项目中使用YOLO系列已经大半年,是时候总结下原理了。
事实上YOLO3已经是成熟可靠的目标检测框架,具有很好的商业价值;而YOLO4&5是将近年来DL领域一些创新、可靠、有效的tricks加进去,进一步提升了YOLO的效果,江湖传言曰:嫁衣神功。

YOLOV4的数据增强只会增加训练成本,得到鲁棒性更强的网络模型;而不会影响推理阶段性能。
一、MixUp混合
如上图MixUp[48]的效果图,是将Dog图和Cat作了线性叠加,权重各取0.5。
二、Cutout随机裁剪
如上图Cutout[3]的效果图,随机遮挡目标狗的头部、尾巴,脚等部位。
(注:dropblock是一种剪枝方式,这种方式其实是借鉴2017年的cutout数据增强的方式,cutout是将输入图像的部分区域清零,而Dropblock则是将Cutout应用到每一个特征图。而且并不是用固定的归零比率,而是在训练时以一个小的比率开始,随着训练过程线性的增加这个比率。)
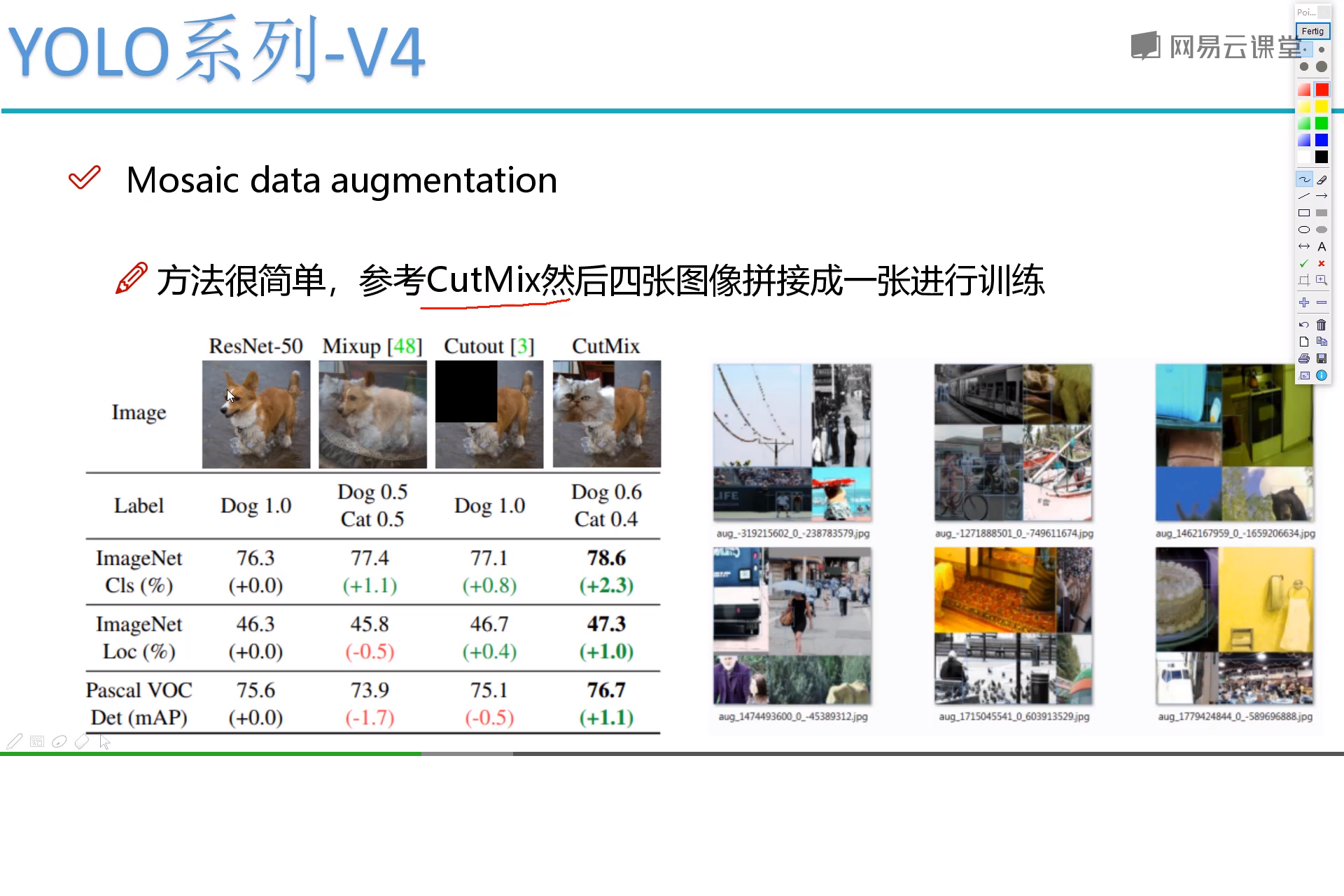
三、CutMix随机遮挡
CutMix = CutUp + CutOut,单词组合。
如上图CutMix的效果图,将其他类别的图像块剪切到当前图像,进行遮挡干扰,达到数据增强效果。注意标签的定义,表示当前目标:是Dog置信度为0.6,是Cat置信度为0.4。这个置信度是SoftMax函数输出的值,取值范围[0,1],可输出当前目标属于每个类别的概率;扯远了。
还有其他的旋转、反转、亮度、色调、对比度增强就不提了,比较简单。YOLOV4&5有一个重要的数据增强,叫做:马赛克增强。
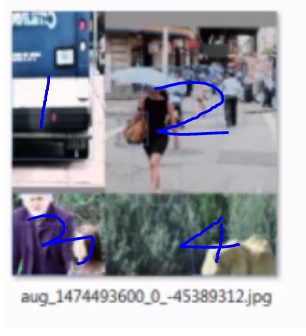
四、Mosaic马赛克增强
这种数据增强算法是YOLOV5的作者提出,据说V5作者曾公开发表言论:YOLOV4之所以有很好的效果,很大程度上归功于马赛克增强。
训练的时候,我们知道,batchsize大小设置是和显存大小有关,例如:batchsize=1,表示一张图,这里Mosaic增强有四张图,如下图,将四张图象合成一张图像训练,在GPU资源有限的情况下,一次batchsize处理的图片越多越好。当然,下面这四张图,还是常规增强、标注。四张图混在一起,增加了图像背景复杂度,亦是增强。马赛克增强是使得YOLOV4对平明用户很友好(我自己的RTX2060就能训练)。
五、Random Erase
用随机值或者训练集的平均像素值替换图像的区域。如图,左边一列都是原图,右边三列是增强后效果图。

六、Hide and Seek
根据概率随机隐藏一些补丁块。如图在图像上设置随机补丁。

七、随机噪声
在此之前,先说明下YOLOV4的SAT技术,即:添加随机噪声,如下图,中间是自动生成的随机噪声矩阵,乘一个系数0.07,将其线性叠加到原图上,这也是一种数据增强。Self-adversarial-training(SAT)。对抗训练(adversarial training)是增强神经网络鲁棒性的重要方式。在对抗训练的过程中,样本会被混合一些微小的扰动(改变很小,但是很可能造成误分类),然后使神经网络适应这种改变,从而对对抗样本具有鲁棒性。

以上所提及的数据增强,马赛克增强是YOLOV4&5的亮点,其他方法也是集“百家之长于一身”。
reference:对抗训练:
https://zhuanlan.zhihu.com/p/104040055