一、开始
1.1 keepalived HA模式
keepalived的HA分为抢占模式和非抢占模式,抢占模式即MASTER从故障中恢复后,会将VIP从BACKUP节点中抢占过来。非抢占模式即MASTER恢复后不抢占BACKUP升级为MASTER后的VIP。本例主要介绍抢占模式。
1.2 方案规划
|
virtual_server(vip) |
real_server(ip) |
MASTER/BACKUP |
服务端 |
|
192.168.177.100 |
192.168.177.181 |
MASTER |
192.168.176 |
|
192.168.177.100 |
192.168.177.191 |
BACKUP |
192.168.167 |
分别在两台real_server安装keepalived和nginx,通过keepalive保证nginx的高可用。请求流程如下:客户端发起请求到vip,如果master存活,就通过master的nginx负载分发到服务端;如果master节点挂掉,则keepalived会将vip漂移到backup,此时backup的nginx会将请求负载分发到服务端。如果master完成了故障处理,恢复服务,那么会将vip抢占回来,而客户端无需关心具体是那一台nginx server对请求进行了分发,实现对服务器的解耦(本例nginx负载均衡策略为最少连接)。
1.3 环境介绍
服务器版本:CentOS Linux release 7.6.1810 (Core)
keepalived版本:keepalived-1.3.5-16.el7.x86_64
nginx版本:nginx-1.18.0-1.el7.ngx.x86_64
1.4 环境准备
1.4.1 防火墙
防火墙添加arrp组播规则,或关闭防火墙。本例关闭防火墙:
# 查看防火墙状态 firewall-cmd --state # 停止firewall systemctl stop firewalld.service # 禁止firewall开机启动 systemctl disable firewalld.service
1.4.2 关闭selinux
如果没有关闭可能会导致keepalived.server或nginx.service启动失败。将SELINUX= enforcing改为SELINUX=disabled。
vi /etc/sysconfig/selinux
SELINUX=disabled
1.5 安装Nginx(有网络)
1.5.1 配置yum存储库
1>创建文件
vi /etc/yum.repos.d/nginx.repo
2>插入如下信息(指定下载地址,本机系统及系统版本)
[nginx] name=nginx repo baseurl=http://nginx.org/packages/centos/7/$basearch/ gpgcheck=0 enabled=1
1.5.2 下载安装
yum install nginx -y
1.5.3 查看安装的nginx版本
nginx -v
1.6安装Keepalived
1.6.1 下载安装
yum install keepalived -y
1.7.2 启动并设置开机自启
systemctl start keepalived.service
systemctl enable keepalived.service
二、修改配置
2.1 keepalived配置
2.11 编辑/etc/keepalived/keepalived.conf配置文件
1> MASTER(192.168.177.181):
! Configuration File for keepalived global_defs { notification_email { # 邮件通知 root@localhost } # 指定发件人 notification_email_from Alexandre.Cassen@firewall.loc # 指定smtp服务器地址 smtp_server 127.0.0.1 # 指定smtp连接超时时间 smtp_connect_timeout 30 # 此处注意router_id为负载均衡标识,在局域网内应该是唯一的,通常为hostname router_id LVS_DEVEL_181 } # keepalived会定时执行脚本并对脚本执行的结果进行分析,动态调整vrrp_instance的优先级。 # 如果脚本执行结果为0,并且weight配置的值大于0,则优先级相应的增加。如果脚本执行结果非0, # 并且weight配置的值小于 0,则优先级相应的减少。其他情况,维持原本配置的优先级,即配置文件中priority对应的值。 vrrp_script chk_nginx { script "/etc/keepalived/nginx_check.sh" # 每2秒检测一次nginx的运行状态 interval 2 # 失败一次,将自己的优先级-20 weight -20 } # 虚拟路由的标识符 vrrp_instance VI_1 { # 状态只有MASTER和BACKUP两种,并且要大写,MASTER为工作状态,BACKUP是备用状态 state MASTER # 通信所使用的网络接口,可用ifconfig查看 interface ens32 # 虚拟路由的ID号,是虚拟路由MAC的最后一位地址 virtual_router_id 51 # 指定发送组播数据包的源IP地址。默认是绑定VRRP实例的接口的主IP地址 mcast_src_ip 192.168.177.181 # 此节点的优先级,主节点的优先级需要比其他节点高 priority 100 # 通告的间隔时间 advert_int 1 # 认证配置 authentication { # 认证方式 auth_type PASS # 认证密码 auth_pass 1111 } # 虚拟IP,两个节点设置必须一样。可以设置多个,一行写一个 # 虚拟ip地址,可以有多个地址,每个地址占一行,不需要子网掩码,同时这个ip 必须与我们在lvs 客户端设定的vip 相一致! virtual_ipaddress { 192.168.177.100 } track_script { # nginx存活状态检测脚本 chk_nginx } } # 集群所使用的VIP和端口 virtual_server 192.168.177.100 443 { # 健康检查间隔,单位为秒 delay_loop 6 # lvs调度算法rr|wrr|lc|wlc|lblc|sh|dh lb_algo rr # 负载均衡转发规则。一般包括DR,NAT,TUN 3种 lb_kind NAT # 会话保持时间,会话保持,就是把用户请求转发给同一个服务器,不然刚在1上提交完帐号密码,就跳转到另一台服务器2上了 persistence_timeout 50 # 转发协议,有TCP和UDP两种,一般用TCP protocol TCP # 真实服务器,包括IP和端口号 real_server 192.168.177.181 443 { # 默认为1,0为失效 weight 1 # 通过tcpcheck判断RealServer的健康状态 TCP_CHECK { # 连接超时时间 connect_timeout 3 # 重连次数 nb_get_retry 3 # 重连间隔时间 delay_before_retry 3 # 健康检查的端口 connect_port 23 } } }
2> BACKUP(192.168.177.191)
global_defs { # 此处注意router_id为负载均衡标识,在局域网内应该是唯一的 router_id LVS_DEVEL_191 } vrrp_script chk_nginx { script "/etc/keepalived/nginx_check.sh" interval 2 weight -20 } vrrp_instance VI_1 { # 与master不同,备份节点为BACKUP state BACKUP # 根据实际配置 ifconfig查看 interface ens33 virtual_router_id 51 # 备,本机ip mcast_src_ip 192.168.177.191 priority 90 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { # VIP 要同master 一致 192.168.177.100 } track_script { chk_nginx } } virtual_server 192.168.177.100 443 { delay_loop 6 lb_algo rr lb_kind NAT persistence_timeout 50 protocol TCP # 真实服务器,包括IP和端口号 real_server 192.168.177.191 443 { weight 1 TCP_CHECK { connect_timeout 3 nb_get_retry 3 delay_before_retry 3 connect_port 23 } } }
2.1.2 创建nginx服务检测脚本
分别在主、备服务器/etc/keepalived目录下创建nginx_check.sh脚本,并为其添加执行权限chmod +x /etc/keepalived/nginx_check.sh。用于keepalived定时检测nginx的服务状态,如果nginx停止了,会尝试重新启动nginx,如果启动失败,会将keepalived进程杀死,将vip漂移到备份机器上。
#!/bin/bash #监测心跳脚本 #查看nginx是否启动,如果没启动则启动,如果启动不起来,停掉keepalived服务,此时心跳断掉,服务转向另一个nginx counter=$(ps -C nginx --no-heading|wc -l) echo "${counter}" if [ "${counter}" = "0" ]; then echo "即将启动nginx" service nginx start ##/usr/sbin/nginx #尝试重新启动nginx sleep 2 #睡眠2秒 counter=$(ps -C nginx --no-heading|wc -l) if [ "${counter}" = "0" ]; then service keepalived stop # killall keepalived #启动失败,将keepalived服务杀死。将vip漂移到其它备份节点 echo "nginx启动失败,将vip漂移到其它备份节点" else echo "nginx启动成功" fi fi
2.1.3 启动keepalived服务
service keepalived start
查看keepalived是否启动成功
ps -ef | grep keepalived
查看nginx是否启动成功(如果启动失败检查nginx检测脚本,或keepalived配置文件中的检测脚本路径是否正确,检查是否多了或少了花括号)
ps -ef | grep nginx
如果看到如下进程信息,表示keepalived已经启动成功:
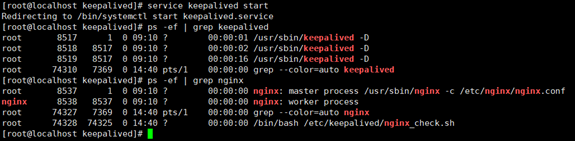
下面用ip add命令查看vip绑定的情况,如下图所示:
ip addr

从上图可以看出,vip地址192.168.177.100绑定在MASTER(192.168.177.181)的ens32网卡上。
2.1.4 测试故障转移
将MASTER(192.168.177.181)上的keepalived停止,查看vip是否会漂移到192.168.177.191上。
service keepalived stop
ip addr
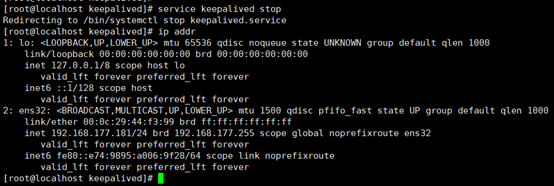
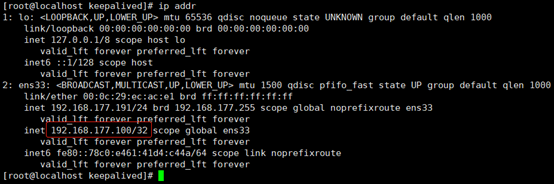
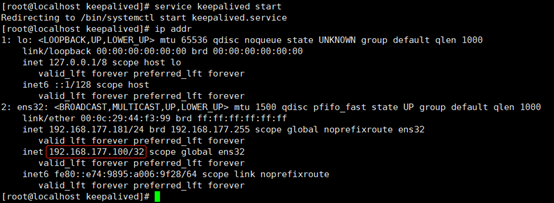
从上图可以看出,vip已经成功从181漂移到了191。此时再将181的keepalived服务启动,由于181是MASTER,所以会将191的VIP抢占过来。
启动181的keepalived服务:
service keepalived start
2.2 nginx配置
2.1.1 nginx.conf
使用安装默认配置,不做任何修改。
user nginx; worker_processes 1; error_log /var/log/nginx/error.log warn; pid /var/run/nginx.pid; events { worker_connections 1024; } http { include /etc/nginx/mime.types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; #tcp_nopush on; keepalive_timeout 65; #gzip on; # 指定自定义配置文件目录、名称(esb.conf生效的原因) include /etc/nginx/conf.d/*.conf; }
2.1.2 my.conf
分别在主、备服务器/etc/nginx/conf.d目录下新增my.conf
upstream my10016 { least_conn; #最少连接 server 192.168.177.167:10016; server 192.168.177.176:10016; } server { listen 10016; server_name 192.168.177.100;# 监听ip使用vip location / { proxy_pass http://my10016; # 设置代理 index index.html index.htm; } }
三、负载均衡测试
可自行测试
PostMan调用http://192.168.177.100:10016/aaa接口
{"msg":"success","status":"1","server_ip":"192.168.177.176"}
{"msg":"success","status":"1","server_ip":"192.168.177.167"}
四、nginx容错
4.1 nginx http健康检查
Nginx健康检查分为主动健康检查和被动健康检查,本例主要介绍被动健康检查(主动健康检查参考官方文档:https://docs.nginx.com/nginx/admin-guide/load-balancer/http-health-check/#active-health-checks)。对于被动运行状况检查,NGINX会监视事务的发生,并尝试恢复失败的连接。如果仍然无法恢复交易,则NGINX将服务器标记为不可用,并暂时停止向服务器发送请求,直到再次将其标记为活动。
upstream my10016 { #负载均衡策略,最少连接,默认为轮询 #least_conn; # 被动健康检查 # 如果NGINX无法在30秒内向服务器发送请求或没有收到3次响应,则会将服务器标记为30秒不可用 # 如果只有一个单一的服务器组中,将fail_timeout和max_fails参数被忽略,服务器永远不会标记为不可用 # 意思是在fail_timeout时间内失败了max_fails次请求后,则认为该上游服务器不可用,然后将该服务地址踢除掉。fail_timeout时间后会再次将该服务器加入存活列表,进行重试。 server 192.168.177.167:10016 fail_timeout=30s max_fails=3; server 192.168.177.176:10016 fail_timeout=30s max_fails=3; }
4.2重试机制
proxy_next_upstream error | timeout | invalid_header | http_500 | http_502 | http_503 | http_504 | http_403 | http_404 | http_429 | non_idempotent | off ...;
Default: proxy_next_upstream error timeout;
Context: http, server, location
指定应将请求传递到下一个服务器的情况:
error # 与服务器建立连接,向其传递请求或读取响应头时发生错误;
timeout # 在与服务器建立连接,向其传递请求或读取响应头时发生超时;
invalid_header # 服务器返回空的或无效的响应;
http_500 # 服务器返回代码为500的响应;
http_502 # 服务器返回代码为502的响应;
http_503 # 服务器返回代码为503的响应;
http_504 # 服务器返回代码504的响应;
http_403 # 服务器返回代码为403的响应;
http_404 # 服务器返回代码为404的响应;
http_429 # 服务器返回代码为429的响应(1.11.13);
non_idempotent # 通常,请求与 非幂等 方法(POST,LOCK,PATCH)不传递到请求是否已被发送到上游服务器(1.9.13)的下一个服务器; 启用此选项显式允许重试此类请求;
off # 禁用将请求传递给下一个服务器。
proxy_next_upsstream_tries 0表示不限次数
完整示例如下:
upstream my10016 { #负载均衡策略,最少连接,默认为轮询 #least_conn; # 被动健康检查 # 如果NGINX无法在30秒内向服务器发送请求或没有收到3次响应,则会将服务器标记为30秒不可用 # 如果只有一个单一的服务器组中,将fail_timeout和max_fails参数被忽略,服务器永远不会标记为不可用 # 意思是在fail_timeout时间内失败了max_fails次请求后,则认为该上游服务器不可用,然后将该服务地址踢除掉。fail_timeout时间后会再次将该服务器加入存活列表,进行重试。 server 192.168.177.167:10016 fail_timeout=30s max_fails=3; server 192.168.177.176:10016 fail_timeout=30s max_fails=3; } server { listen 10016; # 监听vips server_name 192.168.177.100; location / { # 定义了什么情况下进行重试,此处error,timeout,http_500 # non_idempotent 允许非幂等请求重试 # post, lock, patch 这种会对服务器造成不幂等的方法,默认是不进行重试的,如果一定要进行重试,则要加上这个配置 proxy_next_upstream error timeout http_500 non_idempotent; # 读取超时时间,默认值60s,此处10s # proxy_read_timeout 10s; # 连接超时时间 proxy_connect_timeout 3s; # 6s后nginx 重试 proxy_next_upstream_timeout 6s; # 重试次数,注意:此机制可能会导致数据重复插入的情况 # 参考:https://www.cnblogs.com/lc0605/p/10444086.html proxy_next_upstream_tries 3; proxy_pass http://my10016; # 设置代理 ndex index.html index.htm; } }