一、迭代器
有时候我们在定义一个列表的时候,列表中的元素是具有一定规则的,这时候可以用列表生成式来提高一下我们的逼格。具体语法如下:
1 list = [i*3 for i in range(10)] #列表生成式 等价于 list = [0, 3, 6, 9, 12, 15, 18, 21, 24, 27]
2 print(list) #[0, 3, 6, 9, 12, 15, 18, 21, 24, 27]
理解了列表生成式的语法,生成器的写法就很容易了,只要将[]改成()即可,生成器的语法如下:
1 list_generate = (i*3 for i in range(10)) #列表生成器 2 print(list_generate) #执行结果<generator object <genexpr> at 0x03327C30>
列表生成式是在执行程序之前,就将数据生成并存放在内存中,而生成器是一个算法,只有程序在执行的过程中才会生成当前所需要的数据。下图是这两种方式在内存的存储方式:
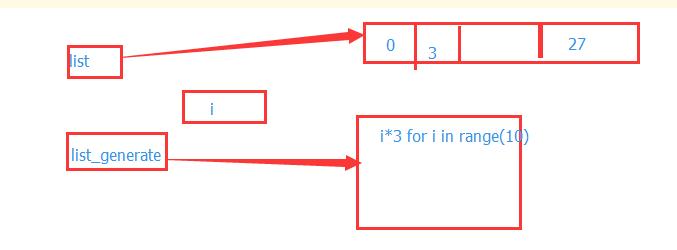
因此可以得出两种的区别:1、列表生成式占用内存,取的速度快 2、生成器占用很少内存,取的速度慢
对于生成器而言,要想获取生成器中的元素,需要每次调用其__next__()方法,如果我们的生成器有100万条数据,那我敢肯定你一定会疯掉的,因此我们一般用循环来取生成器中的数据,例如:
1 list_generate = (i*3 for i in range(10)) #列表生成器 2 for i in list_generate: 3 print(i)
函数生成器
使用关键字yield定义生成器。
1 def getNo(): 2 for i in range(10): 3 yield i 4 f = getNo() 5 print(f.__next__())
其中f就是一个生成器,下面我们利用函数生成器来实现单线程下的并发效果(著名的生产者消费者模式)。
1 import time 2 def consmer(name): 3 print("%s准备吃包子了。" % name) 4 while True: 5 baozi = yield 6 print("%s号包子来了,被%s吃了" % (baozi, name)) 7 def producter(name): 8 eat_p = consmer("吃货") 9 eat_p1 = consmer("饿货") 10 eat_p.__next__() 11 eat_p1.__next__() 12 for i in range(1,100,2): 13 print("老子开始做包子了") 14 time.sleep(2) 15 print("%s做了2个包子" % name) 16 eat_p.send(i-1) 17 eat_p1.send(i) 18 producter("高文祥")
Iterable(可迭代对象)
我们已经知道,可以直接作用于for循环的数据类型有以下几种:一类是集合数据类型,如list、tuple、dict、set、str等;一类是generator,包括生成器和带yield的generator function。这些可以直接作用于for循环的对象统称为可迭代对象:Iterable。可以使用isinstance()判断一个对象是否是Iterable对象。
from collections import Iterable print(isinstance([],Iterable),isinstance({},Iterable),isinstance(set,Iterable),isinstance("abc",Iterable))#执行结果True True False True
然而,生成器不但能够作用于for循环,还具有__next__()方法,像这种可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。可以使用isinstance()判断一个对象是否是Iterator对象。
1 from collections import Iterable,Iterator 2 print(isinstance([],Iterator),isinstance({},Iterator),isinstance(set,Iterator),isinstance("abc",Iterator),isinstance((i*2 for i in range(10)),Iterator))#执行结果False False False False True
然而,我们可以通过iter()方法把可迭代对象转换为迭代器
1 from collections import Iterable,Iterator 2 print(isinstance(iter([]),Iterator))
那为什么像list,字典都不是迭代器呢?
这是因为Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。
总结:
1、凡是可作用于for循环的对象都是Iterable类型;
2、凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;
3、集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
4、Python的for循环本质上就是通过不断调用next()函数实现的,例如:
1 for x in [1, 2, 3, 4, 5]: 2 pass
其实际上的实现步骤为:
1 # 首先获得Iterator对象: 2 it = iter([1, 2, 3, 4, 5]) 3 # 循环: 4 while True: 5 try: 6 # 获得下一个值: 7 x = next(it) 8 except StopIteration: 9 # 遇到StopIteration就退出循环 10 break