众所周知,UI自动化测试最痛苦的问题是,前端频繁的调整布局,导致测试人员不断的修改元素定位代码,今天介绍一种较为方便的方式来讲元素层隔离出来,这样以后业务逻辑不变的情况下,前端元素再怎么变动,我们都可以闲庭信步了。
首先介绍一下YAML文件
YAML参考了其他多种语言,包括:XML、C语言、Python、Perl以及电子邮件格式RFC2822。数据结构可以用类似大纲的缩排方式呈现,结构通过缩进来表示,连续的项目通过减号“-”来表示,map结构里面的key/value对用冒号“:”来分隔。
那么我就考虑,将元素定位全部放在YAML中,当程序运行时,将所有的YAML文件加载,这样无论调用什么元素,都可以自由获取了,而当页面元素更改时,只需要更新YAML文件就可以了。
代码结构:我大体分为了 元素层、操作层,将元素定位和业务操作实际隔离,互相不影响,当然,还有通用类及工具类,就不在这里讲述了
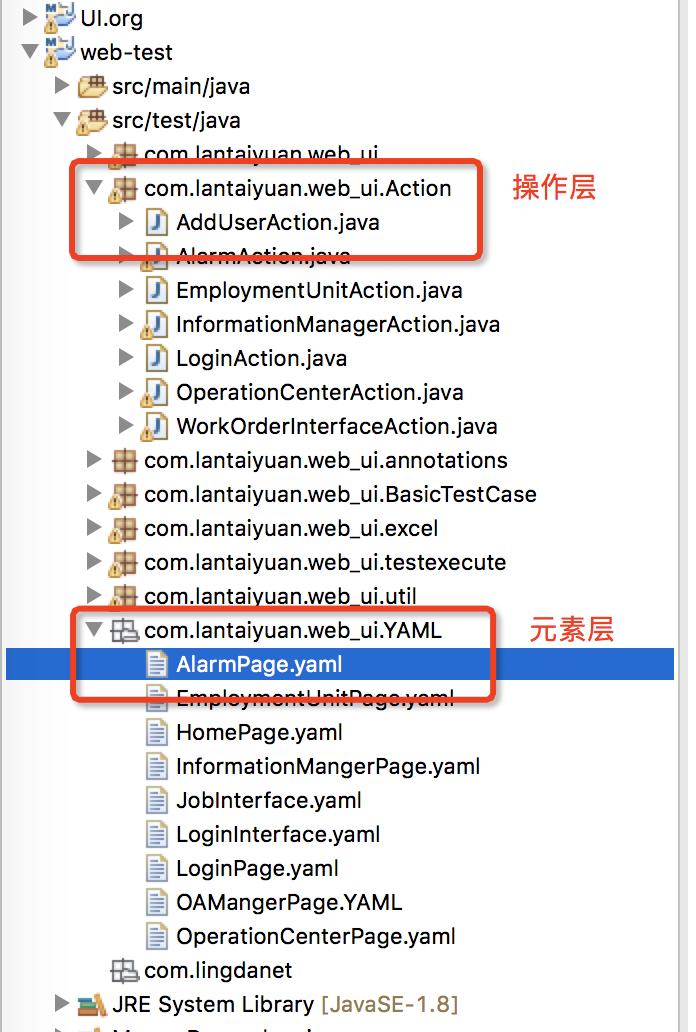
具体讲下,如何调用yaml文件
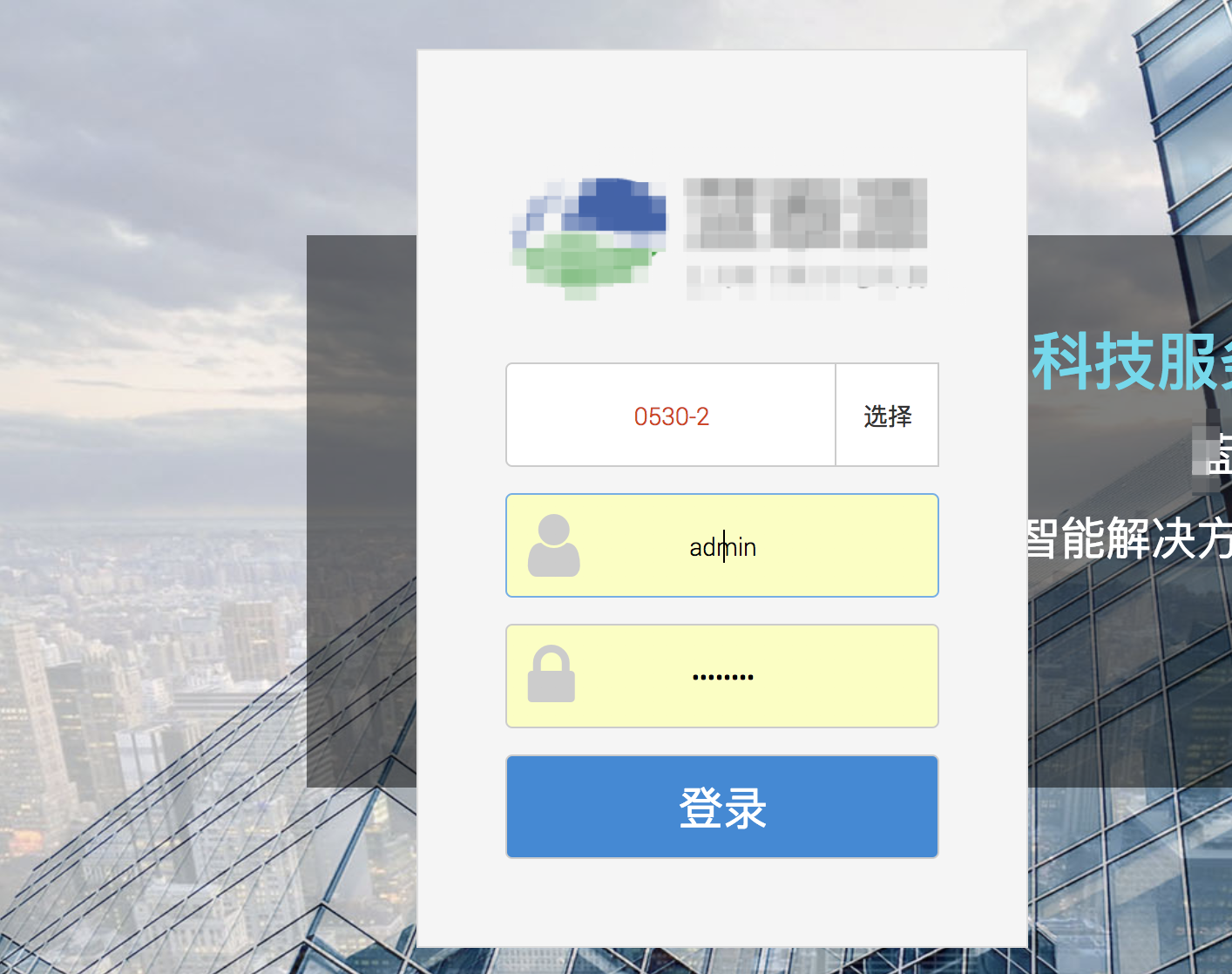
这是登录页面,那么我可以通过yaml文件将元素定义清楚,如下:
登陆主页面:
数据库:
type: xpath
value: html/body/div[1]/div/div[2]/a[1]
用户名输入框:
type: id
value: login
密码输入框:
type: id
value: password
登陆:
type: xpath
value: html/body/div/div[2]/form/button
而我在java代码中,会加载yaml文件,代码如下:
public void getSourceFile(File file) throws Exception {
Map<String, Object> tMap = new HashMap<String, Object>();
FileInputStream fi = new FileInputStream(file.getAbsolutePath());
// 添加到pageMap
try {
tMap = new Yaml().loadAs(fi, HashMap.class);
} catch (Exception e) {
// TODO: handle exception
log.error("配置文件加载错误: " + file.getAbsolutePath());
}
pageMap.putAll(tMap);
}
并且,我们要写入一个判断方法,判断元素定位是用的什么方式,是id、name、还是xpath,如下:
public WebElement getElement(String pageName, String ElementName, WebDriver driver) throws InterruptedException {
By by = null;
Thread.sleep(3000);
try {
String type = (String) ((HashMap) ((HashMap) pageMap.get(pageName)).get(ElementName))
.get(TYPE);
log.info("type=================" + type);
log.info("value=================" + (String) ((HashMap) ((HashMap) pageMap.get(pageName)).get(ElementName))
.get(VALUE));
switch (type) {
case "name":
by = By.name((String) ((HashMap) ((HashMap) pageMap.get(pageName)).get(ElementName))
.get(VALUE));
break;
case "id":
by = By.id((String) ((HashMap) ((HashMap) pageMap.get(pageName)).get(ElementName))
.get(VALUE));
break;
case "xpath":
by = By.xpath((String) ((HashMap) ((HashMap) pageMap.get(pageName))
.get(ElementName)).get(VALUE));
break;
case "className":
by = By.className((String) ((HashMap) ((HashMap) pageMap.get(pageName))
.get(ElementName)).get(VALUE));
break;
case "linkText":
by = By.linkText((String) ((HashMap) ((HashMap) pageMap.get(pageName))
.get(ElementName)).get(VALUE));
break;
default:
break;
}
} catch (NullPointerException e) {
log.info("page中未找到元素");
throw new RuntimeException("page中未找到元素");
}
return (WebElement) driver.findElement(by);
}
完成后,我们的业务执行代码就可以这样写了,是不是很简单:
@Action("登录")
public void login(List<String> parameter) throws Exception{
da.snapshot("登录页面",driver);
yaml.getElement("登陆主页面", "数据库", driver).click();
if(parameter.size()==2){
String username=parameter.get(0).toString();
String pwd=parameter.get(1).toString();
WebElement usercode = yaml.getElement("登陆主页面", "用户名输入框", driver);
usercode.sendKeys(username);
log.info("账号输入成功");
WebElement password = yaml.getElement("登陆主页面", "密码输入框", driver);
password.sendKeys(pwd);
// WebElement code = yaml.getElement("登陆主页面", "验证码", driver);
// code.sendKeys("9527");
}
WebElement login = yaml.getElement("登陆主页面", "登陆", driver);
// System.out.println("login ===========" +
// login.getAttribute("value"));
login.click();
da.snapshot("首页",driver);
}
我们还可以将action(业务逻辑)的执行顺序放入excle中,采用excel驱动的方式,这方面就等我下次介绍吧。