Internet 网络资源非常丰富,几乎涉及到日常生活和研究的各个方面。流行的搜索引擎像Google、百度、雅虎等都能完成快速搜索网络资源的功能。本节我们将学习用C#实现这些功能的基本思路。
在System.Net 命名空间中,有一个WebClient 类,该类提供向URI 标识的任何本地、Intranet或Internet 资源发送数据以及从这些资源接收数据的公共方法。
URI 的意思是统一资源标识符,.NET 框架使用URI 来标识所请求的Internet 资源和通信协议。URI 由四部分组成:协议标识符、服务器标识符、路径标识符和可选的查询字符串。其中协议标识符标识用于请求和响应的通信协议;服务器标识符由域名系统(DNS)主机名或TCP 地址组成,用于惟一标识Internet 上的服务器;路径标识符用于在服务器上定位请求的信息;查询字符串用于将信息从客户端传送到服务器。
例如,“http://www.contoso.com/whatsnew.aspx?date=today”就是由协议标识符“http”、服务器标识符“www.contoso.com”、路径“whatsnew.aspx”和查询字符串“?date=today”组成的。服务器接收到请求并对响应进行了处理之后,就将该响应返回到客户端应用程序。由于响应中包括了像原始文本或XML 数据等相关信息,因此我们就可以从这些信息中查询需要的文本字符串、图片等内容。
通过WebClient 类从Web 站点下载文件有两种方式,一种是直接保存为本地文件,另一种是通过流进行读取,具体采用哪种方式要视情况而定。
如果要保存成本地文件,可以使用DownloadFile 方法。该方法有两个参数,一个是URI,即统一资源标识符;另一个是本地保存路径。例如:
using System.Net; …… WebClient myWebClient = new WebClient(); myWebClient.DownloadFile("http://military.china.com/zh_cn/", "C:\test.htm");
如果应用程序需要处理从Web 站点检索到的数据,可以使用OpenRead 方法,这个方法返回一个Stream 引用。然后就可以从数据流中读取数据了。例如:
using System.Net; using System.IO; …… WebClient webClient = new WebClient(); Stream myStream = webClient.OpenRead("http://news.sohu.com"); StreamReader sr = new StreamReader(myStream); string httpSource = sr.ReadToEnd();
也可以使用DownloadString 方法,直接读取包含网页源代码的字符串内容。例如:
using System.Net; …… WebClient webClient = new WebClient(); string httpSource = webClient.DownloadString("http://news.sohu.com");
这种方法得到的结果与使用流读取得到的结果相同。
【例】设计一个简单的搜索程序,能读取指定网址的源文件,并能用正则表达式搜索包含的超链接与图片。
(1) 新建一个名为InternetSearchExample 的Windows 应用程序,修改Form1.cs 为FormSearch.cs,设计如图7-4 所示的界面。
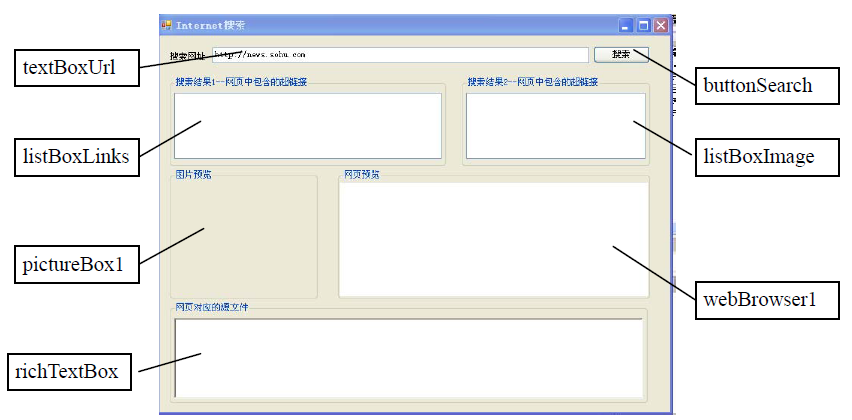
(2) 切换到代码方式,添加对应的命名空间引用和事件,源代码如下:
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Text; using System.Windows.Forms; //添加的命名空间引用 using System.Net; using System.IO; using System.Text.RegularExpressions; namespace InternetSearchExample { public partial class FormSearch : Form { public FormSearch() { InitializeComponent(); } private void buttonSearch_Click(object sender, EventArgs e) { listBoxLinks.Items.Clear(); listBoxImage.Items.Clear(); pictureBox1.Image = null; webBrowser1.Url = new Uri("about:blank"); richTextBox1.Clear(); string urlString = textBoxUrl.Text.Trim(); if (urlString.StartsWith("http://") == false) { urlString = "http://" + urlString; textBoxUrl.Text = urlString; } string httpSource; try { //设置鼠标形状为沙漏形状 Cursor.Current = Cursors.WaitCursor; WebClient webClient = new WebClient(); //获取包含网页源代码的字符串。 httpSource = webClient.DownloadString(textBoxUrl.Text); richTextBox1.Text = httpSource; webBrowser1.Url = new Uri(textBoxUrl.Text); } catch (Exception err) { MessageBox.Show(err.Message); return; } finally { //设置鼠标形状为默认形状 Cursor.Current = Cursors.Default; } string regexHrefPattern = @"<as+hrefs*=s*""?([^"" >]+)""?>(.+)</a>"; Regex myRegex = new Regex(regexHrefPattern, RegexOptions.IgnoreCase); Match myMatch = myRegex.Match(httpSource); while (myMatch.Success == true) { listBoxLinks.Items.Add(myMatch.Groups[0].Value); myMatch = myMatch.NextMatch(); } string regexImgPattern = @"<img[^>]+(src)s*=s*""?([^ "">]+)""?(?:[^>]+([^"">]+)""?)?"; myRegex = new Regex(regexImgPattern, RegexOptions.IgnoreCase); myMatch = myRegex.Match(httpSource); while (myMatch.Success == true) { listBoxImage.Items.Add(myMatch.Groups[2].Value); myMatch = myMatch.NextMatch(); } } private void listBoxImage_Click(object sender, EventArgs e) { try { WebClient client = new WebClient(); pictureBox1.Image = Image.FromStream(client.OpenRead(listBoxImage.SelectedItem.ToString())); } catch { pictureBox1.Image = null; } } } }
(3) 按<F5>键编译并运行,输入某个网址,例如http://news.sohu.com,然后单击【开始搜索】按钮,观察搜索结果。单击搜索结果2 中的图片链接,即可显示对应的图片。运行效果如图所示。
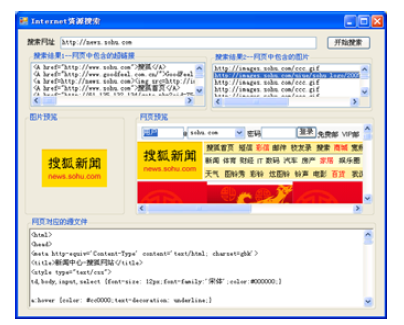
当然,实际应用中的搜索引擎远比这个例子复杂得多。但是,通过这个例子,我们学习了利用C#和正则表达式编写搜索网络资源程序的基本思想。在此基础上,编写与此相关的更广泛的网络应用程序就不会感到太困难了。