1) 扑克牌手动演练k均值聚类过程:>30张牌,3类。
随机抽出中心点 5,10 ,8(红色数字为牌数量,蓝色数字为聚类中心点):

再次聚类:

最终聚类中心结果,为:4 ,12, 8
2)自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。
代码:
import numpy as np from sklearn.datasets import load_iris import matplotlib.pyplot as plt k = int(input("请输入类中心个数:")) iris = load_iris() data = iris.data[:, 2] # 获取鸢尾花花瓣长度 center = np.random.choice(data , k) n = len(data) dist = np.zeros(n) # 获取每个点到样本中心的距离 flag = True while flag: new_center = np.zeros(k) # 定义一个新的中心 for i in range(n): d = np.zeros(k) for j in range(k): d[j] = (abs(center[j] - data[i])) # 计算这个点到中心点的距离 dist[i] = np.argmin(d) # 找出最小距离的下标 # 计算各聚类新均值 for c in range(k): # 按照下标来聚类 index = dist == c new_center[c] = np.mean(data[index]) # 计算新聚类中心 # 判断新中心是否与原先中心相等,若相等,则结束聚类 if np.all(center == new_center): break else: center = new_center print('最终聚类结果为: ',dist) plt.scatter(data, data, c=dist, s=50, cmap="Paired") plt.show()
结果:

可视化:
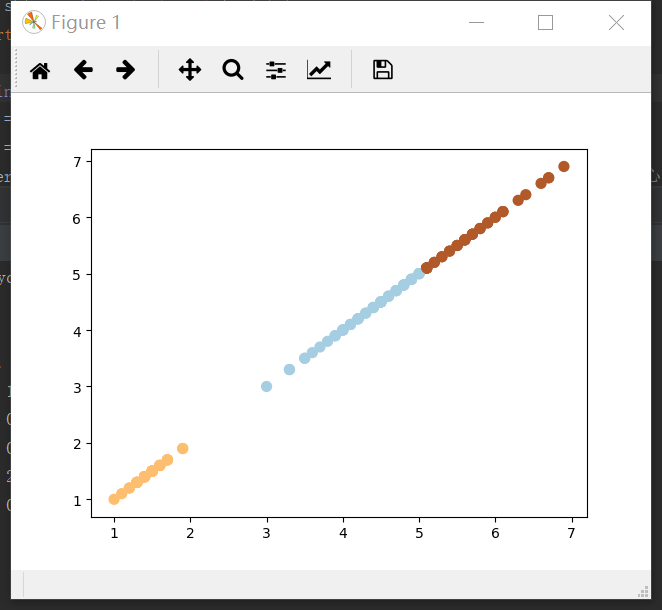
3)用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示。
代码:
from sklearn.datasets import load_iris import matplotlib.pyplot as plt from sklearn.cluster import KMeans iris = load_iris() data = iris.data[:, 2] x = data.reshape(-1, 1) km_model = KMeans(n_clusters=3) km_model.fit(x) y = km_model.predict(x) plt.scatter(x[:, 0], x[:, 0], c=y, s=50, cmap="rainbow") plt.show()
结果:

4)鸢尾花完整数据做聚类并用散点图显示。
代码:
from sklearn.datasets import load_iris import matplotlib.pyplot as plt from sklearn.cluster import KMeans iris = load_iris() x = iris.data km_model = KMeans(n_clusters=3) km_model.fit(x) y = km_model.predict(x) plt.scatter(x[:, 2], x[:, 3], c=y, s=50, cmap="Paired") plt.show()
结果:

5)想想k均值算法中以用来做什么?
行为细分:按购买历史记录细分 按应用程序,网站或平台上的活动进行细分, 根据兴趣定义角色, 根据活动监控创建配置文件
库存分类: 按销售活动分组库存 ,按制造指标对库存进行分组
分类传感器测量: 检测运动传感器中的活动类型 ,分组图像 ,单独的音频 ,确定健康监测中的群体
检测机器人或异常: 从机器人中分离出有效的活动组, 将有效活动分组以清除异常值检测