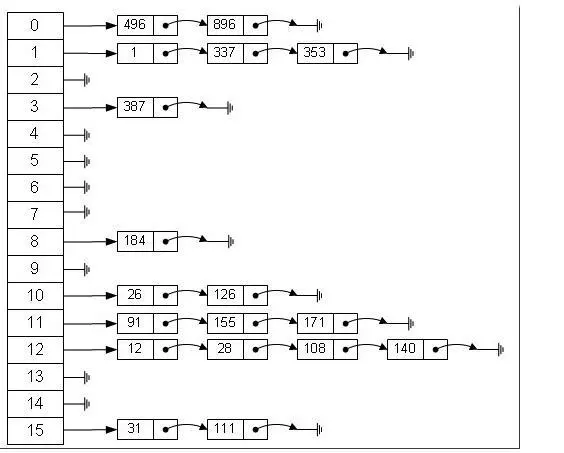
hashmap的数据结构
hashmap的结构,是一个数组,每个数组元素是一个链表,数组和链表的结合体。
如下图所示:
hashmap中的put方法逻辑
先根据key的hashcode计算出hash值,然后根据hash值得到这个元素在数组中的位置,
如果这个位置为空,直接插入元素;如果不为空,和equals比较每个元素的key,
如果相等则替换该元素的value,如果不等则将元素添加到上图最后面;
hashmap的长度为什么是2的n次方
h&(length-1)(length总是2的n次方的时候,等价于取模)
(2的n次方-1)结果二进制表示一定是:1111***111,
所有的位置都是1,1&0=0,1&1=1,这样保证了数据均匀分布在数组上;
假设length-1=00
00&11=00,00&01=00,00&&10=00,00&&00=00
这时候四个元素都在数组相同的位置。
假设length-1=11
11&11=11,11&00=00,11&&10=10,11&&01=01
这时候四个元素均匀分布。
hashmap中的get方法逻辑
先计算key的hashcode找到数组中的位置,
然后根据key的equals方法在对应的链表中寻找需要的元素。
hashmap中的resize方法
map长度capacity
map负载因子loadfactor(默认0.75)
当map中实际元素的个数,大于,capacity*loadfactory时,触发扩容;
扩容的过程,开辟一个capacity*2的空间;
将元素重新hash,移动的新的map上;
java集合面试题总结
https://blog.csdn.net/u010775025/article/details/79315361
java中为什么要使用迭代器
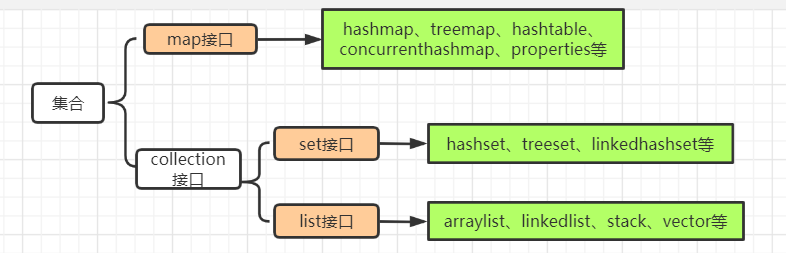
集合总结