简介
当程序中所有的SQL都是用到了一个或者多个索引,许多DBA就会对此感到满意,认为一切都看起来正常。但是,使用一个不合适的索引有可能会导致比全表扫面更差的性能。本随笔将详细地考虑这些极其重要的问题。首先给出我们讨论问题所需的前提假设。
磁盘及CPU时间的基础假设

磁盘随机读取一次4k或者8k大小的页,需要10ms,顺序读取速度40MB/s;CPU扫描一行记录需要5us,从缓存中获取一次数据需要100us;
不合适的索引
对于下面的简单SQL查询,仅有的两个合理的访问路径:
1、索引扫描
2、全表扫描
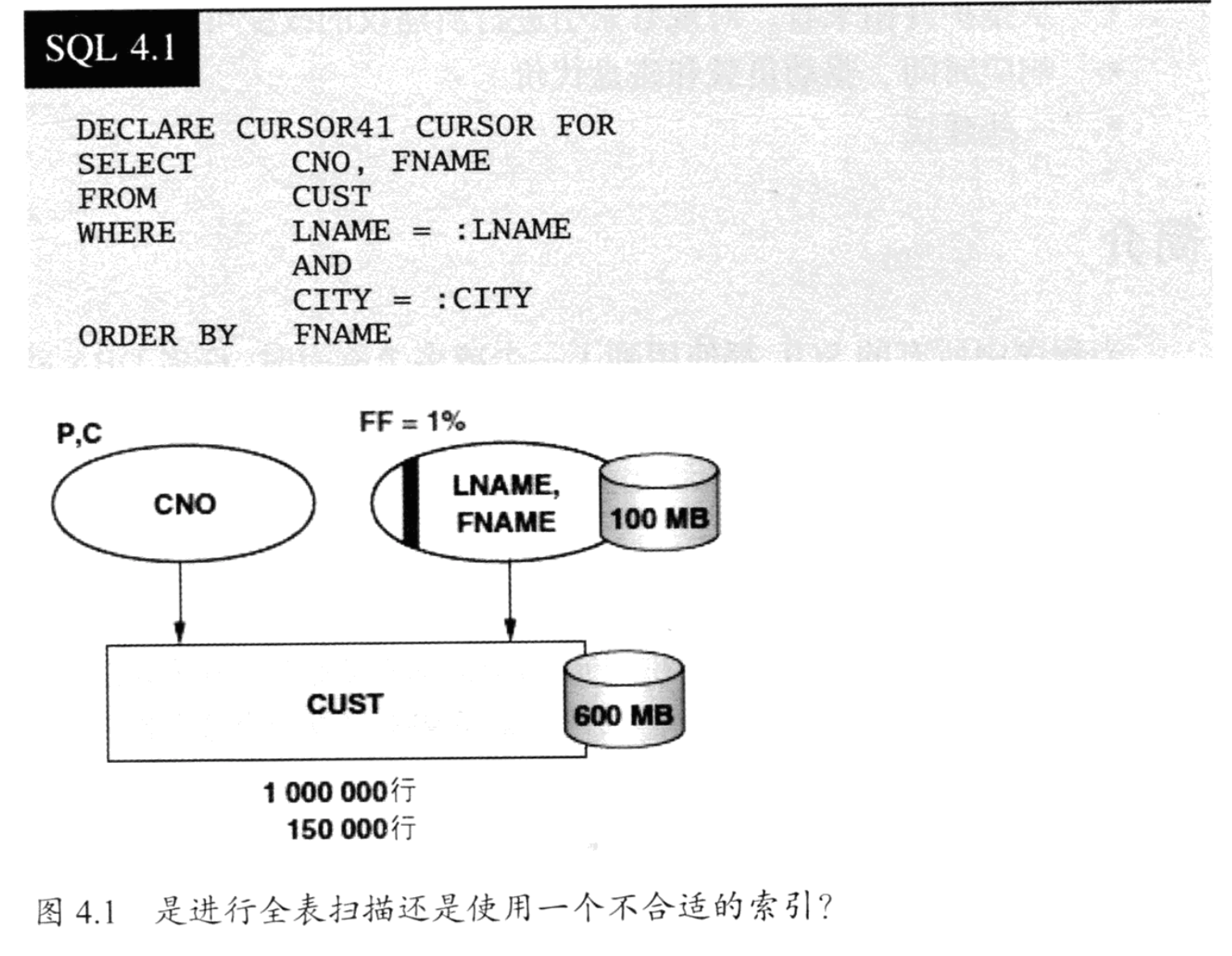
即使对于最普遍的姓氏(过滤因子1%),这两种选择是否能够提供可接受的响应时间呢?
对于第一种选择,数据库管理系统会根据where条件LNAME=:LNAME扫描索引片。对于索引片中的每一个索引行,数据库管理系统都必须回到表里检查CITY的值。由于表中的行是根据CNO而不是LNAME聚簇的,所以这个检查操作需要一次磁盘的随机读取。对于最普遍的姓氏,在不考虑CITY的过滤因子的条件下,获取完整的结果集意味着,需比对10000个索引行和10000个表行。那么,这个过程会耗时多少?
假设索引(LNAME,FNAME)的大小是10000*100byte=100MB,包括数据和离散的空闲空间,另外再假设顺序读的速度是40MB/s。读取一个宽度为1%的索引片,即1MB,需花费10ms+1/40s=35ms,这显然没有问题,但是10000次随机表读取需花费10000*10ms=100s,这使得这种方式太慢了。
对于第二种选择,只有第一个页需要随机读。如果表的大小为1000000*600byte=600MB,包括数据即分散的空闲空间,那么花费的I/O时间为10ms+600/40s=15s,仍旧很慢。
第二种选择的CPU时间将会比第一种选择的时间长得多,因为数据库系统需要比对1000000行而不是20000行,而且还要对这些行进行排序。从另一个方面看,由于是顺序读取,cpu时间跟I/O时间交叠。在这个场景下,全表扫描要比在不合适的索引上扫描快,但这还不够快,需要有一个更好的索引。
三星索引---查询语句的理想索引
前一小节我们讨论了CURSOR41的不合适的索引,这一小结我们讨论另一个极端,三星索引,即对于一个查询语句可能的最理想索引。类似图4.2中的查询语句,如果使用了三星索引,只需一次随机读取和一次窄索引片的扫描。因此,其响应时间会比使用普通索引的响应时间少几个数量级。
即使返回的结果集有1000行,CURSOR41(见SQL4.2)的响应时间也不足1s,这是怎么做到的呢?图4.2展示了索引最低一层叶子页的情况。
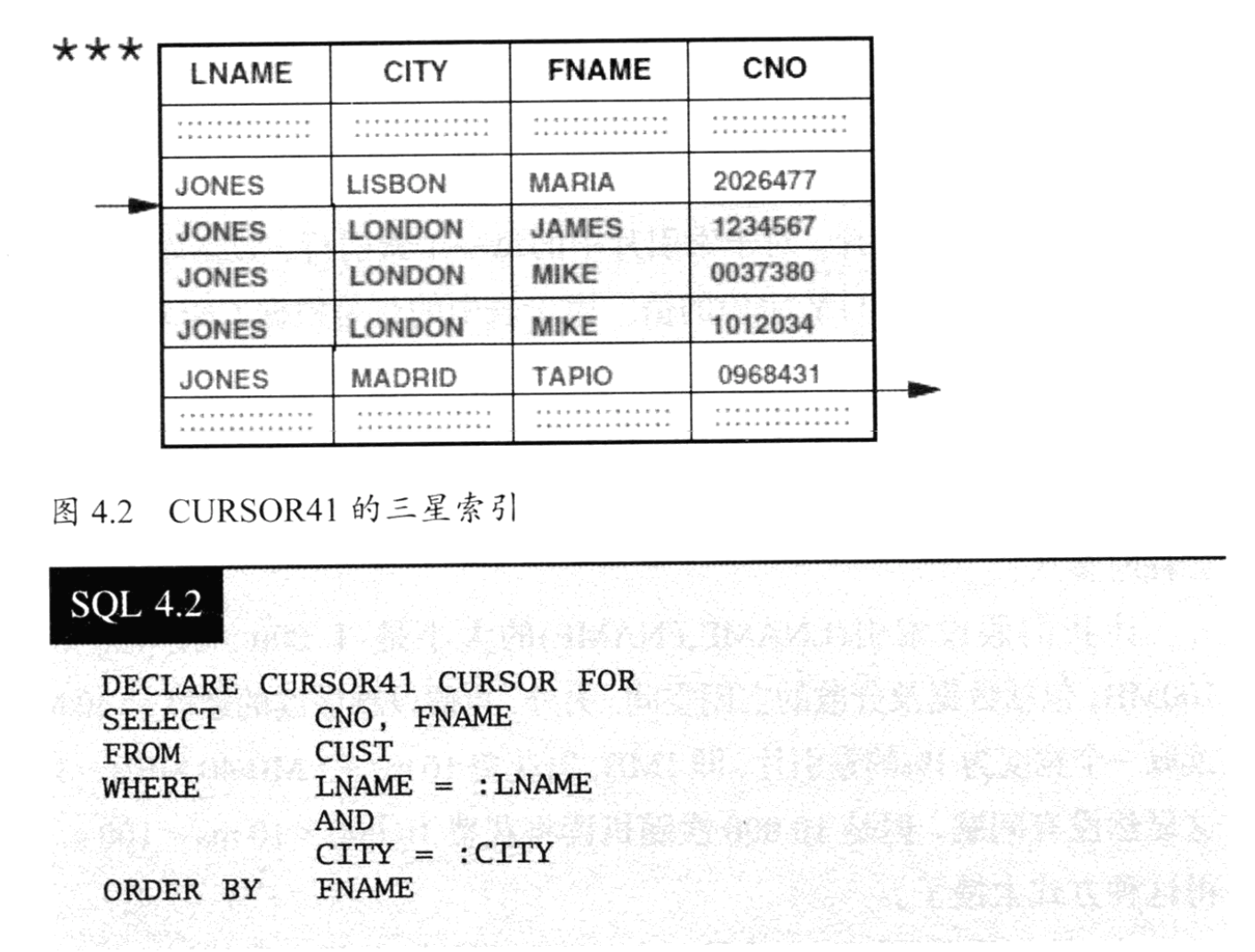
如果结果集只有1000行的话,那么组合where条件LNAME =: LNAME AND CITY =:CITY的过滤因子就是0.1%。被扫描的索引片就只有1000行,因为索引片的宽度完全由LNAME和CITY两个条件所决定。这种情况下,查询将花费1*1ms + 1000*0.1ms=0.1s。在这个过程中,表根本就没有被访问过,因为所需的列值都被复制到了索引中了。
星级是如何给定的
如果与一个查询相关的索引行是相邻的,或者至少相距足够靠近的话,那么这个索引就可以被标上第一颗星。这最小化了必须扫描的索引片的宽度。
如果索引行的顺序跟查询语句的需求一致,则索引可以被标记上第二颗星。这排除了排序操作。
如果索引行包含查询语句中的所有列,那么索引可以标记上第三颗星。这可以避免对表的操作:因为直接访问索引就可以了。
对于这三颗星,第三颗星通常是最重要的,将一个列排除在索引之外可能会导致许多速度较慢的磁盘随机读。我们把至少包含第三颗星的索引称作对应查询语句的宽索引。

为了满足第一颗星
取出所有等值条件(等值,并不是范围)的列。把这些列作为索引最开头的列,以任意顺序都可以。对于CURSOR4.1来说,三星索引可以以LNAME,CITY或CITY,LNAME开头。在这两种情况下,必须扫描的索引片宽度将索至最小。
为了满足第二颗星
将order by列加入到索引中。不要改变这些列的顺序,但是忽略那些在第一步中已经加入索引的列。例如,如果在CURSOR4.1 order by中有重复的列,比如 order by FNAME,LNAME或者order by CITY,FNAME,只有FNAME列需要被加到索引中。当FNAME是索引的第三列时,结果集中的记录无需排序就已经是以正确的顺序排序的了。第一次读取操作将返回FNAME值最小的那一行。
为了满足第三颗星
将查询语句中剩余的列加到索引的尾部,列在索引中添加的顺序对查询语句的性能没有影响,但是将易变的列放在最后能降低更新的成本。现在,索引已包含了满足无须回表的访问路径所需要的全部列。
最终三星索引将会是:
(LNAME,CITY,FNAME,CNO)或(CITY,FNAME,CNO,LNAME)
CURSOR4.1在以下三个方面是最为挑剔的:
- where条件不包含访问条件(between,>,<等);
- from语句指设计单表
- 所有条件对优化器来说都足够简单
范围条件和三星索引
下面的SQL4.3需要的信息跟之前相同,只是现在LNAME是在一个范围内。

让我们为这个CURSOR设计一个三星索引。大部分的推论跟CURSOR4.1相同,但是“between条件”将“=条件”替换后将会有很大的影响。我们将以相反的顺序考虑三颗星。
首先是第三颗星,按照先前所述,确保查询语句中的所有列都在索引中就能满足第三颗星。这样不需要访问表,那么同步读也就不会造成问题。
添加order by列能使索引满足第二颗星,但是这个仅在将其放在between范围条件列LNAME之前的情况下才成立,如索引(CITY,FNAME,LNAME),由于CITY的值只有一个,所以使用这个索引可以使结果集以FNAME的顺序排列,而不需要额外的排序。但是如果order by字段加在between范围条件列LNAME后面,如索引(CITY,LNAME,FNAME),那么索引行不是按照FNAME排序的,需要对结果集进行额外的排序。因此为了满足第二颗星,FNAME必须放在范围条件列LNAME之前,如索引(FNAME,...)或者(CITY,FNAME,...)。
再考虑第一颗星,如果CITY放在索引的第一列,那我们将会有一个相对较窄的索引片需要扫描,这取决于CITY的过滤因子。但是如果使用(CITY,LNAME)的话,索引片将会更窄,这样在有两个列的情况下我们只需要访问真正需要的索引列。但是,为了做到这样,并从一个很窄的索引片中获益,其他列(如FNAME)就不能放在这两列之间。
所以,我们的理想索引会有几颗星呢?首先,肯定能有第三颗星,但是,正如我们刚才所说,我们只能有第一颗星或者第二颗星,而不能同时拥有两者!换句话说,我们只能二选一:
- 避免排序,选择第二颗星,或者
- 拥有可能的最窄索引片,不仅将需要处理的索引行数降至最低,而且将后续处理量,特别是表数据的同步读,减少到最低,拥有第一颗星。
在这个例子中,由于between或者其他任何访问条件的出现,意味着我们不能同时拥有第一和第二颗星。也就是说我们不能拥有一个三星索引。
为查询语句设计最佳索引的算法
根据以上的讨论,理想的索引是一个三星索引。然而,正如我们所见,当存在访问条件时,这是不可能实现的。我们(也许)不得不牺牲第二颗星来满足一个更窄的索引片,这样最佳索引就只拥有两颗星。这也就是为什么我们要仔细区分理想和最佳。在这个例子中,理想索引是不可能实现的。将这层因素考虑在内,我们可以对所有情况下创建最佳索引的过程公式化。创建出的索引将拥有三颗星或者两颗星。
首先设计一个索引片尽可能窄(第一颗星)的宽索引(第三颗星)。如果查询使用时不需要排序,那这个索引就是三星索引。否则,这个索引就只能是二星索引,牺牲第二颗星。或者采取另一种选择,避免排序,牺牲第一颗星保留第二颗星。
下面我们阐述为查询语句创建最佳索引的算法。
候选A
- 取出对于优化器来说不过分复杂的等值条件列。将这些列作为索引的前导列,以任意顺序皆可。
- 将选择性最好的范围条件作为索引的下一个列,如果存在的话。最好的选择性是指对于最差的输入有最低的过滤因子。只考虑对于优化器来说不过分复杂的范围条件即可。
- 以正确的顺序添加order by列,(如果列有DESC的话,加上DESC)。忽略在第一步或第二步已经添加的列。
- 以任意顺序将select语句中其余的列添加至索引中(但是需要以不易变的列开始)。
候选B
如果候选A引起了所给查询语句的一次排序操作,那么还可以设计候选B。根据定义,对于候选B来说,第二颗星比第一颗星更重要。
- 取出对于优化器来说不过分复杂的等值条件列。将这些列作为索引的前导列,以任意顺序皆可。
- 以正确的顺序添加order by列,(如果列有DESC的话,加上DESC)。忽略在第一步中已经添加的列。
- 以任意顺序将select语句中其余的列添加至索引中(但是需要以不易变的列开始)。
现今排序速度那么快,为什么还需要候选B
近几年来,排序速度已经提升了很多。现在大多数的排序过程都在内存中进行,用当下最快的处理器排序一行花费的CPU时间大约在5us左右。因此,排序50000行的数据所耗费的时间只有0.5s。这对于一次事务操作来说是可以接受的,但对于CPU时间来说是一个比较大的开销。
由于在现在的硬件条件下排序速度很快,所以如果一个程序取出结果集的所有行,那么候选A可能和候选B一样快,甚至比候选B更快。对于程序员来说,这是最方便的解决方案。许多环境都提供了灵活的命令来浏览结果集。
然而,如果一个程序只需获取能够填充满一个屏幕的数据量,那么候选B可能会比候选A快得多。如果结果集很大的话,为了产生第一屏的数据,二星索引候选A(需要排序)可能会花费非常长的时间。我们需要时刻记着,客户端的一次错误输入可能会使得结果集变得非常大。
如果访问路径中没有排序的话,使用CURSOR44程序将会非常快(假设LNAME和CITY是索引的前两列,不管顺序如何),即使结果集包含数以百万级的数据行。每个事务永远都不会使数据库管理系统物化大于20行的数据。
