分布式系统学习笔记
因为现在的项目大多使用了分布式技术,公司项目也有用到分布式,碰巧手头有一本之前买的分布式数据库的书,就简单读了一下,分享一下笔记。
注意⚠️:此部分是以分布式数据库的学习映射到分布式系统(javaEE方向),如果有问题欢迎指出。
个人比较喜欢纸质笔记,用闲余时间录入发布下,欢迎各位联系讨论(请注明原因)。
mail: wgh0807@qq.com
微信: hello-wgh0807
qq: 490536401
分布式系统
描述:指其组建分布在网络上,组件之间通过传递消息进行通信和动作协调的系统。
核心理念:让多台服务器协同工作,完成单台服务器无法处理的任务,尤其是高并发和大数据量的任务。
优点:
- 透明性:分布式系统对于用户来说是透明的
- 扩展性:可以根据用户需求的增加而扩展
- 可靠性:分布式系统不会出现单点失效的问题
- 高性能:是分布式系统的初衷
缺点
- 在节点通信部分开销比较大
- 线程安全问题复杂,且需要兼顾性能
- 过分依赖网络,网络信息丢失或饱和将抵消大部分优势
- 有潜在数据安全和网络安全等安全性问题
分布式数据库
主要考虑:逻辑整体性,物理分布性
主要特点:
- 透明性: 不必关心数据的逻辑分区和物理位置分布的细节,不用考虑副本一致性问题
- 数据冗余性:通过冗余实现系统的可靠性、可用性并改善其性能。
- 易于扩展性:能够方便的通过水平扩展提升整体性能
- 自治性:各个节点由本地DBMS分别管理,拥有自治能力
主要功能:目录管理、数据分片、分布式查询处理、并发控制、分布式锁管理,分布式存储,分布式网络架构,分布式安全管理
1.分布式数据库的目录管理
目录: 存放着系统元数据及数据库的元数据的全部信息
分布式数据库的目录有:全局目录、分布式目录、全局与本地混合目录
2.数据分片
当数据过于庞大,尤其是写入过于频繁,难以于一台主机支撑时,将同一个数据库实例中的数据分散存储到多个数据库实例中,进行多台设备存取以提高性能。切分数据同时可提高系统整体可用性。
常用的三种切分方式:水瓶切分、垂直切分和混合切分。
- 水平切分:按照某个字段的某种规则分散到多个节点库中,可以理解为按照数据行切分
- 垂直切分:一个数据库由多表构成,每个表对应不同业务,根据业务将表分类分布在不同主机
- 混合切分:水瓶切分和垂直切分的整合
系统压力变大是的两种解决方案:向上扩展(scale up) 和水平拓展
向上拓展:不断增加硬件性能解决问题,成本较高。
水平拓展:通过新增服务器节点数量、采取负载均衡解决问题。但当服务层足够高时,压力转化到数据库,数据库速度成为瓶颈
读写分离:把数据库的读写操作分开,以对应不同数据库服务器。主数据库提供写操作,从数据库提供读操作,有效减轻单台数据库的压力。主数据库进行些操作后,数据及时同步到所读的数据库,保证读写一致。
percona cluster - Mysql高可用性和高扩展性的解决方案
HAProxy:是一个开源的、高性能的基于TCP(第四层)和HTTP(第七层)应用的负载均衡软件,可以快速的、可靠的实现基于TCP和HTTP应用的负载均衡解决方案
keepalive:是一种基于VRRP协议实现的高可用方案,可用于避免单点故障。通常有两台及以上服务器运行keepalive,一台为主,其他的为备份服务器,对外表现为一个虚拟IP,主服务器会发送特定消息给备份服务器,当备份服务器收不到这个消息时,认为主机宕机,接管虚拟IP,继续提供服务,保证高可用性
MHA(master High Avaliability)是采用perl语言编写的一个实现Mysql高可用方案的脚本管理工具,原理是当master出现故障时,会挑选一个slave作为新的主节点,并构建新的主从关系。
Mysql优化技术-设计规范
-
Mysql字符集
- Mysql 字符集支持(character set support)涉及两个方面:字符集(character set) 和排序方式(collection)
- 对于字符集支持可以细化到4个层次:服务器(server)、数据库(database)、数据表(table)、链接(connection)
- 如果需要使用emoji表情,需要使用utf8mb4
-
命名规则
数据库命名必须遵循以下规范:
- 为数字、字母、下划线的组合,应尽量避免使用数字
- 禁止使用关键字
- 字母遵循英文简称或简写模式
- 名称尽量与英文简称或企业文化有关
表名命名必须遵循易懂,简单原则
- 是字母或字母与数字的组合,总字符数不得超过64个,建议不超过32个
- 禁止使用关键字
- 分区表允许使用下划线
- 表名遵循驼峰或下划线命名规则
- 表名称应与业务相关联,想通业务表应带有相同的表头标识,
字段命名必须遵循易懂、简单原则
- 字母或字母与数字组合,总字符数不超过64个,建议不超过32个
- 禁用关键字
- 字母遵循英文简称、简写或简写+数字格式
- 遵循驼峰规则或下划线规则。其中下划线方式需要指明是否与其他表相关。
- 饮用字段必须采用“被引用表名”+”被引用字段“格式,如User表中ID在userinfo表中被引用,则命名为user_id。特殊情况应注释
- 当一个表中存在多次引用相同表统一字段情况是,按”业务标识“+”被引用表名“+”被引用字段名“的规则命名。
- 建议总长度不超过35个
-
字段类型选择
- 应预估字段范围,能占一个字节绝不占用两个字节的原则
-
默认设置
- 主键:采用InnoDB引擎创建的表,必须拥有主键,需要设置为自增主键
- 默认值:字段只要是可能用到货未来可能用到的where条件必须非空,同时具有默认值。
-
存储引擎
默认使用InnoDB引擎,有特殊需要可使用其他搜索引擎。MyISAM支持全文搜索,在Mysql5.5中InnoDB不支持全文搜索
-
Mysql关键字
-
尽量遵循3范式
Dubbo架构发展
| 框架 | ORM(Object Relation mapping) | MVC(Model view controller) | RPC(Remote Procedure Call) | SOA(Service-Oriented Architecture) |
|---|---|---|---|---|
| 架构 | All IN ONE | VIRTUAL APPLICATION | DISTRIBUTED SERVICE | ELASTIC COMPUTING |
-
使用单一应用架构:数据访问框架(ORM)
优点:适用于小型网站,将所有的功能都集中部署于同一模块中,简单易用。
缺点:1.性能扩展较为困难;2.协同开发问题;3.不利于升级维护
-
垂直应用架构:MVC
优点:用于切分业务来实现各个模块功能独立部署,降低维护和部署难度,利于协同开发,方便性能扩展
缺点:公用模块无法重复利用
-
分布式服务架构:RPC
优点:建立与TCP连接之上,支持微服务
缺点:在凹形资源浪费,需要引入调度中心提高集群利用率
-
流动计算架构:SOA
优点:提高资源利用率,合理对资源进行调度和治理
RPC:Remote Procedure Call 远程过程调用
指像调用本地过程一样调用远程计算机上的运行过程
两个核心模块:通讯和序列化
dubbo是一款高性能、轻量级的javaRPC框架,提供三大能力:面向接口的进程方法调用;智能容错和负载均衡,提供自动注册和发现功能。
主要包含5种角色:
- 容器:用于容纳和启动提供者
- 提供者:暴露服务的提供者,在启动时像注册中心注册自己的服务
- 消费者:调用远程服务的远程消费方,启动时像注册中心订阅自己所需要的服务,从提供者列表中给予软负载均衡算法,选一台提供者进行调用。若调用失败,则调用另一个。
- 注册中心:注册中心返回服务提供者地址给消费者,如有变更,注册中心将基于长链接推送变更地址给服务器。
- 监控中心:消费者和提供者在内存中累积调用次数和时间,每分钟向监控中心发送一次。
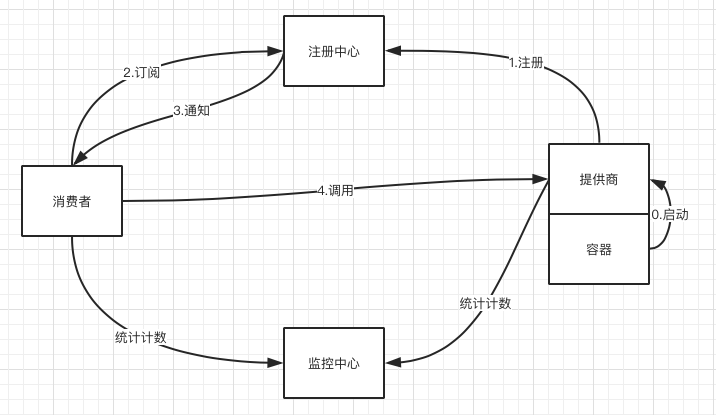
zookeeper工作流程:
- 容器启动服务提供商
- 服务提供商向注册中心注册自己提供的服务
- 消费者向注册中心订阅自己需要的服务
- 注册中心将消费者订阅的服务地址下发给消费者吧,并基于长链接将服务变动推送给消费者
- 消费者根据服务地址对提供商进行调用
- 消费者和服务者在各自内存中累积调用次数和时间,每分钟发给监控中心进行监听和计数工作。
一种机制 -> 选举机制:(多个注册中心时)为了选举leader节点,方便且效率较高,推荐选用奇数个主机,效率较高。选举效果生效后,leader不出问题是不需要进行选举。