Logistic回归
通常用于估计一个实例属于某个特定类别的概率,例如,电子邮件是垃圾邮件的概率是多少
概率估计
Logistic回归模型计算输入特征的加权和(加上偏差项),将结果输入Logistic()函数进行二次加工后进行输出
逻辑回归模型的概率估计(向量形式):
Logistic函数(也称logit),(sigma())表示,是一个sigmoid函数(图像呈S型),它的输出是一个介于0和1之间的数字。
sigmoid函数:
图像为

代码:
t = np.linspace(-10,10,100)
sig = 1 / (1 + np.exp(-t))
plt.figure(figsize=(9,3))
plt.plot([-10,10],[0,0],'k-')
plt.plot([-10,10],[1,1],'k:')
plt.plot([-10,10],[0.5,0.5],'k:')
plt.plot([0,0],[-1.1,1.1],'k-')
plt.plot(t,sig,'b-',linewidth=2,label=r'$sigma(t)=frac{1}{1+e^{-t}}$')
plt.axis([-10,10,-0.1,1.1])
plt.legend(loc='upper left',fontsize=20)
plt.xlabel('t')
plt.show()
利用Logistic回归模型估计得到了x属于正类的概率(hat{p}=h_ heta(x)),利用预测模型,很容易得到预测结果(hat{y})
逻辑回归预测模型
训练和损失函数
训练的目的是设置参数向量( heta),使得正例(y=1)概率增大,负例(y=0)的概率减小,其通过在单个训练实力x的损失函数实现
单个样本的损失函数:
当t接近0时,(-log(t))变的非常大,所以如果模型估计一个正例概率接近于0,那么损失函数将会很大,同时如果模型估计一个负例的概率接近1,那么损失函数同样会很大。另一方面,当t接近1时,(-log(t))接近0,所以如果模型估计一个正例概率接近于0,那么损失函数接近于0,同时如果模型估计一个负例概率接近于0,那么损失函数同样会接近于0。
那对于整个训练集上的损失函数呢?那就是对所有训练实例的平均值,称为对数损失函数
逻辑回归的损失函数(对数损失):
这个损失函数对于求解最小化损失函数的( heta)是没有公式解的(没有等价的正规方程),但是,这个损失函数是凸的,所以梯度下降(或任何其他优化算法)一定能够找到全局最小值。
逻辑损失函数的偏导数:
首先计算每个样本的预测误差,然后误差项乘以第j项特征值,最后求出所有样本的平均值。
决策边界
使用鸢尾花数据集来分析Logistic回归。其中包括150朵三种不同的鸢尾花的萼片和花瓣的长度和宽度,这三种鸢尾花为:Setosa,Versicolor,Virginica

仅利用花瓣的宽度来识别Virginica
加载数据:
from sklearn import datasets
iris = datasets.load_iris()
list(iris)
X = iris['data'][:,3:]#petal width
y = (iris['target'] == 2).astype(np.int) #是Iris-Virginica为1,否则为0
训练逻辑回归模型
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression(solver='liblinear',random_state=42)
log_reg.fit(X,y)
模型估计的花瓣宽度从0到3厘米的概率估计
X_new = np.linspace(0,3,1000).reshape(-1,1)
y_proba = log_reg.predict_proba(X_new)
plt.plot(X_new,y_proba[:,1],'g-',linewidth=2,label='Iris-Virginica')
plt.plot(X_new,y_proba[:,0],'b--',linewidth=2,label='Not Iris-Virginica')

X_new = np.linspace(0,3,1000).reshape(-1,1)
y_prob = log_reg.predict_proba(X_new)
decision_boundary = X_new[y_prob[:,1]>=0.5][0]
plt.figure(figsize=(8,3))
plt.plot(X[y==0], y[y==0], "bs")
plt.plot(X[y==1], y[y==1], "g^")
plt.plot(X_new,y_prob[:,1],'g-',linewidth=2,label='Iris-Virginica')
plt.plot(X_new,y_proba[:,0],'b--',linewidth=2,label='Not Iris-Virginica')
plt.plot([decision_boundary,decision_boundary],[-1,2],'k:',linewidth=2)
plt.text(decision_boundary+0.02, 0.15, "Decision boundary", fontsize=14, color="k", ha="center")
plt.arrow(decision_boundary,0.08,-0.3,0,head_width=0.05,head_length=0.1,fc='b',ec='b')
plt.arrow(decision_boundary,0.92,0.3,0,head_width=0.05,head_length=0.1,fc='g',ec='g')
plt.axis([0,3,-0.02,1.02])
plt.xlabel("Petal width (cm)", fontsize=14)
plt.ylabel("Probability", fontsize=14)
plt.legend(loc="center left", fontsize=14)
plt.show()
decision_boundary

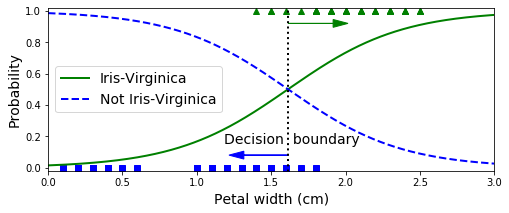
Virginica 花的花瓣宽度(用三角形表示)在 1.4 厘米到 2.5 厘米之间,而其他种类的花(由正方形表示)通常具有较小的花瓣宽度,范围从 0.1 厘米到 1.8 厘米。注意,它们之间会有一些重叠。在大约 2 厘米以上时,分类器非常肯定这朵花是Virginica花(分类器此时输出一个非常高的概率值),而在1厘米以下时,它非常肯定这朵花不是 Virginica 花(不是 Virginica 花有非常高的概率)。在这两个极端之间,分类器是不确定的。但是,如果你使用它进行预测(使用 predict() 方法而不是 predict_proba() 方法),它将返回一个最可能的结果。因此,在 1.6 厘米左右存在一个决策边界,这时两类情况出现的概率都等于 50%:如果花瓣宽度大于 1.6 厘米,则分类器将预测该花是 Virginica,否则预测它不是(即使它有可能错了):
log_reg.predict([[1.7],[1.5]])
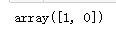
利用花瓣的宽度和长度两个特征进行判断
X = iris['data'][:,(2,3)]# petal length, petal width
y = (iris['target']==2).astype(np.int)
log_reg = LogisticRegression(solver='liblinear',C=10**10,random_state=42)
log_reg.fit(X,y)
x0,x1 = np.meshgrid(np.linspace(2.9,7,500).reshape(-1,1),
np.linspace(0.8,2.7,200).reshape(-1,1))
X_new = np.c_[x0.ravel(),x1.ravel()]
y_proba = log_reg.predict_proba(X_new)
plt.figure(figsize=(10,4))
plt.plot(X[y==0,0],X[y==0,1],'bs')
plt.plot(X[y==1, 0], X[y==1, 1], "g^")
#绘制等高线
zz = y_proba[:,1].reshape(x0.shape)
contour = plt.contour(x0,x1,zz,cmap=plt.cm.brg)
left_right = np.array([2.9, 7])
boundary = -(log_reg.coef_[0][0] * left_right + log_reg.intercept_[0]) / log_reg.coef_[0][1]
plt.clabel(contour,inline=1,fontsize=12)
plt.plot(left_right,boundary,'k--',linewidth=3)
plt.text(3.5, 1.5, "Not Iris-Virginica", fontsize=14, color="b", ha="center")
plt.text(6.5, 2.3, "Iris-Virginica", fontsize=14, color="g", ha="center")
plt.xlabel('Petal length',fontsize=14)
plt.ylabel('Petal width',fontsize=14)
plt.axis([2.9,7,0.8,2.7])
plt.show()
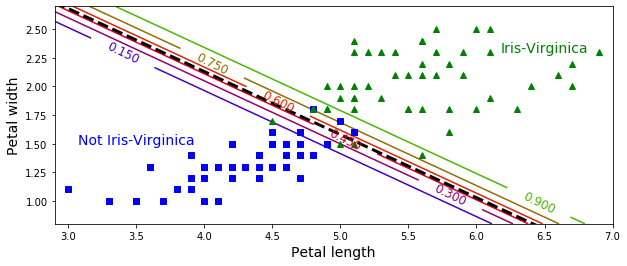
一旦训练完毕,Logistic 回归分类器就可以根据这两个特征来估计一朵花是 Virginica 的可能性。 虚线表示这时两类情况出现的概率都等于 50%:这是模型的决策边界。 请注意,它是一个线性边界。每条平行线都代表一个分类标准下的两两个不同类的概率,从 15%(左下角)到 90%(右上角)。越过右上角分界线的点都有超过 90% 的概率是 Virginica 花。
Softmax回归
Logistic回归模型可以直接推广到支持多类别分类,不必组合和训练多个二分类器,其称为Softmax回归或多类别Logistic回归
当给定一个实例x时,Softmax 回归模型首先计算k类的分数(s_k(x)),然后将分数应用在 Softmax 函数(也称为归一化指数)上,估计出每类的概率。 计算 (s_k(x))的公式看起来很熟悉,因为它就像线性回归预测的公式一样
k类的Softmax得分
一旦你计算了样本x的每一类的得分,你便可以通过 Softmax 函数估计出样本属于第k类的概率 :通过计算e的(s_k(x))次方,然后对它们进行归一化(除以所有分子的总和)。
Softmax 函数:
- K 表示有多少类
- s(x)表示包含样本x每一类得分的向量
- (sigma(s(x))_k)表示给定每一个类分数之后,实例x属于第k类的概率
和 Logistic 回归分类器一样,Softmax 回归分类器将估计概率最高(它只是得分最高的类)的那类作为预测结果
Softmax 回归模型分类器预测结果:
现在来建立一个模型在目标类别上有着较高的概率(因此其他类别的概率较低),最小化公式如下,可以达到这个目标,其表示了当前模型的损失函数,称为交叉熵,当模型对目标类得出了一个较低的概率,其会惩罚这个模型。 交叉熵通常用于衡量待测类别与目标类别的匹配程度
交叉熵:
- 如果对于第i个实例的目标类是k,那么(y_k^{(i)}=1,反之y_k^{(i)}=0)
K类交叉熵的梯度向量:
现在可以计算每一类的梯度向量,然后使用梯度下降(或者其他的优化算法)找到使得损失函数达到最小值的参数矩阵(Theta)
使用Softmax回归对三种鸢尾花进行分类
当你使用 LogisticRregression 对模型进行训练时,Scikit Learn 默认使用的是一对多模型,但是你可以设置 multi_class 参数为“multinomial”来把它改变为 Softmax 回归。你还必须指定一个支持 Softmax 回归的求解器,例如“lbfgs”求解器,其默认使用l2正则化,可以使用超参数C控制它
X=iris['data'][:,(2,3)]
y = iris['target']
softmax_reg = LogisticRegression(multi_class='multinomial',solver = 'lbfgs',C=10,random_state=42)
softmax_reg.fit(X,y)
x0, x1 = np.meshgrid(
np.linspace(0, 8, 500).reshape(-1, 1),
np.linspace(0, 3.5, 200).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(),x1.ravel()]
y_proba = softmax_reg.predict_proba(X_new)
y_predict = softmax_reg.predict(X_new)
zz1 = y_proba[:, 1].reshape(x0.shape)
zz = y_predict.reshape(x0.shape)
plt.figure(figsize=(10, 4))
plt.plot(X[y==2, 0], X[y==2, 1], "g^", label="Iris-Virginica")
plt.plot(X[y==1, 0], X[y==1, 1], "bs", label="Iris-Versicolor")
plt.plot(X[y==0, 0], X[y==0, 1], "yo", label="Iris-Setosa")
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#fafab0','#9898ff','#a0faa0'])
plt.contourf(x0, x1, zz, cmap=custom_cmap)
contour = plt.contour(x0, x1, zz1, cmap=plt.cm.brg)
plt.clabel(contour, inline=1, fontsize=12)
plt.xlabel("Petal length", fontsize=14)
plt.ylabel("Petal width", fontsize=14)
plt.legend(loc="center left", fontsize=14)
plt.axis([0, 7, 0, 3.5])
plt.show()
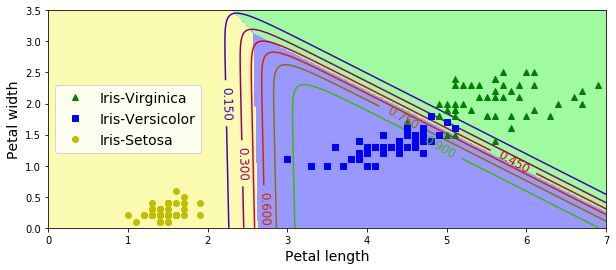
用不同的背景颜色表示结果的决策边界。注意:任何两个类之间的决策边界是线性的。该图的曲线表示 Versicolor 类的概率(例如,用 0.450 标记的曲线表示 45% 的概率边界)。注意模型也可以预测一个概率低于 50% 的类。 例如,在所有决策边界相遇的地方,所有类的估计概率相等,分别为 33%。
softmax_reg.predict([[5,2]])

softmax_reg.predict_proba([[5,2]])
学习本节的感受,通过sklearn对逻辑回归的使用并没有什么问题,毕竟是个调包,但画图感觉还是挺具有挑战的