报错分析:
在使用ElasticSearch中的bulk进行批量操作的时候,老是批量写入不成功,报错:
"index" : {
"_index" : "books",
"_type" : "info",
"_id" : "4",
"status" : 400,
"error" : {
"type" : "mapper_parsing_exception",
"reason" : "failed to parse",
"caused_by" : {
"type" : "json_parse_exception",
"reason" : "Invalid UTF-8 start byte 0xba
at [Source: org.elasticsearch.common.bytes.AbstractBytesReference$MarkSupportingStreamInputWrapper@6ab5e9b7; line: 1, column: 11]"
以下是我批量写入的数据文件:
{"index":{"_index":"books","_type":"info","_id":"1"}}
{"name":"西游记","author":"吴承恩","price":"40"}
{"index":{"_index":"books","_type":"info","_id":"2"}}
{"name":"三国演义","author":"罗贯中","price":"41"}
{"index":{"_index":"books","_type":"info","_id":"3"}}
{"name":"水浒传","author":"施耐庵","price":"42"}
{"index":{"_index":"books","_type":"info","_id":"4"}}
{"name":"红楼梦","author":"曹雪芹","price":"43"}
报错分析:
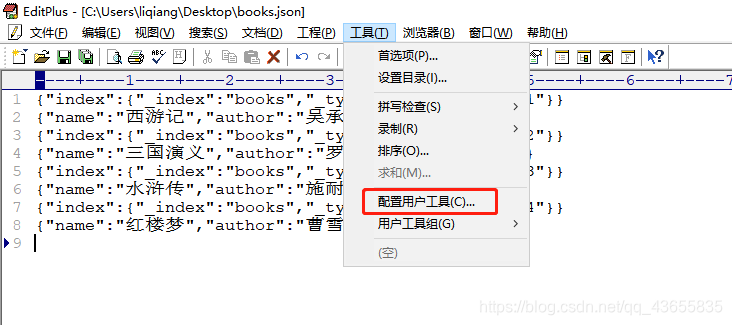
首先数据没有问题,每行数据后面我也是添加了空格(包括最后一行),从响应出来的错误数据来看是踩了字符编码的坑,我使用EditPlus编辑器查看了一下我当前的数据使用的字符集是ANSI而不是UTF-8,问题就出现在这里了。
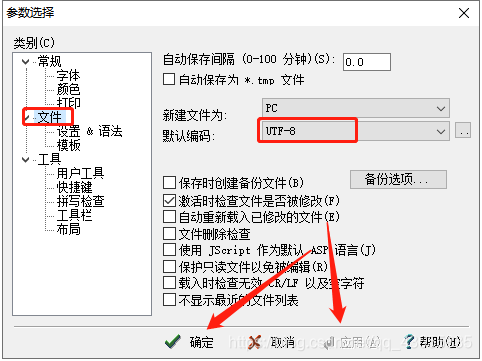
我将当前文件中的数据复制了一份,然后重新建了一个文件,并设置了字符编码为UTF-8。再重新上传到linux中并进行批量写入操作,最后成功写入。
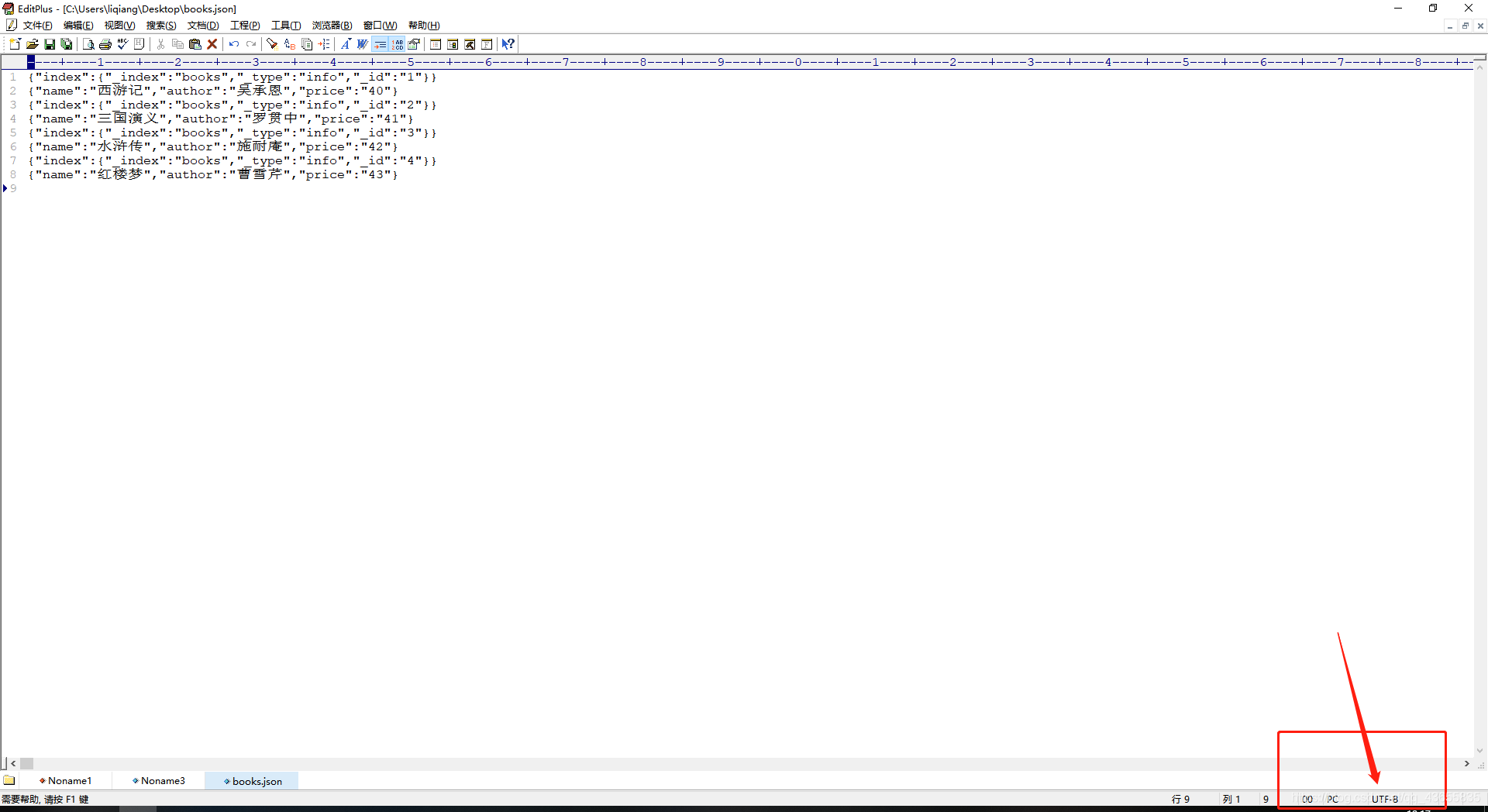
EditPlus设置字符编码: