CUDA C是一种在GPU上支持多线程并行化的语言,有了CUDA,很多需要多线程运行的程序变得简单起来,今天我们将从CUDA的的向量加法说起。
问题定义
向量加法是十分常见的操作,对于一个长度为n的向量,其运算规则如下:
[{c[i] = a[i] + b[i] for i < n}
]
即将对应位置上的元素依次进行相加。
C++实现
有了上述的算法,我们可以很快地写出一个C++版本的实现,其实就是一个循环的事情。
#include <iostream>
#include <stdlib.h>
#include <sys/time.h>
#include <math.h>
using namespace std;
int main()
{
struct timeval start, end;
gettimeofday( &start, NULL );
float *A, *B, *C;
int n = 1024 * 1024;
int size = n * sizeof(float);
A = (float*)malloc(size);
B = (float*)malloc(size);
C = (float*)malloc(size);
for(int i=0;i<n;i++)
{
A[i] = 90.0;
B[i] = 10.0;
}
for(int i=0;i<n;i++)
{
C[i] = A[i] + B[i];
}
float max_error = 0.0;
for(int i=0;i<n;i++)
{
max_error += fabs(100.0-C[i]);
}
cout << "max_error is " << max_error << endl;
gettimeofday( &end, NULL );
int timeuse = 1000000 * ( end.tv_sec - start.tv_sec ) + end.tv_usec - start.tv_usec;
cout << "total time is " << timeuse/1000 << "ms" <<endl;
return 0;
}
很明显,遍历相加,几乎没啥代码量,这里为了对比,我们加上了时间测量。
测试结果

最终的运行结果为16ms。
CUDA版本
在CUDA中,我们称CPU为host,GPU为device,称在device上运行的函数为核(kernel)函数,需要使用__global__来修饰。
还有两个其他的修饰符号__device__和__host__,三者区别在于globa可以被cpu函数调用,device只可以被cuda代码调用,host和device可以同时使用,以便在某个函数中可以同时兼容使用GPU或CPU。
在运行核函数时,可以将其放入多个blocks和多个threads中运行,所以在每次运行核函数需要定义每个block中的threads和需要的blocks数。
其函数形式如下所示:Kernel_fun<<<Blocks, ThreadsPreBlock>>>(...);
在逻辑上grid>block>thread。
于是我们可以实现一个GPU版本的向量加法:
#include "cuda_runtime.h"
#include <stdlib.h>
#include <iostream>
#include <sys/time.h>
using namespace std;
__global__
void Plus(float A[], float B[], float C[], int n)
{
int i = blockDim.x * blockIdx.x + threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
struct timeval start, end;
gettimeofday( &start, NULL );
float*A, *Ad, *B, *Bd, *C, *Cd;
int n = 1024 * 1024;
int size = n * sizeof(float);
// CPU端分配内存
A = (float*)malloc(size);
B = (float*)malloc(size);
C = (float*)malloc(size);
// 初始化数组
for(int i=0;i<n;i++)
{
A[i] = 90.0;
B[i] = 10.0;
}
// GPU端分配内存
cudaMalloc((void**)&Ad, size);
cudaMalloc((void**)&Bd, size);
cudaMalloc((void**)&Cd, size);
// CPU的数据拷贝到GPU端
cudaMemcpy(Ad, A, size, cudaMemcpyHostToDevice);
cudaMemcpy(Bd, B, size, cudaMemcpyHostToDevice);
cudaMemcpy(Bd, B, size, cudaMemcpyHostToDevice);
// 定义kernel执行配置,(1024*1024/512)个block,每个block里面有512个线程
dim3 dimBlock(512);
dim3 dimGrid(n/512);
// 执行kernel
Plus<<<dimGrid, dimBlock>>>(Ad, Bd, Cd, n);
// 将在GPU端计算好的结果拷贝回CPU端
cudaMemcpy(C, Cd, size, cudaMemcpyDeviceToHost);
// 校验误差
float max_error = 0.0;
for(int i=0;i<n;i++)
{
max_error += fabs(100.0 - C[i]);
}
cout << "max error is " << max_error << endl;
// 释放CPU端、GPU端的内存
free(A);
free(B);
free(C);
cudaFree(Ad);
cudaFree(Bd);
cudaFree(Cd);
gettimeofday( &end, NULL );
int timeuse = 1000000 * ( end.tv_sec - start.tv_sec ) + end.tv_usec - start.tv_usec;
cout << "total time is " << timeuse/1000 << "ms" <<endl;
return 0;
}
cuda的运行分为以下几个步骤:
- cudaMalloc为在显存上开辟一段内存空间,具体用法和malloc类似。
- cudaMemcpy为内存拷贝函数,需要将Host上的数据拷贝到device上,不然无法运行。
- 经过kernel函数运行,计算对应的结果,结果保存在显存中。
- 最后将算好的结果拷贝回Host,不要忘了free掉内存和显存。
这里配置了(1024*1024/512)个block,每个block里面有512个线程,在计算时,这些线程理论上将同时运行。
测试结果
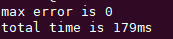
结果为179ms,确实出乎意外,这是由于kernel函数计算过于简单,而GPU的调度同样需要时间,使得GPU的时间实际上要高于cpu。