几个概念:命名空间、作用域、闭包
命名空间又名name space, 举例说明,若变量x=1,1存放于内存中,那名字x存放在哪里呢?名称空间正是存放名字x与1绑定关系的地方
名称空间共3种,分别如下
- locals: 是函数内的名称空间,包括局部变量和形参
- globals: 全局变量,函数定义所在模块的名字空间
- builtins: 内置模块的名字空间
不同变量的作用域不同就是由这个变量所在的命名空间决定的。
作用域即范围
- 全局范围:全局存活,全局有效
- 局部范围:临时存活,局部有效
查看作用域方法 globals(),locals()
作用域的查找顺序:
LEGB: locals -> enclosing function -> globals -> __builtins__
- locals 是函数内的名字空间,包括局部变量和形参
- enclosing 外部嵌套函数的名字空间
- globals 全局变量,函数定义所在模块的名字空间
- builtins 内置模块的名字空间
闭包的概念
即函数定义和函数表达式位于另一个函数的函数体内(嵌套函数)。而且,这些内部函数可以访问它们所在的外部函数中声明的所有局部变量、参数。当其中一个这样的内部函数在包含它们的外部函数之外被调用时,就会形成闭包。也就是说,内部函数会在外部函数返回后被执行。而当这个内部函数执行时,它仍然必需访问其外部函数的局部变量、参数以及其他内部函数。这些局部变量、参数和函数声明(最初时)的值是外部函数返回时的值,但也会受到内部函数的影响。
闭包的意义:返回的函数对象,不仅仅是一个函数对象,在该函数外还包裹了一层作用域,这使得,该函数无论在何处调用,优先使用自己外层包裹的作用域
装饰器:
为了满足软件开发的“封闭-开放”原则(封闭:已实现的功能代码块不应该被修改;’开放:对现有功能的扩展开放),可以使用装饰器
def decorator(func): def inner(): print('这是一个装饰器') func() return inner @decorator # f = decorator(f) def f(): print('fffffff') f()
上面代码运行的过程其实是这样的:
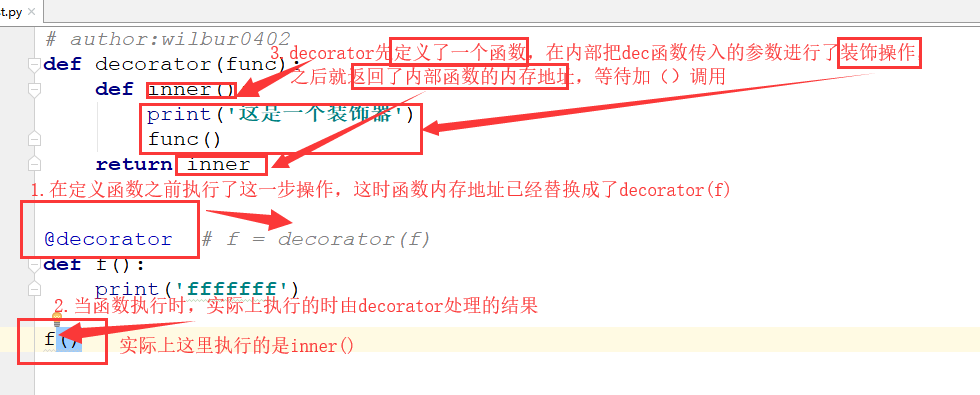
这里可能比较乱,说的简单一点就是:先把函数的内存地址拿出来,然后拿着内存地址扔到装饰器里加个装饰并调用,然后封装起来,再把封装后的内容的内存地址替换原来的内存地址的位置,这样,在执行原来的函数就是执行的封装起来的内容了
这是不带参数的装饰器,许多时候需要装饰的函数都是带有参数的,所以带参数的函数怎么加装饰器呢?
# author:wilbur0402 def decorator(func): def inner(*args,**kwargs): print('这是一个装饰器') func(*args,**kwargs) return inner @decorator # f = decorator(f) def f(n): print(n, 'fffffff') f(333)
只需要用非固定参数就能解决
如果需要用不同装饰形式来装饰函数,该怎么办呢?这就需要带参数的装饰器了:
def deco(auth_type): def auth(func): def inner(*args,**kwargs): print('这是一个带参数的的装饰器') if auth_type == 'QQ': print('这是QQ装饰方式') func(*args,**kwargs) elif auth_type == 'WX': print('这是WX装饰方式') func(*args, **kwargs) else: print('不支持的装饰方式') return inner return auth @deco('QQ') # = @auth def f(n): print(n, 'fffffff') f(333)
列表生成式、生成器、迭代器:
>>>a = [i+1 for i in range(10)] >>>a [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
如果列表元素可以按照某种算法推算出来,可以在循环的过程中不断推算出后续的元素,这样就不必创建完整的list,从而节省大量的空间。这种方法就是生成器
>>> L = [x * x for x in range(10)] >>> L [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] >>> g = (x * x for x in range(10)) >>> g <generator object <genexpr> at 0x1022ef630>
只要把一个列表生成式的[]改成(),就创建了一个generator
当取生成器里的值时,可以使用next()方法,一个一个取,当没有值可取的时候,抛出StopIteration错误;
另一种方法就是用for循环去取,因为生成器也是一个可迭代对象,而且不会报错
>>> g = (x * x for x in range(10)) >>> for n in g: ... print(n) ... 0 1 4 9 16 25 36 49 64 81
定义复杂算法的生成器:
把函数变成生成器,可以把函数的输出改成yield就可以:
def fib(max): n,a,b = 0,0,1 while n < max: #print(b) yield b a,b = b,a+b n += 1
return 'done'
generator和函数的执行流程不一样。函数是顺序执行,遇到return语句或者最后一行函数语句就返回。而变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次被next()调用时从上次返回的yield语句处继续执行。
迭代器:
可以直接作用于for循环的数据类型有以下几种:
一类是集合数据类型,如list、tuple、dict、set、str等;
一类是generator,包括生成器和带yield的generator function。
这些可以直接作用于for循环的对象统称为可迭代对象:Iterable。
可以使用isinstance()判断一个对象是否是Iterable对象,而生成器不但可以作用于for循环,还可以被next()函数不断调用并返回下一个值,直到最后抛出StopIteration错误表示无法继续返回下一个值了。
可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator
总结:
凡是可作用于for循环的对象都是Iterable类型;
凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;
集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。