在计算机图形学中,BVH树是一种空间划分的数据结构,广泛运用于光线追踪。今天来讲述一下它的建立和遍历方法。
BVH树的建立
BVH树的建立分为以下几步:
1.遍历当前场景中的所有物体,存储下它们的每一个图元(primitive,例如三角形、圆形等);对每一个图元,计算它们的包围盒。
2.递归构建BVH树。
BVH树是一种二叉树,每一个节点记录了它自己的包围盒。对于叶子节点,它存储了它所包含的所有图元;对于非叶子节点,记录了它所包含的孩子节点。节点的定义如下:
struct BVHBuildNode {
BVHBuildNode* children[2];
BoundingBox boundingbox;
int splitAxis, firstPrimeOffset, nPrimitives;
void initLeaf(int first, int n, const BoundingBox&b);
void initInterior(int axis, BVHBuildNode*c0, BVHBuildNode*c1);
};
接下来展示递归建立BVH树的代码:
BVHBuildNode* BVHManager::recursiveBuild(int start, int end, int* totalnodes, std::vector<Primitive*>& ordered_prims)
{
BVHBuildNode* node = nullptr;
(*totalnodes)++;
int nPrimitives = end - start;
BoundingBox bounds;
for (int i = start; i < end; i++)
bounds = BoundingBox::Union(bounds, primitives[i]->getBoundingBox());
if (nPrimitives == 1)
node = createLeafNode(start, end, totalnodes, ordered_prims, bounds);
else if(nPrimitives > 1)
{
int dim = bounds.maximumExtent();
if(bounds.getTopFromDim(dim)==bounds.getBottomFromDim(dim))
node = createLeafNode(start, end, totalnodes, ordered_prims, bounds);
else
{
int mid = partitionPrimitivesWithSAH(start, end, dim, bounds);
if(mid < 0)
node = createLeafNode(start, end, totalnodes, ordered_prims, bounds);
else {
node = new BVHBuildNode;
node->initInterior(dim,
recursiveBuild(start, mid, totalnodes, ordered_prims),
recursiveBuild(mid, end, totalnodes, ordered_prims));
}
}
}
return node;
}
这里最重要的步骤就是给定一个节点及其包围盒,如何对它进行空间划分。在这里我们采用SAH(Surface Area Heuristic)算法。该算法首先寻找boundingbox中跨度最长的一个轴作为用来分割的轴,然后沿着该轴N等分为一个个块,最后根据代价公式遍历每一个块,如图所示:
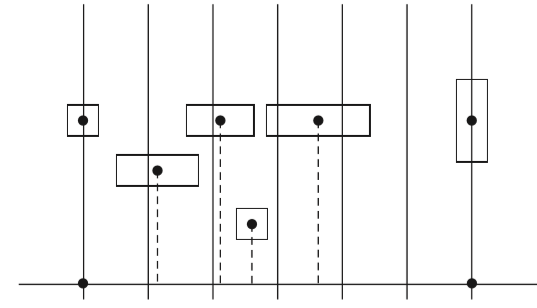
我们要做的是寻找出从哪一个块开始分割,使得代价最小。代价公式如下所示:

A和B是由当前的包围盒分割出的两个子模块,t(trav)和t(isect)我们可以当做是常数,pA和pB代表光线打到两个子块的概率,我们用两个子块相对于父亲的面积来计算。
这样一来,就可以写出计算SAH的代码:
int BVHManager::partitionPrimitivesWithSAH(int start, int end, int dim, BoundingBox& bounds)
{
int nPrimitives = end - start;
int nBuckets = BVHManager::nBuckets;
if (nPrimitives <= 4)
return partitionPrimitivesWithEquallySizedSubsets(start, end, dim);
else
{
for (int i = start; i < end; i++)
{
BoundingBox prim_bounds = primitives[i]->getBoundingBox();
int b = nBuckets *
(prim_bounds.getCenterValFromDim(dim) - bounds.getBottomFromDim(dim)) /
(bounds.getTopFromDim(dim) - bounds.getBottomFromDim(dim));
if (b == nBuckets)
b--;
buckets[b].count++;
buckets[b].bounds = BoundingBox::Union(buckets[b].bounds, prim_bounds);
}
float cost[BVHManager::nBuckets - 1];
for (int i = 0; i < nBuckets - 1; i++)
{
BoundingBox b0, b1;
int count0 = 0, count1 = 0;
for (int j = 0; j <= i; j++)
{
b0 = BoundingBox::Union(b0, buckets[j].bounds);
count0 += buckets[j].count;
}
for (int j = i+1; j < BVHManager::nBuckets; j++)
{
b1 = BoundingBox::Union(b1, buckets[j].bounds);
count1 += buckets[j].count;
}
float val0 = count0 ? count0 * b0.surfaceArea() : 0.0f;
float val1 = count1 ? count1 * b1.surfaceArea() : 0.0f;
cost[i] = 0.125f + (val0 + val1) / bounds.surfaceArea();
}
float min_cost = cost[0];
int min_ind = 0;
for (int i = 0; i < BVHManager::nBuckets -1; i++)
{
if (cost[i] < min_cost)
{
min_cost = cost[i];
min_ind = i;
}
}
if (nPrimitives > maxPrimsInNode || min_cost < nPrimitives)
{
Primitive** p = std::partition(&primitives[start], &primitives[end - 1] + 1,
[=](const Primitive* pi) {
int b = nBuckets *
(pi->getBoundingBox().getCenterValFromDim(dim) - bounds.getBottomFromDim(dim)) /
(bounds.getTopFromDim(dim) - bounds.getBottomFromDim(dim));
if (b == nBuckets)
b--;
return b <= min_ind;
});
return p - &primitives[0];
}
else
return -1;
}
}
经过上面的步骤后,就可以对空间进行划分,建立出SAH树。
建立完BVH树后,为了节省空间和提高遍历的性能,我们需要将这个二叉树的结构压缩到一个线性数组中。做到:
1.初始节点是数组中第一个元素
2.对于非叶子节点,它的第一个孩子就是数组中的下一个元素,同时它会存储第二个孩子的索引
3.对于叶子节点,它会记录自己包含的图元
下图是线性化二叉树的示意图:
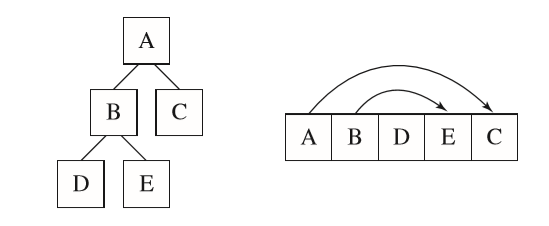
具体的线性化二叉树节点定义及建立过程如下:
struct LinearBVHNode {
BoundingBox boundingbox;
union
{
int primitivesOffset; // leaf
int secondChildOfset; // interior
};
int nPrimitives;
int axis;
};
int BVHManager::flattenBVHTree(BVHBuildNode* node, int* offset)
{
LinearBVHNode& lnode = linear_nodes[*offset];
lnode.boundingbox = node->boundingbox;
int myOffset = (*offset)++;
if (node->nPrimitives > 0)
{
lnode.primitivesOffset = node->firstPrimeOffset;
lnode.nPrimitives = node->nPrimitives;
}
else
{
lnode.axis = node->splitAxis;
lnode.nPrimitives = 0;
flattenBVHTree(node->children[0], offset);
lnode.secondChildOfset = flattenBVHTree(node->children[1], offset);
}
return myOffset;
}
经过上面的一系列步骤,我们就将BVH树建立了起来,可以用于实战了。
BVH树的遍历
在进行投射光线,寻找场景中的交点时,就可以遍历BVH树来加速。BVH树的遍历和线性化二叉树的遍历基本一致,代码如下:
float min_t = -1.0f;
auto bvh_nodes = objectManager.getBVHManager()->getBvhNodes();
std::stack<int> nodesToVisit;
int cur_node_index = 0;
while (true)
{
LinearBVHNode node = bvh_nodes[cur_node_index];
if (node.boundingbox.isIntersect(ray, XMMatrixIdentity()))
{
if (node.nPrimitives > 0)
{
for (int i = 0; i < node.nPrimitives; i++)
{
float t=-1.0f;
Primitive* p = objectManager.getBVHManager()->getPrimitive(node.primitivesOffset + i);
IntersectInfo it;
if (p->is_intersect(ray, t, it) && (min_t < 0.0f || t < min_t))
{
min_t = t;
info = it;
}
}
if (nodesToVisit.empty())
break;
cur_node_index = nodesToVisit.top();
nodesToVisit.pop();
}
else
{
if(ray.dirIsNeg(node.axis))
{
nodesToVisit.push(cur_node_index + 1);
cur_node_index = node.secondChildOfset;
}
else
{
nodesToVisit.push(node.secondChildOfset);
cur_node_index++;
}
}
}
else
{
if (nodesToVisit.empty())
break;
cur_node_index = nodesToVisit.top();
nodesToVisit.pop();
}
}
注意代码中有一处判断光线的方向是否为负的地方,它是为了让当前最接近光线方向的孩子包围盒首先被搜寻,这样在搜寻第二个孩子的时候,如果进行的包围盒相交判断得到t值比之前存储的最小t值大的话,就无需再进一步深入该子节点进行相交检测,可以节省一定的计算量。
如图就是我根据一个Mesh建立出的BVH树的包围盒:

经我测试,加入BVH树后,对于上图的Mesh,进行光线相交检测的速度提高了近25倍。