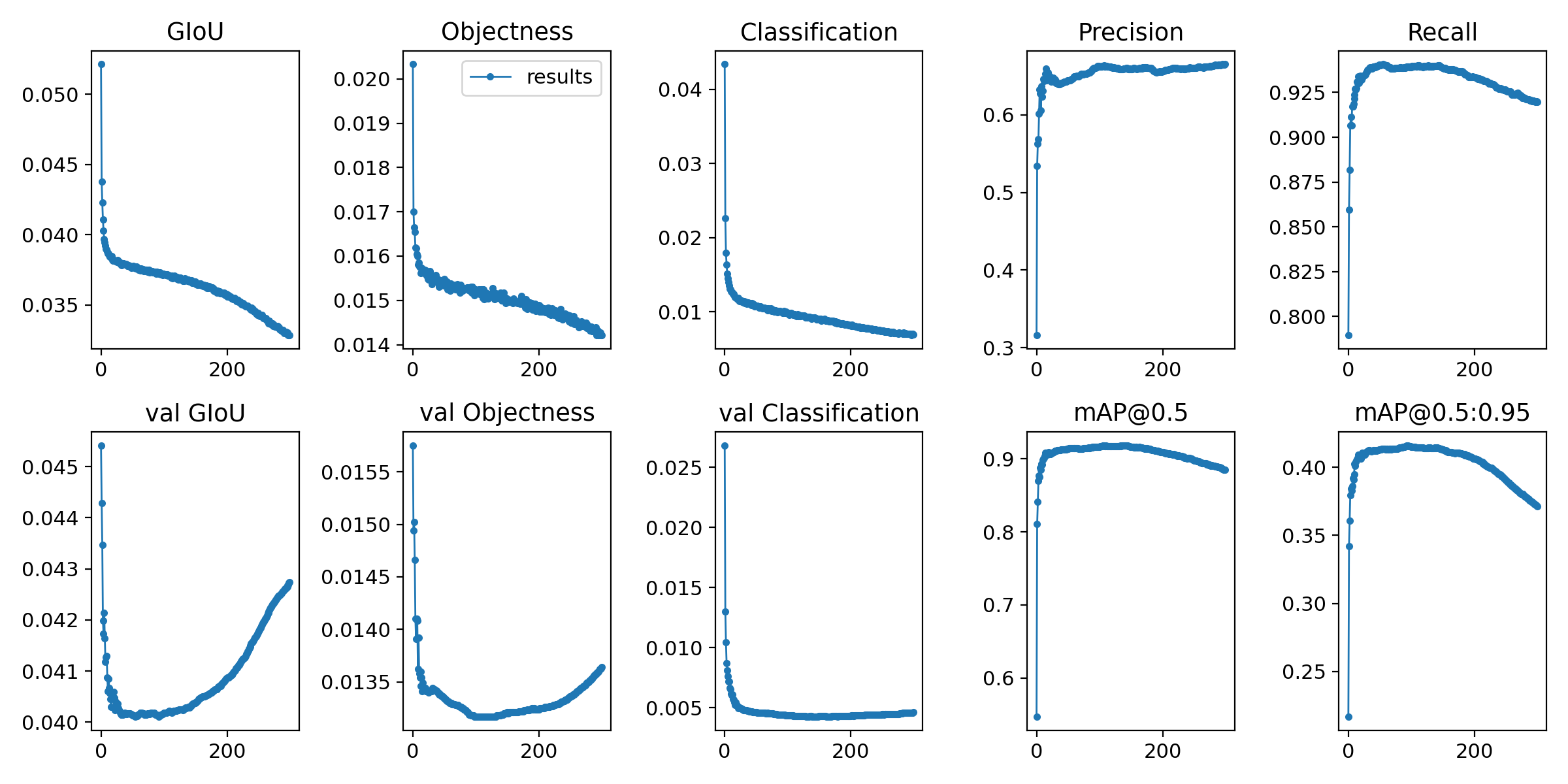
经过5天5夜的训练,终于在昨晚训练完毕,以下是训练结果:
python train.py --batch 16 --epochs 300 --data ../Dataset/Digitls/data.yaml --cfg models/yolov5s.yaml --weights yolov5s.pt --workers 0
这下,咱们可以去国内竞技场“拳打南山敬老院,脚踩北海幼儿园!”哈哈哈
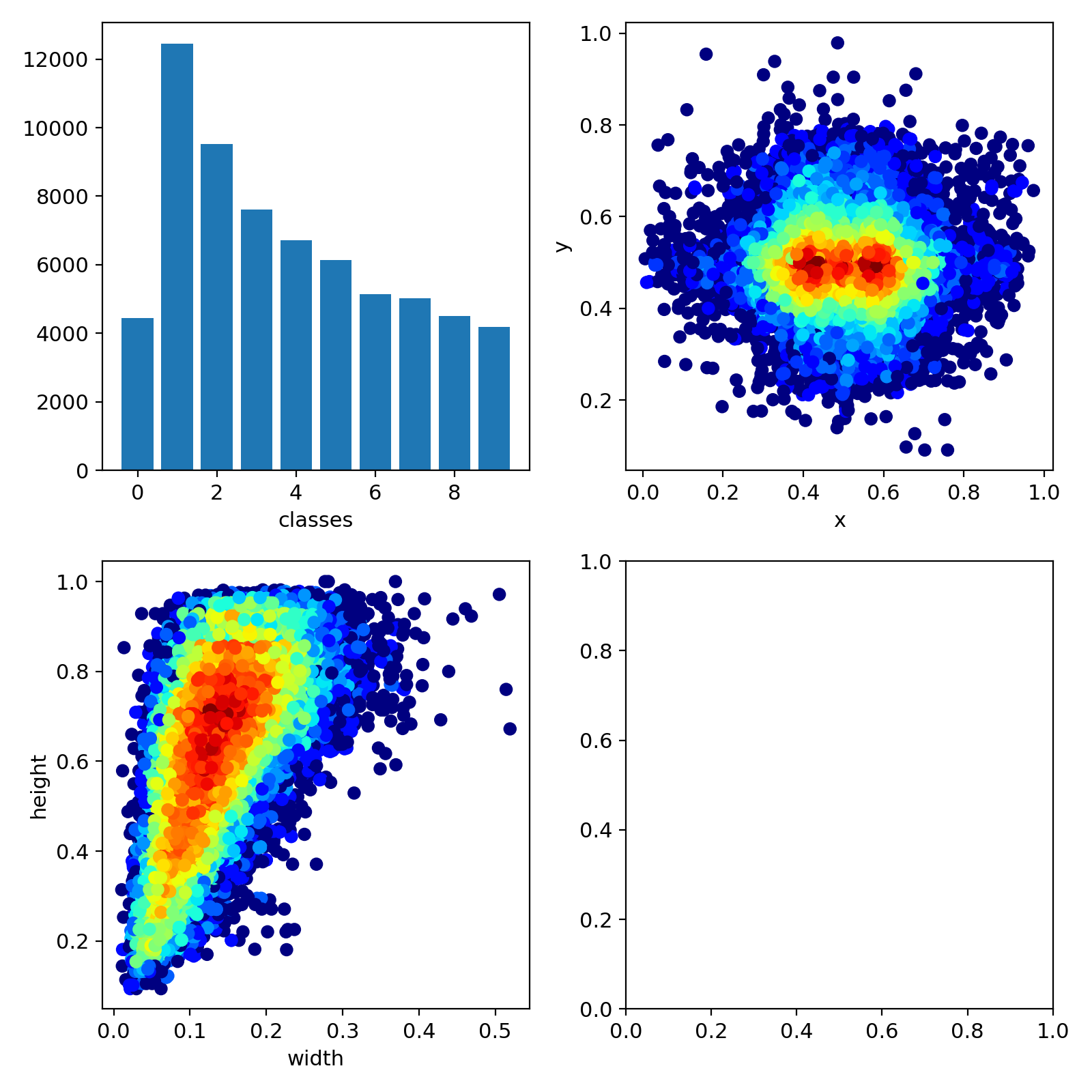
下次训练,为充分利用GPU资源,请教显示器DP线插入主板后面,使用CPU集显显示win10图形界面,让GPU专注于CUDA加速。

结果测试:
我们在detect.py主函数前面设置命令行参数
1 opt.source = '../Kaggle1/mchar_test_a/mchar_test_a' 2 # opt.source = '1' 3 opt.weights = 'best.pt' 4 opt.output = 'Result' # 效果图保存文件夹
测试的结果保存到了工程目录下的Result文件夹

这个文件夹中,其实只有39898个文件,而测试文件有40000个,表明有些样本图被漏检了。但是提交结果要求你给出这40000张图的测试结果,
所以对于漏检的,需要表示出来。这里使用GetFileList.bat脚本生成结果文件路径,方便批量读取每一张图测试结果。
fileList.txt:
1 F:yolov5-0826Result�00000.txt 2 F:yolov5-0826Result�00001.txt 3 F:yolov5-0826Result�00002.txt 4 F:yolov5-0826Result�00003.txt 5 F:yolov5-0826Result�00004.txt 6 F:yolov5-0826Result�00005.txt 7 F:yolov5-0826Result�00006.txt 8 F:yolov5-0826Result�00007.txt 9 F:yolov5-0826Result�00008.txt 10 F:yolov5-0826Result�00009.txt 11 F:yolov5-0826Result�00010.txt
......
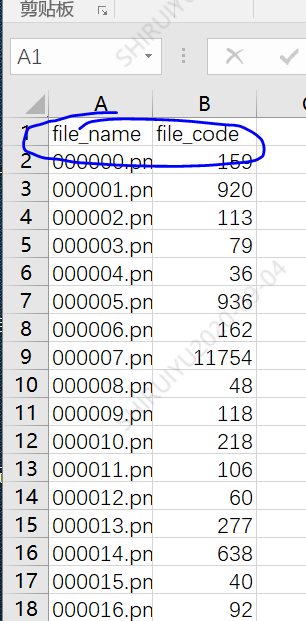
下面编写生成40000张图测试结果的csv文件,csv文件大概内容如图:
1 import pandas as pd 2 3 # 构建一个 size = 40000的list,每个元素是文件名 4 # 下面遍历文件名,如果找到漏检那就写入"0123" 5 6 total_file_name_list = [] 7 8 for i in range(40000): 9 six_zeros = "000000" 10 six_zeros += str(i) 11 total_file_name_list.append(six_zeros[-6:]) 12 # print(six_zeros[-6:]) 13 14 file = open("F:yolov5-0826\Result\fileList.txt", "r") 15 file_lines = file.readlines() 16 17 test_label_pred = [] # list 所有预测值 18 19 j = 0 20 21 for file_line in file_lines: 22 # 获取每一个标签的路径 23 file_line_ = file_line.replace(' ', '') 24 # print("file_line_ = ", file_line_) 25 26 # 读取标签信息 27 file_label = open(file_line_, "r") 28 file_label_lines = file_label.readlines() 29 30 # sample 31 img_name = file_line_[22:28] # get name of file index, eg:000000 32 33 # 死循环,循环结束条件:找到与img_name相等的文件名 34 while total_file_name_list[j] != img_name: 35 test_label_pred.append("0123") 36 j = j + 1 37 38 # 安矩形框顶点x坐标进行排序 39 # ['1 0.95625 0.510204 0.1375 0.612245 ', 40 # '5 0.375 0.479592 0.175 0.632653 ', 41 # '9 0.54375 0.469388 0.1875 0.653061 '] 42 file_label_lines.sort(key=lambda file_label_lines: file_label_lines[2:9]) 43 print(file_label_lines) 44 45 # label 46 predict_val = "" 47 for file_label_line in file_label_lines: 48 predict_val += file_label_line[0] # 0 - 9 49 50 test_label_pred.append(predict_val) 51 j = j + 1 52 print('-----------------') 53 54 file.close() 55 56 # save to csv 57 # note:需要提前准备好文件,这里保存操作其实就是修改其中内容 58 df_submit = pd.read_csv('mchar_sample_submit_A.csv') 59 df_submit['file_code'] = test_label_pred 60 df_submit.to_csv('submit.csv', index=None) 61 62 print("over")
阿里天池提交文件问题:例如一张图中,从左到右出现字符顺序是 “019”,那么你提交的顺序也必须是019,不能是诸如910,901,091之类的,否则断定你预测为错误的。
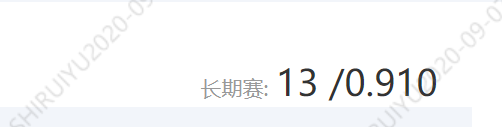
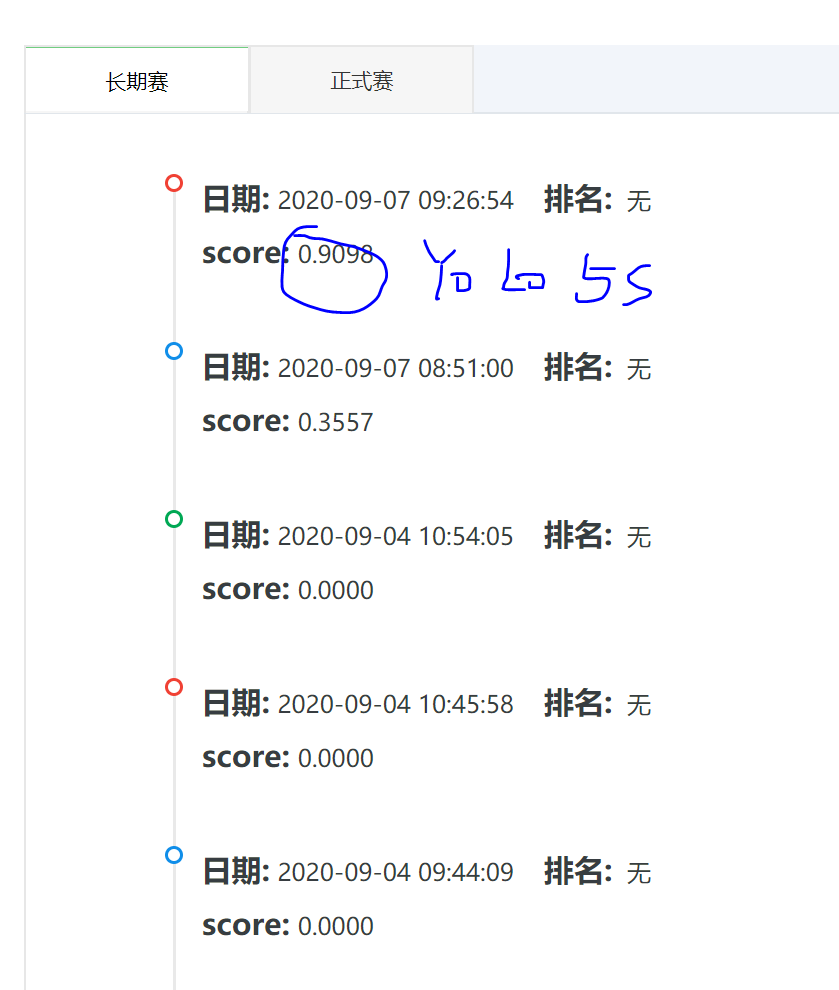
当前排名13名,好了,稍后使用AI加速卡训练yolo5x模型试一试。