HA
相比于Hadoop1.0,Hadoop 2.0中的HDFS增加了两个重大特性,HA(热备)和Federation(联邦)。HA即为High Availability,用于解决NameNode单点故障问题,该特性通过热备的方式为主NameNode提供一个备用者,一旦主NameNode出现故障,可以迅速切换至备NameNode,从而实现不间断对外提供服务。
在一个典型的HDFSHA场景中,通常由两个NameNode组成,一个处于active状态,另一个处于standby状态。Active NameNode对外提供服务,比如处理来自客户端的RPC请求,而Standby NameNode则不对外提供服务,仅同步active namenode的状态,以便能够在它失败时快速进行切换。
为了能够实时同步Active和Standby两个NameNode的元数据信息(实际上editlog),需提供一个共享存储系统,可以是NFS、QJM(Quorum Journal Manager)或者Bookeeper,Active Namenode将数据写入共享存储系统,而Standby监听该系统,一旦发现有新数据写入,则读取这些数据,并加载到自己内存中,以保证自己内存状态与Active NameNode保持基本一致,如此这般,在紧急情况下standby便可快速切为active namenode。
【注意事项】
(1)主备NameNode有多种配置方法,本课程使用Journal Node方式。为此,需要至少准备3个节点作为Journal Node(必须奇数个),这三个节点可与其他服务,比如NodeManager共用节点
(2)主备两个NameNode应位于不同机器上,这两台机器不要再部署其他服务,即它们分别独享一台机器。(注: HDFS 2.0中无需再部署和配置Secondary Name,备NameNode已经代替它完成相应的功能)
(3)主备NameNode之间有两种切换方式:手动切换和自动切换,其中,自动切换是借助Zookeeper实现的,因此,需单独部署一个Zookeeper集群(通常为奇数个节点,至少3个)。本课程使用手动切换方式。
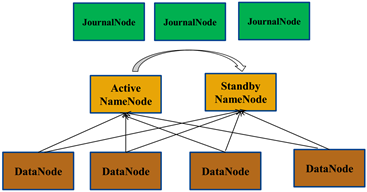
在图中,Active NameNode作为主,Standby作为备。Standby和NameNode为了实现实时数据服务同步,使用JournalNode(奇数个)完成,当Active瘫痪时,可快速切换到Standby。
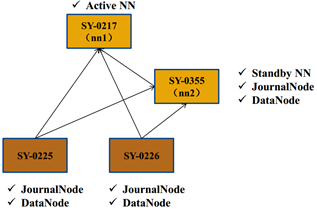
一般将Active NameNode作为一个单独节点,然后DataNode和JournalNode作为同一个节点(JournalNode占的资源不多),至于Standby NameNode应该做一个单独节点,这里放到DataNode和JournalNode的节点中,如上图,没有做一个单独节点,考虑实验机器问题。
准备工作
1) linux优化
同2.1.8(1)。
2) 配置节点
对所有Node,配置vim /etc/hosts添加10.30.30.1 whaozl001等的ip映射;
10.30.30.1 whaozl001
10.30.30.5 whaozl005
10.30.30.6 whaozl006
10.30.30.7 whaozl007
10.30.30.8 whaozl008
10.30.30.2 whaozl002
这里配置3个DataNode,1个NameNode,给每个节点主机修改主机名(虚拟机名称、ip映射名、linux主机名):
主机名
ip地址(内网)
linux用户名
密码
充当角色
NameNode
whaozl001(主)
10.30.30.1
haozhulin
123456
nn/rm
NameNode
whaozl002(备)
10.30.30.2
haozhulin
123456
nn/sn
DataNode
whaozl005
10.30.30.5
haozhulin
123456
dn/nm/jn
DataNode
whaozl006
10.30.30.6
haozhulin
123456
dn/nm/jn
DataNode
whaozl007
10.30.30.7
haozhulin
123456
dn/nm/jn
DataNode
whaozl008
10.30.30.8
haozhulin
123456
dn/nm(无jn)
【其他】集群逻辑名称为myhadoop,JournalNode共享命名空间为myspace,集群主NameNode和备NameNode逻辑名称为nn1和nn2。
虚拟机名称就是虚拟机文件夹名。用户均为haozhulin,其在linux的/home目录下有一个haozhulin文件夹(用户文件夹)。在cluster中充当的角色(namenode, secondary namenode, datanode , resourcemanager, nodemanager,Standby namenode,JournalNode)。HA后就没有secondary namenode,Standby nameNode就充当这个角色。whaozl002作为备NameNode。
【注意】这里特别注意,JournalNode一定必须是奇数个,所以whaozl008就不会作为jn咯。
解压
将安装包hadoop-2.2.0.tar.gz存放到/home/haozhulin/install/目录下,并解压,先让其有执行权限,然后直接./就可以解压
chmod +x hadoop-2.2.0.tar.gz
./hadoop-2.2.0.tar.gz
配置之前,在whaozl001主机的/home/haozhulin/install/hadoop-2.2.0/下建立三个文件夹:~/dfs/name、~/dfs/data、~/temp;
接下来修改/home/haozhulin/install/hadoop-2.2.0/etc/hadoop/下的7个文件。
hadoop-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
slaves
yarn-env.sh
修改hadoop-env.sh
配置hadoop的jdk版本环境
cd /home/haozhulin/install/hadoop-2.2.0/etc/hadoop/
vim hadoop-env.sh
hadoop-env.sh为hadoop环境变量,依赖JDK,进行如下修改
#第27行
export JAVA_HOME=/home/haozhulin/install/java/jdk1.7.0_09
修改core-site.xml
在其<configuration></ configuration >中插入:
<!-- 制定HDFS的老大(NameNode)的地址 -->
<property>
<!--<name>fs.default.name</name>-->
<name>fs.defaultFS</name>
<!--若主备自动切换要配置逻辑名称,手动切换就写死-->
<value>hdfs://whaozl001:9000</value>
</property>
<!--指定hadoop运行时产生文件的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>file:///home/haozhulin/install/hadoop-2.2.0/tmp</value>
</property>
<!--指定hadoop运行的流文件的缓冲区,单位B,这里设置为128KB-->
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.proxyuser.haozhulin.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.haozhulin.groups</name>
<value>*</value>
</property>
若使用zookeeper自动切换主备,在配置hdfs-site.xml中的dfs.namesservices之后,则core-site.xml中的fs.defaultFS对应的value值应为(即保持一致):
<property>
<name>fs.defaultFS</name>
<value>hdfs://myhadoop1 </value>
</property>
修改hdfs-site.xml
在该文件中配置集群的逻辑名称、集群的NameNode(主/备)的逻辑名称
在其<configuration></ configuration >中插入:
<!-- HDFS命名服务的逻辑名称-->
<property>
<name>dfs.nameservices</name>
<value>myhadoop </value>
</property>
<!--对myhadoop服务进行配置2个NameNode-->
<property>
<name>dfs.ha.namenodes.myhadoop</name>
<value>nn1,nn2</value>
</property>
<!--对myhadoop服务进行配置rpc通信地址--->
<property>
<name>dfs.namenode.rpc-address.myhadoop.nn1</name>
<value>whaozl001:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address. myhadoop.nn2</name>
<value>whaozl002:8020</value>
</property>
<!--对myhadoop服务进行配置http通信地址--->
<property>
<name>dfs.namenode.http-address.myhadoop.nn1</name>
<value>whaozl001:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.myhadoop.nn2</name>
<value>whaozl002:50070</value>
</property>
<!--指定主NameNode/备NameNode同步元数据信息在JournalNode上的存放位置-->
<!--myhadoop为JournalNode同步元数据信息的集群命名空间,可与myhadoop不同-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://whaozl005:8485; whaozl006:8485; whaozl007:8485/myspace</value>
</property>
<!--主和备是否自动切换,这里设置否-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>false</value>
</property>
<!--指定JournalNode在本地磁盘存放数据的位置-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/haozhulin/install/hadoop-2.2.0/dfs/journal/</value>
</property>
<!--配置NameNode元信息存放的路径,推荐配置多个,逗号隔开-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/haozhulin/install/hadoop-2.2.0/dfs/name</value>
</property>
ß配置DataNode数据信息存放的路径,可配置多个,逗号隔开-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/haozhulin/install/hadoop-2.2.0/dfs/data</value>
</property>
<!--指定HDFS存在block的副本数量,默认值是3个,现有4个DataNode,该值不大于4即可-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
修改mapred-site.xml
从template命名mapred-site.xml后<configuration></configuration>中插入:
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>whaozl001:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value> whaozl001:19888</value>
</property>
修改yarn-site.xml
在其<configuration></ configuration >中插入:
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>whaozl001</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!--whaozl001修改为${yarn.resourcemanager.hostname}-->
<property>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<!------------------------------------------------增加部分------------------------------------------------>
<property>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>${yarn.home.dir}/etc/hadoop/fairscheduler.xml</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/home/haozhulin/install/hadoop-2.2.0/yarn/local</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>30720</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>12</value>
</property>
<!------------------------------------------------------------------------------------------------------------>
修改slaves
#定位到/home/haozhulin/install/hadoop-2.2.0/etc/hadoop/slaves文件
vim etc/hadoop/slaves
#由于是单机伪分布,所以DataNode就只有localhost
#不需要修改,也可以改为127.0.0.1,都是指本机
#slaves文件中记录所有的slave节点,写入以下内容
#指定所有的DataNode节点列表,每行一个节点名称
whaozl005
whaozl006
whaozl007
whaozl008
修改yarn-en.sh
同修改hadoop-env.sh,修改里面的JAVA_HOME值。
修改fairscheduler.xml
fairscheduler.xml为yarn资源的分配配置,这里配置了3个队列(queue),每一个队列的资源内存单位是MB,CPU为核数(vcores)。
<?xml version="1.0"?>
<allocations>
<queue name="infrastructure">
<minResources>102400 mb, 50 vcores </minResources>
<maxResources>153600 mb, 100 vcores </maxResources>
<maxRunningApps>200</maxRunningApps>
<minSharePreemptionTimeout>300</minSharePreemptionTimeout>
<weight>1.0</weight>
<aclSubmitApps>root,yarn,search,hdfs,haozhulin</aclSubmitApps>
</queue>
<queue name="tool">
<minResources>102400 mb, 30 vcores</minResources>
<maxResources>153600 mb, 50 vcores</maxResources>
</queue>
<queue name="sentiment">
<minResources>102400 mb, 30 vcores</minResources>
<maxResources>153600 mb, 50 vcores</maxResources>
</queue>
</allocations>
将配置复制到其他节点
这里可以写一个shell脚本进行操作(有大量节点时比较方便)。
scp –r /home/haozhulin/install/hadoop-2.2.0 haozhulin@whaozl005:~/install
scp –r /home/haozhulin/install/hadoop-2.2.0 haozhulin@whaozl006:~/install
scp –r /home/haozhulin/install/hadoop-2.2.0 haozhulin@whaozl007:~/install
scp –r /home/haozhulin/install/hadoop-2.2.0 haozhulin@whaozl008:~/install
scp –r /home/haozhulin/install/hadoop-2.2.0 haozhulin@whaozl002:~/install
scp –r 表示递归到目录和目录中文件远程复制到目标主机,~表示当前用户目录(用户目录~/=/home/haozhulin)。可以先拷贝hadoop-2.2.0解压后,然后采用同步方法,只同步里面的etc/hadoop/下的配置文件即可 (一般还是全部同步过去,懒得拷贝)。
scp –r /home/haozhulin/install/hadoop-2.2.0/etc/hadoop/* haozhulin@whaozl005:~/ install/hadoop-2.2.0/etc/hadoop/
启动Hadoop
启动和格式化步骤与其他的有部分地方不同:
#Step1
#在各个JournalNode节点whaozl005/whaozl006/whaozl007(没有whaozl008)上,输入以下命令启动journalnode服务
sbin/hadoop-daemon.sh start journalnode
#Step2
#在[nn1]=[whaozl001]主机上,对其进行格式化(第一步),并启动namenode:
bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
#Step3
在[nn2]=[whaozl002]主机上,同步nn1的元数据信息:
bin/hdfs namenode –bootstrapStandby
#Step4
在[nn2]=[whaozl002]主机上,启动namenode:
sbin/hadoop-daemon.sh start namenode
#经过以上4步操作,nn1和nn2均处于standby状态
#Step5
#在nn1上将[nn1]切换为Active(这里是手动切换,如果配置了zookeeper就不需要这句,其自动)
#nn1为hdfs-site.xml中的
bin/hdfs haadmin -transitionToActive nn1
#Step Last
#在[nn1]上,启动所有datanode(daemons多一个s)
sbin/hadoop-daemons.sh start datanode
#Step Yarn
#启动yarn
sbin/start-yarn.sh
【注意】可通过jps查看进程,只有第一次启动才格式化,下次启动应该省略掉格式化/同步元数据信息的操作(下面是精简总结)。
sbin/hadoop-daemon.sh start journalnode#在各whaozl005/whaozl006/whaozl007上执行
sbin/hadoop-daemon.sh start namenode#分别在主机whaozl001/whaozl002上执行
bin/hdfs haadmin -transitionToActive nn1#若没zookeeper就在whaozl001上执行该句
sbin/hadoop-daemons.sh start datanode#在whaozl001上执行
#以上四句可以直接替换如下一句执行
sbin/start-dfs.sh
sbin/start-yarn.sh
关闭Hadoop
#在[nn1]=[whaozl001]上,输入以下命令
sbin/stop-dfs.sh
测试Hadoop
#在[nn1]=[whaozl001]上
#测试pi值
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar pi 2 100
#查看集群状态
./bin/hdfs dfsadmin –report
#查看文件块组成
./bin/hdfsfsck / -files –blocks
#查看HDFS:
http://10.30.30.1:50070
#查看RM
http://10.30.30.1:8088