pytorch官网:http://pytorch.org/上只有PyTroch的ubuntu和Mac版本,赤裸裸地歧视了一把Windows低端用户。
1. Caffe源码:Caffe源码理解之存储
Caffe2存储
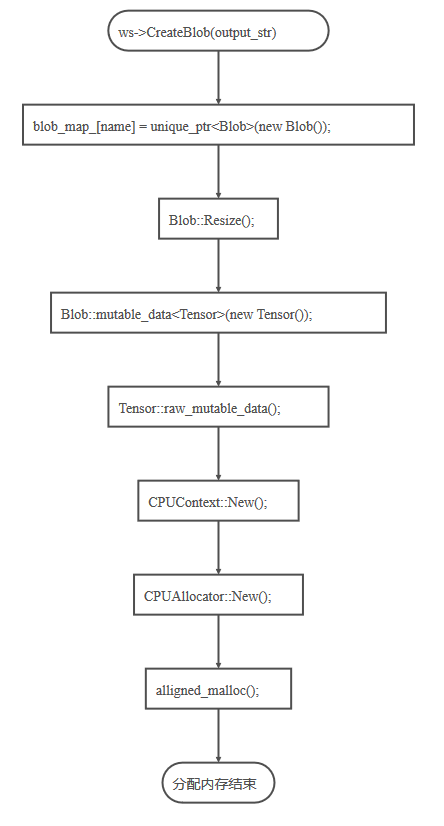
Caffe2中的存储结构层次从上到下依次是Workspace, Blob, Tensor。Workspace存储了运行时所有的Blob和实例化的Net。Blob可以视为对任意类型的一个封装的类,比如封装Tensor, float, string等等。Tensor就是一个多维数组,这个Tensor就类似于Caffe1中的Blob。Caffe2中真正涉及到分配存储空间的调用则在Context中,分为CPUContext和CUDAContext。下面按照从下到上的顺序分析一下Caffe2的存储分配过程。
- Context
- Tensor
- Blob
- Workspace
- 总结
总结
下面是Operator中从创建Blob到实际分配空间的流程,这个图是怎么画出来的呢 :
:
2.Caffe2 Detectron的使用初步
关于InferImage:
在 NVIDIA Tesla P100 GPU 上,单张图片的推断时间大概是 130-140ms.当然这与输入图像的参数设置size有关。
2. Detectron 训练
简单介绍在 COCO Dataset 上训练模型.
采用 ResNet-50-FPN Backbone 进行 end-to-end 的 Faster R-CNN 训练.
这里简单进行模型训练,小尺寸的输入图片,能够使训练和推断的速度相对较快.
2.1 单 GPU 训练
python2 tools/train_net.py
--cfg configs/getting_started/tutorial_1gpu_e2e_faster_rcnn_R-50-FPN.yaml
OUTPUT_DIR /tmp/detectron-output- 输出保存路径
/tmp/detectron-output,如 models, validation set detections 等. - Maxwell GPU,如 M40 上,训练耗时大约 4.2 个小时.
- M40 上,每张图片的推断时间大约是 80 ms.
coco_2014_minival上的 Box AP 大约是 22.1%.
2.2 Multi-GPU 训练
Detectron 提供了基于2、4、8 张 GPUS 训练的 configs 参数配置文件.
如 configs/getting_started/tutorial_{2,4,8}gpu_e2e_faster_rcnn_R-50-FPN.yaml.
如,2 张 GPUs 的训练:
python2 tools/train_net.py
--multi-gpu-testing
--cfg configs/getting_started/tutorial_2gpu_e2e_faster_rcnn_R-50-FPN.yaml
OUTPUT_DIR /tmp/detectron-output--multi-gpu-testing是告诉 Detectron 在训练结束后,采用 multiple GPUs (如NUM_GPUs 为 2) 进行并行化推断.
期望的结果:
- 训练在 2 张 M40 上大概耗时 2.3 个小时.
- 推断时间大约是 80 ms,在 2 张 GPUs 上并行推断时,耗时减半.
coco_2014_minival上的 Box AP 大约是 22.1%.
关于学习方案的调整(“linear scaling rule”),可以参考提供的 config 文件,阅读论文 Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour.
除了这里,其它的 configs 都是基于 8 GPUs.
如果训练的 GPUs 少于 8,或者想尝试改变 minibatch size,有必要理解如何根据 linear scaling rule 来调整训练方案.
注:
这里的训练示例采用了相对低的 GPU-compute 模型,因此,Caffe2 Python op 的开销相对较高. 导致将 GPUs 由 2 增加到 8 时,开销并不成比例减少,如采用 8 GPUs,需要训练 0.9 小时,只比单张 GPU 快了 4.5x 倍.
当采用相对高的 GPU-compute 模型时,multi-GPUs 开销的减少比例会提高.
3. 在Win10 中编译安装PyTorch
知乎文章:关于Windows PRs并入PyTorch的master分支
.......................................
开始编译安装
python setup.py install
目前针对Windows的已修复项:
- 在backward过程中抛出异常会导致死锁 PR 2941
- 在Dataloader开多线程时,会存在内存泄漏 PR 2897
- torch.cuda下的一个缩进bug PR 2941
- 增加对新 CUDA 和 cuDNN 版本的支持 PR 2941
目前Windows的已知问题:
- 部分测试会遇到权限不足问题 PR 3447
- 分布式 torch.distributed 和 多显卡 nccl 不支持
- python 3.5 以下的版本不支持
- 多线程的使用方式与 Unix 不同,对于DataLoader的迭代过程一定要使用如下代码做保护。如遇到多线程下的问题,请先将num_worker设置为0试试是否正常。
if __name__ == '__main__':
另外,大家一定很关心什么时候能出正式Windows正式版,日前,Soumith大神给出了他的回复:
所以这次应该还是见不到正式的Windows版本,但是各位可以期待到时候我的Conda包。
以上,就是文章的全部内容啦,如果感觉还意犹未尽的话,可以给我的Github 主页或者项目加个watch或者star之类的(滑稽),以后说不定还会再分享一些相关的经验。