熵:H(D)=-Plog2(P)
info(A)=Info(D)-Info_A(D)
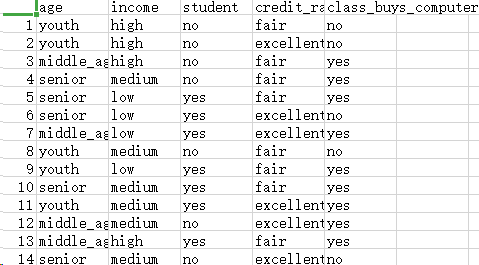
打开CSV文件:
分析:属性 :age income student credit_rating 类:buys_computer
共14人
from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import tree
from sklearn import preprocessing #数据的预处理
from sklearn.externals.six import StringIO
# 打开CSV文件
allElectionicsData=open(r'G:MachineLearning/AllElectronics.csv','rt')
reader=csv.reader(allElectionicsData)
headers=next(reader)
print("结果是:")
print(headers)
#分阶段展示结果:
featureList=[] #featureList是属性列表
labelList=[] # labelList是类列表
for row in reader: # 对每行进行循环遍历
labelList.append(row[len(row)-1])
rowDict={} #字典
for i in range(1,len(row)-1):
rowDict[headers[i]]=row[i]
featureList.append(rowDict) #类
print(featureList)
结果:[{'age': 'youth', 'income': 'high', 'student': 'no', 'credit_rating': 'fair'},
{'age': 'youth', 'income': 'high', 'student': 'no', 'credit_rating': 'excellent'},
{'age': 'middle_aged', 'income': 'high', 'student': 'no', 'credit_rating': 'fair'},
{'age': 'senior', 'income': 'medium', 'student': 'no', 'credit_rating': 'fair'},
{'age': 'senior', 'income': 'low', 'student': 'yes', 'credit_rating': 'fair'},
{'age': 'senior', 'income': 'low', 'student': 'yes', 'credit_rating': 'excellent'},
{'age': 'middle_aged', 'income': 'low', 'student': 'yes', 'credit_rating': 'excellent'},
{'age': 'youth', 'income': 'medium', 'student': 'no', 'credit_rating': 'fair'},
{'age': 'youth', 'income': 'low', 'student': 'yes', 'credit_rating': 'fair'},
{'age': 'senior', 'income': 'medium', 'student': 'yes', 'credit_rating': 'fair'},
{'age': 'youth', 'income': 'medium', 'student': 'yes', 'credit_rating': 'excellent'},
{'age': 'middle_aged', 'income': 'medium', 'student': 'no', 'credit_rating': 'excellent'},
{'age': 'middle_aged', 'income': 'high', 'student': 'yes', 'credit_rating': 'fair'},
{'age': 'senior', 'income': 'medium', 'student': 'no', 'credit_rating': 'excellent'}]
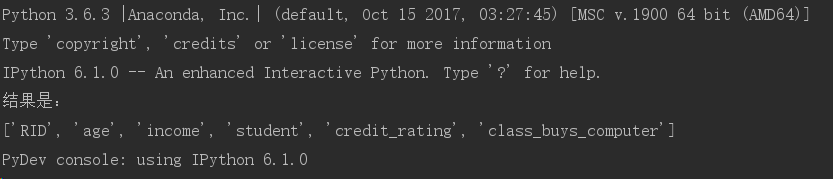
将14个数据初步转换成14行列表的形式:便于下一步利用vec.fit_transform(feature).toarray
#Vetorize features
vec=DictVectorizer()
dummyX=vec.fit_transform(featureList).toarray() #转换0,1,scikit库可以识别
print("dummyX:"+str(dummyX))
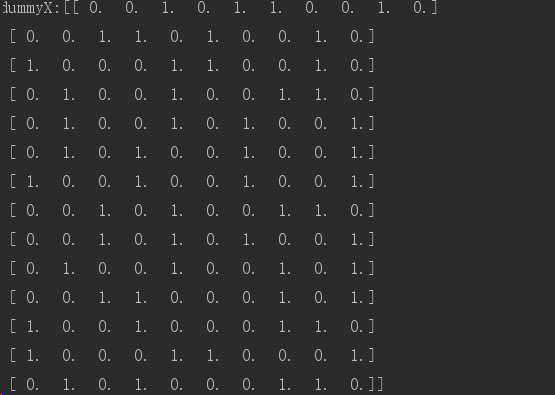
print(vec.get_feature_names())
['age=middle_aged', 'age=senior', 'age=youth', 'credit_rating=excellent', 'credit_rating=fair', 'income=high', 'income=low', 'income=medium', 'student=no', 'student=yes']
# labelList存放类
print("labelList:"+str(labelList))
lb=preprocessing.LabelBinarizer()
dummY=lb.fit_transform(labelList)
print("dummyY:"+str(dummY)
#选择器
clf=tree.DecisionTreeClassifier()
clf=tree.DecisionTreeClassifier(criterion='entropy') #熵 entropy
clf=clf.fit(dummyX,dummY)
print("clf:"+str(clf))
# Visualize model
with open("allElectronicInformationGainOri.dot", 'w') as f:
f = tree.export_graphviz(clf, feature_names=vec.get_feature_names(), out_file=f)
oneRowX = dummyX[0, :].reshape(1,-1)
print("oneRowX: " + str(oneRowX))
newRowX = oneRowX
newRowX[0][0] = 1
newRowX[0][2] = 0
print("newRowX: " + str(newRowX))
predictedY = clf.predict(newRowX)
print("predictedY: " + str(predictedY))

注意维度的变换