后的一项则是做出假设约束(包括是一些参数的regularization)。这个求解是可以得到闭合解的,同时也有快速的近似算法解决这个问题,因此速度上比ScSPM快。
di描述的是xi到每个dictionary term的距离。显然这么做是为了降低距离大的term对应的系数。
locality体现出的最大优势就是,相似的descriptors之间可以共享相似的descriptors,因此保留了codes之间的correlation。而SC为了最小化重建误差,可能引入了不相邻的terms,所以不能保证smooth。Hard-VQ则更不用说了。
实验部分,则采用max pooling + L2-normalization。
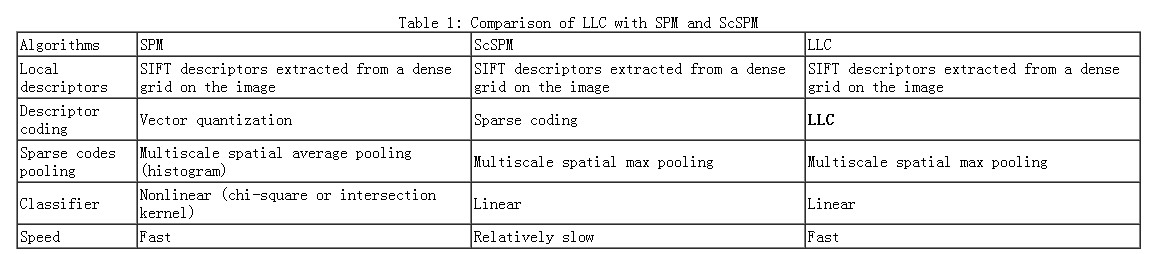
文章的最后,盗窃一个ScSPM第一作者的总结表格结束吧(又是以偷窃别人图标的方式结束
 )
)
References:
[1] S. Lazebnik, C. Schmid, and J. Ponce. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. CVPR2006
[2] Jianchao Yang, Kai Yu, Yihong Gong, and Thomas Huang. Linear spatial pyramid matching using sparse coding for image classification. CVPR2009.
[3] Jinjun Wang, Jianchao Yang, Kai Yu, Fengjun Lv, and Thomas Huang. Locality-constrained linear coding for image classification. CVPR2010
[4] Kai Yu, Tong Zhang, and Yihong Gong. Nonlinear learning using local coordinate coding. NIPS2009.
[5] Kai Yu. CVPR12 Tutorial on Deep Learning: Sparse Coding.
附录:lasso族
在建立模型之初,为了尽量减小因缺少重要自变量而出现的模型偏差,通常会选择尽可能多的自变量。然而,建模过程需要寻找对因变量最具有强解释力的自变量集合,也就是通过自变量选择(指标选择、字段选择)来提高模型的解释性和预测精度。指标选择在统计建模过程中是极其重要的问题。Lasso算法则是一种能够实现指标集合精简的估计方法。
Lasso(Least absolute shrinkage and selection operator, Tibshirani(1996))方法是一种压缩估计。它通过构造一个罚函数得到一个较为精炼的模型,使得它压缩一些系数,同时设定一些系数为零。因此保留了子集收缩的优点,是一种处理具有复共线性数据的有偏估计
Lasso 的基本思想是在回归系数的绝对值之和小于一个常数的约束条件下,使残差平方和最小化,从而能够产生某些严格等于0 的回归系数,得到可以解释的模型。R的Lars 算法的软件包提供了Lasso编程,我们根据模型改进的需要,可以给出Lasso算法,并利用AIC准则和BIC准则给统计模型的变量做一个截断,进而达到降维的目的。因此,我们通过研究Lasso可以将其更好的应用到变量选择中去
lasso estimate具有shrinkage和selection两种功能,shrinkage这个不用多讲,本科期间学过回归分析的同学应该都知道岭估计会有shrinkage的功效,lasso也同样。关于selection功能,Tibshirani提出,当t值小到一定程度的时候,lasso estimate会使得某些回归系数的估值是0,这确实是起到了变量选择的作用。当t不断增大时,选入回归模型的变量会逐渐增多,当t增大到某个值时,所有变量都入选了回归模型,这个时候得到的回归模型的系数是通常意义下的最小二乘估计。从这个角度上来看,lasso也可以看做是一种逐步回归的过程。
模型选择本质上是寻求模型稀疏表达的过程,而这种过程可以通过优化一个“损失”十“惩罚”的函数问题来完成。
2、与普通最小二乘法的区别
使用最小二乘法拟合的普通线性回归是数据建模的基本方法。其建模要点在于误差项一般要求独立同分布(常假定为正态)零均值。t检验用来检验拟合的模型系数的显著性,F检验用来检验模型的显著性(方差分析)。如果正态性不成立,t检验和F检验就没有意义。
对较复杂的数据建模(比如文本分类,图像去噪或者基因组研究)的时候,普通线性回归会有一些问题:
(1)预测精度的问题 如果响应变量和预测变量之间有比较明显的线性关系,最小二乘回归会有很小的偏倚,特别是如果观测数量n远大于预测变量p时,最小二乘回归也会有较小的方差。但是如果n和p比较接近,则容易产生过拟合;如果n
(2)模型解释能力的问题 包括在一个多元线性回归模型里的很多变量可能是和响应变量无关的;也有可能产生多重共线性的现象:即多个预测变量之间明显相关。这些情况都会增加模型的复杂程度,削弱模型的解释能力。这时候需要进行变量选择(特征选择)。
针对OLS的问题,在变量选择方面有三种扩展的方法: (1)子集选择 这是传统的方法,包括逐步回归和最优子集法等,对可能的部分子集拟合线性模型,利用判别准则 (如AIC,BIC,Cp,调整R2 等)决定最优的模型。 (2)收缩方法(shrinkage method) 收缩方法又称为正则化(regularization)。主要是岭回归(ridge regression)和lasso回归。通过对最小二乘估计加入罚约束,使某些系数的估计为0。 (3)维数缩减 主成分回归(PCR)和偏最小二乘回归(PLS)的方法。把p个预测变量投影到m维空间。
3、岭回归、lasso回归和elastic net三种正则化方法
(1)岭回归[]
最小二乘估计是最小化残差平方和(RSS):
岭回归在最小化RSS的计算里加入了一个收缩惩罚项(正则化的l2范数)
这个惩罚项中lambda大于等于0,是个调整参数。各个待估系数越小则惩罚项越小,因此惩罚项的加入有利于缩减待估参数接近于0。重点在于lambda的确定,可以使用交叉验证或者Cp准则。
岭回归优于最小二乘回归的原因在于方差-偏倚选择。随着lambda的增大,模型方差减小而偏倚(轻微的)增加。
岭回归的一个缺点:在建模时,同时引入p个预测变量,罚约束项可以收缩这些预测变量的待估系数接近0,但并非恰好是0(除非lambda为无穷大)。这个缺点对于模型精度影响不大,但给模型的解释造成了困难。这个缺点可以由lasso来克服。(所以岭回归虽然减少了模型的复杂度,并没有真正解决变量选择的问题)
(2)lasso
lasso是在RSS最小化的计算中加入一个l1范数作为罚约束:
l1范数的好处是当lambda充分大时可以把某些待估系数精确地收缩到0。
关于岭回归和lasso,在[3]里有一张图可以直观的比较([3]的第三章是个关于本文主题特别好的参考):[]
关于岭回归和lasso当然也可以把它们看做一个以RSS为目标函数,以惩罚项为约束的优化问题。
(3)调整参数lambda的确定
交叉验证法。对lambda的格点值,进行交叉验证,选取交叉验证误差最小的lambda值。最后,按照得到的lambda值,用全部数据重新拟合模型即可。
(4)elastic net
elastic net融合了l1范数和l2范数两种正则化的方法,上面的岭回归和lasso回归都可以看做它的特例:
elastic net对于p远大于n,或者严重的多重共线性情况有明显的效果。 对于elastic net,当alpha接近1时,elastic net表现很 接近lasso,但去掉了由极端相关引起的退化化或者奇怪的表现。一般来说,elastic net是岭回归和lasso的很好的折中,当alpha从0变化到1,目标函数的稀疏解(系数为0的情况)也从0单调增加到lasso的稀疏解。
LASSO的进一步扩展是和岭回归相结合,形成Elastic Net方法。[]
(5)岭回归与lasso算法[]
这两种方法的共同点在于,将解释变量的系数加入到Cost Function中,并对其进行最小化,本质上是对过多的参数实施了惩罚。而两种方法的区别在于惩罚函数不同。但这种微小的区别却使LASSO有很多优良的特质(可以同时选择和缩减参数)。下面的公式就是在线性模型中两种方法所对应的目标函数:
公式?都懒得打上去吗???
公式中的lambda是重要的设置参数,它控制了惩罚的严厉程度,如果设置得过大,那么最后的模型参数均将趋于0,形成拟合不足。如果设置得过小,又会形成拟合过度。所以lambda的取值一般需要通过交叉检验来确定。
岭回归的一个缺点:在建模时,同时引入p个预测变量,罚约束项可以收缩这些预测变量的待估系数接近0,但并非恰好是0(除非lambda为无穷大)。这个缺点对于模型精度影响不大,但给模型的解释造成了困难。这个缺点可以由lasso来克服。(所以岭回归虽然减少了模型的复杂度,并没有真正解决变量选择的问题)
4、LARS算法对lasso的贡献[]
LAR把Lasso (L1-norm regularization)和Boosting真正的联系起来,如同打通了任督二脉。LAR结束了一个晦涩的时代:在LAR之前,有关Sparsity的模型几乎都是一个黑箱,它们的数学性质(更不要谈古典的几何性质了)几乎都是缺失。
近年来兴起的Compressed sensing(Candes & Tao, Donoho)也与LAR一脉相承,只是更加强调L1-norm regularization其他方面的数学性质,比如Exact Recovery。我觉得这是一个问题的多个方面,Lasso关注的是构建模型的准确性,Compressed sensing关注的是变量选择的准确性。
5、变量选择
当我们使用数据训练分类器的时候,很重要的一点就是要在过度拟合与拟合不足之间达成一个平衡。防止过度拟合的一种方法就是对模型的复杂度进行约束。模型中用到解释变量的个数是模型复杂度的一种体现。控制解释变量个数有很多方法,例如变量选择(feature selection),即用filter或wrapper方法提取解释变量的最佳子集。或是进行变量构造(feature construction),即将原始变量进行某种映射或转换,如主成分方法和因子分析。变量选择的方法是比较“硬”的方法,变量要么进入模型,要么不进入模型,只有0-1两种选择。但也有“软”的方法,也就是Regularization类方法,例如岭回归(Ridge Regression)和套索方法(LASSO:least absolute shrinkage and selection operator)
6、其他
将Lasso应用于时间序列。将Lasso思想应用于AR(p)、ARMA(p)等模型,利用Lasso方法对AR(p)、ARMA(p)等模型中的变量选择,并给出具体的算法。将Lasso方法应用到高维图形的判别与选择以及应用于线性模型的变量选择中,以提高模型选择的准确性。