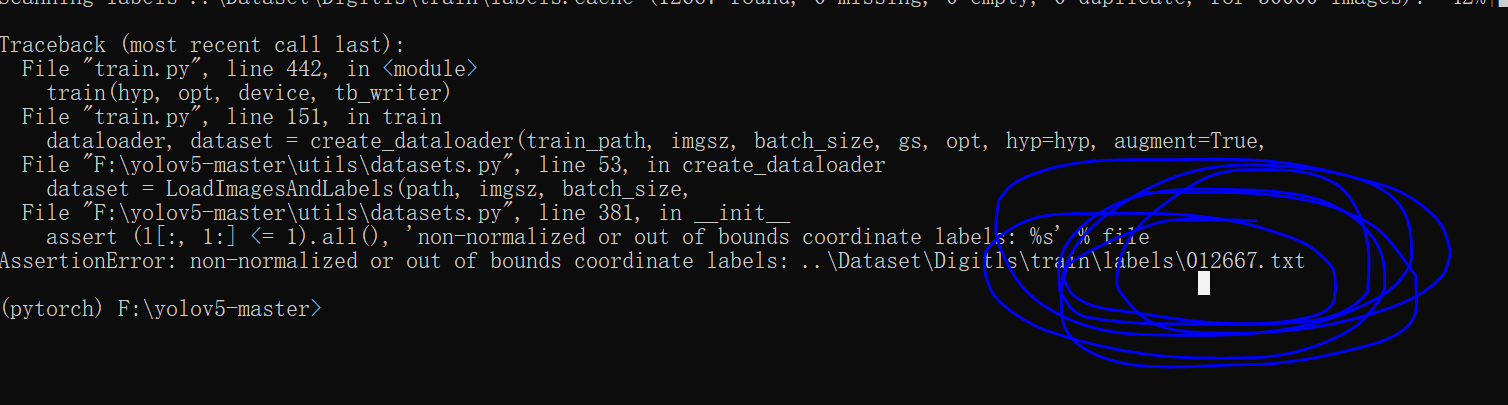

上图标签信息出错,越界了,具体地:ROI高度居然比图像高度还要大,显然不合理
训练数据:从resnet18转为适用于yolo系列的功能代码,文件名:TrainLabelToYOLOV5.py
1 import os, sys, glob, shutil, json 2 import cv2 3 4 train_json = json.load(open('mchar_train.json')) 5 # train_label = [train_json[x]['label'] for x in train_json] 6 7 train_files_path = "F:\Dataset\SVHN\aliyunDataset\mchar_train\mchar_train\" 8 9 i = 0 10 for key, value in train_json.items(): 11 i = i + 1 12 if i < 12668: 13 continue 14 # print("label: ", key) 15 # print("height: ", value) 16 file_name = key 17 18 image = cv2.imread(train_files_path + file_name, -1) 19 image_height = image.shape[0] 20 image_width = image.shape[1] 21 22 # print(image_width, image_height) 23 24 # 获取每个字典的标签信息 25 label_info = value 26 label_class = label_info['label'] 27 xs_top_left = label_info['left'] 28 ys_top_left = label_info['top'] 29 roi_height = label_info['height'] 30 roi_width = label_info['width'] 31 32 print(label_class, xs_top_left, ys_top_left, roi_height, roi_width) 33 34 file_name_ = file_name[0:6] # 去掉后缀 35 f = open("trainData\" + file_name_ + ".txt", "w") 36 37 # process the label of one image 38 for k in range(len(label_class)): 39 label_class_ = label_class[k] 40 # x_center / image_width 41 cx_normal = (xs_top_left[k] + roi_width[k] / 2) / image_width 42 # y_center/image_height 43 cy_normal = (ys_top_left[k] + roi_height[k] / 2) / image_height 44 # width/image_width 45 width_normal = roi_width[k] / image_width 46 # height/image_height 47 height_normal = roi_height[k] / image_height 48 49 # 写入文件 50 f.writelines(str(label_class_) + str(' ') + 51 str(cx_normal) + str(' ') + 52 str(cy_normal) + str(' ') + 53 str(width_normal) + str(' ') + 54 str(height_normal) + str(' ') + ' ') 55 f.close() 56 57 58 print('')
验证数据 ,文件名 ValLabelToYOLOV5.py
1 import os, sys, glob, shutil, json 2 3 os.environ["CUDA_VISIBLE_DEVICES"] = '0' 4 import cv2 5 from PIL import Image 6 import numpy as np 7 from tqdm import tqdm, tqdm_notebook 8 import torch 9 10 torch.manual_seed(0) 11 torch.backends.cudnn.deterministic = False 12 torch.backends.cudnn.benchmark = True 13 import torchvision.models as models 14 import torchvision.transforms as transforms 15 import torchvision.datasets as datasets 16 import torch.nn as nn 17 import torch.nn.functional as F 18 import torch.optim as optim 19 from torch.autograd import Variable 20 from torch.utils.data.dataset import Dataset 21 22 val_json = json.load(open('mchar_val.json')) 23 24 val_files_path = "F:\Dataset\SVHN\aliyunDataset\mchar_val\mchar_val\" 25 26 i = 0 27 for key, value in val_json.items(): 28 # print("label: ", key) 29 # print("height: ", value) 30 file_name = key 31 32 image = cv2.imread(val_files_path + file_name, -1) 33 image_height = image.shape[0] 34 image_width = image.shape[1] 35 36 # print(image_width, image_height) 37 38 # 获取每个字典的标签信息 39 label_info = value 40 label_class = label_info['label'] 41 xs_top_left = label_info['left'] 42 ys_top_left = label_info['top'] 43 roi_height = label_info['height'] 44 roi_width = label_info['width'] 45 46 # print(label_class, xs_top_left, ys_top_left, roi_height, roi_width) 47 48 file_name_ = file_name[0:6] # 去掉后缀 49 f = open("valData\" + file_name_ + ".txt", "w") 50 51 # process the label of one image 52 for k in range(len(label_class)): 53 label_class_ = label_class[k] 54 # x_center / image_width 55 cx_normal = (xs_top_left[k] + roi_width[k] / 2) / image_width 56 # y_center/image_height 57 cy_normal = (ys_top_left[k] + roi_height[k] / 2) / image_height 58 # width/image_width 59 width_normal = roi_width[k] / image_width 60 # height/image_height 61 height_normal = roi_height[k] / image_height 62 63 # 写入文件 64 f.writelines(str(label_class_) + str(' ') + 65 str(cx_normal) + str(' ') + 66 str(cy_normal) + str(' ') + 67 str(width_normal) + str(' ') + 68 str(height_normal) + str(' ') + ' ') 69 f.close() 70 # i = i + 1 71 # if i == 10: 72 # break 73 74 print('')