Reasons that processes utilize threading
- Programming abstraction. Dividing up work and assigning each division to a unit of execution (a thread) is a natural approach to many problems. Programming patterns that utilize this approach include the reactor, thread-per-connection, and thread pool patterns. Some, however, view threads as an anti-pattern. The inimitable Alan Cox summed this up well with the quote, "threads are for people who can't program state machines."
- Blocking I/O. Without threads, blocking I/O halts the whole process. This can be detrimental to both throughput and latency. In a multithreaded process, individual threads may block, waiting on I/O, while other threads make forward progress. Blocking I/O via threads is thus an alternative to asynchronous & non-blocking I/O.
- Memory savings. Threads provide an efficient way to share memory yet utilize multiple units of execution. In this manner they are an alternative to multiple processes.
- Parallelism. In machines with multiple processors, threads provide an efficient way to achieve true parallelism. As each thread receives its own virtualized processor and is an independently schedulable entity, multiple threads may run on multiple processors at the same time, improving a system's throughput.
The number of processors and the number of threads
The are two types of processors that we can encounter while doing parallel programming: physical processors and logical processors. The number of logical processors (processors that the operating system and applications can work with) is (usually) greater or equal to the number of physical processors (actual processors on the motherboard). For example, a hyperthreaded processor with 4 physical processors will have 8 logical processors. That means that the operating system can schedule up to 8 threads at the same time, even though on the motherboard you only have 4 processors. Therefore, the maximum number of threads you can create is equal to the number of logical processors your operating system sees. Core duo and core 2 duo are not hyperthreaded, hence the maximum number of threads you can create is 2, since you have 2 physical processors and 2 logical processors.
You can run more threads than you have logical processors. However, unless those threads are performing I/O, using more threads than you have logical processors will generally be less effective than using the number of threads as you have logical processors.
Discuss: Threads configuration based on no. of CPU-cores
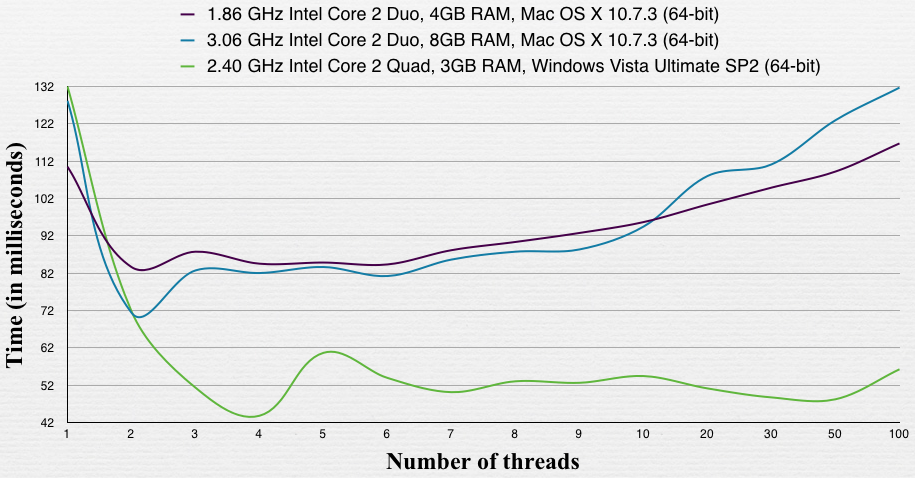
Performance test with a process doesn't do I/O. From: Optimal number of threads per core.
The Deadlock Problem
A set of blocked processes each holding a resource and waiting to acquire a resource held by another process in the set.
Example
● System has 2 tape drives.
● P0 and P1 each hold one tape drive and each needs another one

http://www2.latech.edu/~box/os/ch07.pdf
Deadlock detection in PostgreSQL:
Algorithm: https://www.postgresql.org/message-id/5946.979867205@sss.pgh.pa.us
Source Code: http://doxygen.postgresql.org/deadlock_8c_source.html
My Post: TODO
Reactor & Proactor: Comparing Two High-Performance I/O Design Patterns
An example will help to understand the difference between Reactor and Proactor. We will focus on the read operation here, as the write implementation is similar. Here's a read in Reactor:
- An event handler declares interest in I/O events that indicate readiness for read on a particular socket
- The event demultiplexor waits for events
- An event comes in and wakes-up the demultiplexor, and the demultiplexor calls the appropriate handler
- The event handler performs the actual read operation, handles the data read, declares renewed interest in I/O events, and returns control to the dispatcher
By comparison, here is a read operation in Proactor (true async):
- A handler initiates an asynchronous read operation (note: the OS must support asynchronous I/O). In this case, the handler does not care about I/O readiness events, but is instead registers interest in receiving completion events.
- The event demultiplexor waits until the operation is completed
- While the event demultiplexor waits, the OS executes the read operation in a parallel kernel thread, puts data into a user-defined buffer, and notifies the event demultiplexor that the read is complete
- The event demultiplexor calls the appropriate handler;
- The event handler handles the data from user defined buffer, starts a new asynchronous operation, and returns control to the event demultiplexor.
ABA Problem
Lost Notification (ZooKeeper)

Another example from ZooKeeper: Say that a client gets the data of a znode (e.g., /z), changes the data of the znode, and writes it back under the condition that the version is 1. If the znode is deleted and re-created while the client is updating the data, the version matches (beacuse version is reset when znode is re-created), but it now contains the wrong data.
https://www.cnblogs.com/549294286/p/3766717.html
<<Java Concurrency In Practice>> 15.4.4: The ABA problem can arise in algorithms that do their own memory management for link node objects. In this case, that the head of a list still refers to a previously observed node is not enough to imply that the contents of the list have not changed. If you cannot avoid the ABA problem by letting the garbage collector manage link nodes for you, there is still a relatively simple solution: instead of updating the value of a reference, update a pair of values, a reference and a version number. Even if the value changes from A to B and back to A, the version numbers will be different.
Lost Wakeup Problem
Calling pthread_cond_signal() or pthread_cond_broadcast() when the thread does not hold the mutex lock associated with the condition can lead to lost wakeup bugs.
A lost wakeup occurs when:
-
A thread calls pthread_cond_signal() or pthread_cond_broadcast().
-
And another thread is between the test of the condition and the call to pthread_cond_wait().
-
And no threads are waiting.
The signal has no effect, and therefore is lost.
Priority Inversion
The
pthread_cond_broadcast()orpthread_cond_signal()functions may be called by a thread whether or not it currently owns the mutex that threads callingpthread_cond_wait()orpthread_cond_timedwait()have associated with the condition variable during their waits; however, if predictable scheduling behavior is required, then that mutex shall be locked by the thread callingpthread_cond_broadcast()orpthread_cond_signal().
If pthread_cond_broadcast or pthread_cond_signal is called without mutex being locked, priority inversion may occur:
The problem (from the realtime side) with condition variables is that if you can signal/broadcast without holding the mutex, and any thread currently running can acquire an unlocked mutex and check a predicate without reference to the condition variable, then you can have an indirect priority inversion.
That is, high priority consumer thread A blocks on a condition variable because there are no entries on the queue; while lower priority consumer thread B continues processing some request. Producer thread C now adds an entry to the queue, unlocks the mutex, and signals the associated condition variable to unblock the highest priority waiter. But before the thread can be unblocked, scheduled, and contend for the mutex, thread B completes its work, acquires the mutex (which has no waiters), and removes the next work item. Higher priority thread A, when it is scheduled, either finds the mutex still locked by thread B and needs to reblock, or finds the mutex unlocked and "its" queue item gone. (On top of this, it may have preempted thread B to find this out, so that no work is getting done while we do the scheduling dance.) Even on a strict realtime scheduling uniprocessor this is perfectly reasonable; there might be a timeslice (e.g., producer and consumer B are SCHED_RR of equal priority) between the unlock and the signal or broadcast; the higher priority thread remains blocked and can't be considered by the scheduler. (Many realtime designers would consider this bad design; and in many ways it certainly is; but take it as just a simplified conceptual sketch. ;-) )
See here
Cacheline
Spurious Wakeup
Wait-Free & Lock-Free
Wait Morphing
Livelock
C10k Problem
(libevent, libev; GNU Pth, StateThreads Fiber; kylin, boost::asio; M:N Model : GHC threads, goroutine)
to be continued ...