sys模块
这是一个跟python解释器关系密切的标准库。它提供了一些和python解释器操作密切的属性和函数。
sys中常用的函数和属性:
sys.argv:
sys.argv是专门用来向python解释器传递参数的,称为“命令行参数”。它的返回值是一个列表,列表中的元素依次是文件名、参数1、参数2……
macdeMacBook-Pro:~ mac$ python3 test.py ['test.py'] macdeMacBook-Pro:~ mac$ python3 test.py aa bb cc # 参数之间用空格隔开 ['test.py', 'aa', 'bb', 'cc'] # 文件名和参数的列表
sys.exit():
这个方法的作用是退出当前程序。
Help on built-in function exit in module sys:
exit(...)
exit([status])
Exit the interpreter by raising SystemExit(status).
If the status is omitted or None, it defaults to zero (i.e., success).
If the status is an integer, it will be used as the system exit status.
If it is another kind of object, it will be printed and the system
exit status will be one (i.e., failure).
在大多数函数中会用到return,其含义是终止当前的函数,并向调用位置返回相应值。而sys.exit()的含义是退出当前程序(不仅仅是退出当前函数),并发起SystemExit异常。如果使用sys.exit(0)表示正常退出;如果在退出的是需要打印一些内容,则可以使用sys.exit('我退出啦!')的形式,即向exit()方法中传入字符串参数。
import sys for i in range(5): if i == 3: sys.exit(0) # 正常退出 else: print(i, end=' ') python3 test.py # 执行文件 0 1 2 for i in range(5): if i == 3: sys.exit('aaaaa') # 退出并打印提示信息 else: print(i, end=' ') python3 test.py # 执行文件 0 1 2 aaaaa # 提示信息也被打印出来了
sys.path:
它可以查找模块所在的目录,以列表的形式显示出来。用append()方法,能够向这个列表增加新的模块目录。
>>> import sys >>> print(sys.path) ['', '/Library/Frameworks/Python.framework/Versions/3.7/lib/python37.zip', '/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7', '/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/lib-dynload', '/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages']
copy模块
这个模块中常用的就是copy和deepcopy两个方法。copy是浅拷贝,deepcopy是深拷贝。
os模块
os模块是与操作系统交互的一个接口。
操作命令:
os.getcwd():获取当前工作目录,即当前python脚本工作的路径。 os.chdir("dirname"):改变当前脚本工作目录,相当于shell下cd。 os.curdir:返回当前目录: ('.')。 os.pardir:获取当前目录的父目录字符串名:('..')。 os.makedirs('dirname1/dirname2'):递归生成多层目录。 os.removedirs('dirname1'):若目录为空,则删除,并递归到上一级目录,若也为空,则删除,依此类推。若目录不为空,则不删除。 os.mkdir('dirname'):生成单级目录。 os.rmdir('dirname'):删除单级空目录,若目录不为空则无法删除,报错。 os.listdir('dirname'):列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印。 os.remove():删除一个文件。 os.rename("oldname","newname"):重命名文件/目录。 os.stat('path/filename'):获取文件/目录信息。 os.sep:输出操作系统特定的路径分隔符,win下为"\",Linux下为"/"。 os.linesep:输出当前平台使用的行终止符,win下为" ",Linux下为" "。 os.pathsep:输出用于分割文件路径的字符串 win下为;,Linux下为:。 os.name:输出字符串指示当前使用平台。win->'nt'; Linux->'posix'。 os.system("bash command"):运行shell命令,直接显示。 os.environ:获取系统环境变量。 os.path.abspath(path):返回path规范化的绝对路径。 os.path.split(path):以元组的形式将path分割成的目录和文件名返回。 os.path.dirname(path):返回path的目录。其实就是os.path.split(path)的第一个元素。 os.path.basename(path):返回path最后的文件名。如果path以/或结尾,那么就会返回空值。即os.path.split(path)的第二个元素。 os.path.exists(path):如果path存在,返回True;如果path不存在,返回False。 os.path.isabs(path):如果path是绝对路径,返回True。 os.path.isfile(path):如果path是一个存在的文件,返回True。否则返回False。 os.path.isdir(path):如果path是一个存在的目录,则返回True。否则返回False。 os.path.join(path1[, path2[, ...]]):将多个路径组合后返回,第一个绝对路径之前的参数将被忽略。 os.path.getatime(path):返回path所指向的文件或者目录的最后存取时间。 os.path.getmtime(path):返回path所指向的文件或者目录的最后修改时间。 os模块中提供可以操作系统命令的方法,如os.system()、os.exec()、os.execvp()。 >>> p = '/Users/mac' >>> command = 'ls ' + p # 将命令以字符串的形式连接 >>> command 'ls /Users/mac' >>> os.system(command) # 执行系统命令 Desktop Movies PycharmProjects Documents Music Virtual Machines.localized Downloads Pictures __pycache__ Library Public test.py
os模块中不论rmdir还是removedirs都不能直接删除非空目录。要直接删除非空目录,可以使用模块shutil的rmtree()方法。
堆模块
堆是计算机科学中一类特殊的数据结构的统称,通常是一个可以被看作一棵树的数组对象。
在计算机科学中,二叉树是每个节点最多有两个子树的树结构。通常子树被称为左子树和右子树。并不是所有的节点都有两个子节点,称每个节点都有两个子节点的二叉树为完全二叉树。
堆模块中的二叉树结构特点:
节点的值大于等于(或小于等于)任何子节点的值。
节点左子树和右子树是一个二叉堆,如果父节点的值总是大于等于任何子节点的值,则为最大堆;否则为最小堆。
heapq模块:
>>> import heapq >>> heapq.__all__ ['heappush', 'heappop', 'heapify', 'heapreplace', 'merge', 'nlargest', 'nsmallest', 'heappushpop'] heapq.heappush(heap, x): Help on built-in function heappush in module _heapq: heappush(...) heappush(heap, item) -> None. Push item onto heap, maintaining the heap invariant. heappush()函数自动按照二叉树的结构将数据放到堆里面进行存储。 >>> import heapq >>> heap = [] >>> heapq.heappush(heap, 2) >>> heapq.heappush(heap, 3) >>> heapq.heappush(heap, 9) >>> heapq.heappush(heap, 6) >>> heapq.heappush(heap, 5) >>> heapq.heappush(heap, 0) >>> heap [0, 3, 2, 6, 5, 9] # 最小堆 heapq.heappop(heap): Help on built-in function heappop in module _heapq: heappop(...) Pop the smallest item off the heap, maintaining the heap invariant. 这个函数是从heap堆中删除一个最小的元素,并返回该值。删除元素后,将会按照完全二叉树的规范重新排列原堆。 >>> heapq.heappop(heap) # 删除堆中最小的值 0 >>> heap # 按照完全二叉树的规范重新排列原堆 [2, 3, 9, 6, 5] heapq.heapify(lst): Help on built-in function heapify in module _heapq: heapify(...) Transform list into a heap, in-place, in O(len(heap)) time. 将一个列表转化为堆。 >>> lst = [2, 3, 5, 6, 8, 0, 9, 1] >>> heapq.heapify(lst) # 将列表ls转化为堆 >>> lst # 堆 [0, 1, 2, 3, 8, 5, 9, 6] heapq.heapreplace(heap, x): Help on built-in function heapreplace in module _heapq: heapreplace(...) heapreplace(heap, item) -> value. Pop and return the current smallest value, and add the new item. This is more efficient than heappop() followed by heappush(), and can be more appropriate when using a fixed-size heap. Note that the value returned may be larger than item! That constrains reasonable uses of this routine unless written as part of a conditional replacement: if item > heap[0]: item = heapreplace(heap, item) 这是heappop()和heappush()的联合,也就是删除一个,同时加入一个,即替代。 >>> heap [2, 3, 9, 6, 5] >>> heapq.heapreplace(heap, 3.3) # 替代 2 >>> heap # 按照完全二叉树规则重新排列 [3, 3.3, 9, 6, 5]
deque模块
对于一个列表,可以用append方法向其末尾增加值,如果要向其首位增加值呢?可以使用collections下的deque模块。
>>> from collections import deque >>> lst = [2, 5, 7, 9] >>> dlst = deque(lst) # 必须先将列表转化为deque对象 >>> dlst # deque对象 deque([2, 5, 7, 9]) >>> dlst.append(12) # 添加到末尾 >>> dlst deque([2, 5, 7, 9, 12]) >>> dlst.appendleft(15) # 添加到首位 >>> dlst deque([15, 2, 5, 7, 9, 12]) >>> dlst.pop() # 删除末尾值 12 >>> dlst deque([15, 2, 5, 7, 9]) >>> dlst.popleft() # 删除首位值 15 >>> dlst deque([2, 5, 7, 9])
deque.rotate()方法实现列表的轮转。rotate()中传入整数,若为正整数,则顺时针旋转;若为负整数,则逆时针旋转。旋转方式是将原列表的deque对象首位连接成一个圆,列表的第一个值就是当前值。
>>> dlst deque([2, 5, 7, 9]) >>> dlst.rotate(3) # 顺时针旋转3个位置 >>> dlst deque([5, 7, 9, 2]) >>> dlst.rotate(-1) # 逆时针旋转一个位置 >>> dlst deque([7, 9, 2, 5])
calendar模块
month(year, month, w=2, l=1):
返回year年month月的日历,两行标题,一周一行。每日宽度间隔为w字符,每行的长度为7*w+6,l是每星期的行数。
>>> import calendar >>> cal = calendar.month(2018, 10) >>> print(cal) October 2018 Mo Tu We Th Fr Sa Su 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
calendar(year, w=2, l=1, c=6):
返回year年的年历,3个月一行,间隔距离为c。每日宽度间隔为w个字符,每行长度为21*w+18+2*c,l是每星期行数。
isleap(year):
判断是否为闰年,是则返回True,否则返回False。
>>> calendar.isleap(2018) False >>> calendar.isleap(2012) True
leapdays(y1, y2):
返回y1、y2两年之间的闰年总数,包括y1,但不包括y2。
>>> calendar.leapdays(2000, 2020)
5
monthcalendar(year, month):
返回一个列表,列表内的元素还是列表。每个子列表代表一个星期,都是从星期一到星期日七个元素,如果没有本周的日期,则为0。
>>> calendar.monthcalendar(2018, 10) [[1, 2, 3, 4, 5, 6, 7], [8, 9, 10, 11, 12, 13, 14], [15, 16, 17, 18, 19, 20, 21], [22, 23, 24, 25, 26, 27, 28], [29, 30, 31, 0, 0, 0, 0]] # 用0填充
monthrange(year, month):
返回一个元组,里面有两个整数。第一个整数代表着该月的第一天从星期几开始(从0开始依次为星期一、星期二……直到6代表星期日)。第二个整数代表该月一共有多少天。
>>> calendar.monthrange(2018, 10) (0, 31) # 2018年10从星期一开始,共有31天 >>> calendar.monthrange(2018, 11) (3, 30) # 2018年11从星期四开始,共有30天
weekday(year, month, day):
输入年月日,返回该日是星期几(返回值从0开始依次为星期一、星期二……直到6代表星期日)。
>>> calendar.weekday(2018, 10, 23) 1 # 星期二 >>> calendar.weekday(2018, 10, 31) 2 # 星期三
time模块
time():
获得当前的时间戳,它是以1970年1月1日0时0分0秒为计时起点到当前的秒数。
>>> time.time()
1540883899.987189
localtime():
返回一个本地时间元组。
>>> time.localtime()
time.struct_time(tm_year=2018, tm_mon=10, tm_mday=30, tm_hour=15, tm_min=21, tm_sec=24, tm_wday=1, tm_yday=303, tm_isdst=0)
元组中各项含义如下表所示。
|
索引 |
属性 |
含义 |
|
0 |
tm_year |
年 |
|
1 |
tm_mon |
月 |
|
2 |
tm_mday |
日 |
|
3 |
tm_hour |
时 |
|
4 |
tm_min |
分 |
|
5 |
tm_sec |
秒 |
|
6 |
tm_wday |
一周中的第几天 |
|
7 |
tm_yday |
一年中的第几天 |
|
8 |
tm_isdst |
夏令时 |
time.localtime()是可以有参数的,只是它默认以time.time()的时间戳为参数。我们可以给它传入一个时间戳作为参数,它将返回该时间戳对应的时间元组。
>>> time.localtime(1200060000) # 传入一个时间戳 time.struct_time(tm_year=2008, tm_mon=1, tm_mday=11, tm_hour=22, tm_min=0, tm_sec=0, tm_wday=4, tm_yday=11, tm_isdst=0)
gmtime():
localtime()得到的是本地时间,而gmtime()得到的是国际化的格林尼治时间,它的结构和本地时间一致。
>>> time.gmtime()
time.struct_time(tm_year=2018, tm_mon=10, tm_mday=30, tm_hour=7, tm_min=37, tm_sec=18, tm_wday=1, tm_yday=303, tm_isdst=0)
asctime():
>>> time.asctime() 'Tue Oct 30 15:41:01 2018'
time.asctime()的参数为空时,默认使用本地时间time.localtime()的时间元组格式为参数,返回当前的星期、月、日、时间、年,显示相对友好。也可自己传入参数,但传入的参数必须是时间元组的格式。
>>> time.asctime(time.localtime(1200060000)) 'Fri Jan 11 22:00:00 2008'
ctime():
>>> time.ctime() 'Tue Oct 30 15:46:24 2018'
ctime()的用法、返回值和asctime()一致,不同在于asctime()是以时间元组为参数,而ctime()是以时间戳为参数。ctime()默认传入time.time()定义的时间戳,也可自己传入时间戳参数。
>>> time.ctime(1200060000) 'Fri Jan 11 22:00:00 2008'
mktime():
mktime()可以看作是localtime()的逆过程,是将时间元组格式转换为时间戳的格式。
>>> time.mktime(time.localtime())
1540886368.0
strftime():
Help on built-in function strftime in module time:
strftime(...)
strftime(format[, tuple]) -> string
Convert a time tuple to a string according to a format specification.
See the library reference manual for formatting codes. When the time tuple is not present, current time as returned by localtime() is used.
将时间元组按照指定的格式转换为字符串,如果不指定时间元组,就默认为当前的localtime()值。
>>> time.strftime('%Y-%m-%d') # 分隔符可以自由指定 '2018-10-30' >>> time.strftime('%Y/%m/%d') '2018/10/30' >>> time.strftime('%Y/%m/%d', time.localtime(1200060000)) '2008/01/11'
时间字符串格式
|
格式 |
含义 |
取值范围(格式) |
|
%y |
去掉世纪的年份 |
00~99,如18 |
|
%Y |
完整的年份 |
如2018 |
|
%j |
指定日期是一年中的第几天 |
001~366 |
|
%m |
返回月份 |
01~12 |
|
%b |
本地简化月份的名称 |
简写英文月份 |
|
%B |
本地完整月份的名称 |
完整英文月份 |
|
%d |
该月的第几日 |
如5月1日返回01 |
|
%H |
该日的第几时(24小时制) |
00~23 |
|
%l |
该日的第几时(12小时制) |
01~12 |
|
%M |
分钟 |
00~59 |
|
%S |
秒 |
00~59 |
|
%U |
该年中的第几个星期(以周日为一周起点) |
00~53 |
|
%W |
同上,以周一为一周的起点 |
00~53 |
|
%w |
一星期中的第几天 |
0~6 |
|
%Z |
时区 |
在中国大陆测试返回CST,即China Standard Time |
|
%x |
日期 |
日/月/年 |
|
%X |
时间 |
时:分:秒 |
|
%c |
详细日期时间 |
日/月/年时:分:秒 |
|
%% |
%字符 |
%字符 |
|
%p |
上下午 |
AM或PM |
strptime():
是strftime()的逆过程,将字符串格式化时间转换为时间元组的形式。
Help on built-in function strptime in module time:
strptime(...)
strptime(string, format) -> struct_time
Parse a string to a time tuple according to a format specification.
See the library reference manual for formatting codes (same as strftime()).
strptime()要传入两个参数,第一个参数是字符串格式化时间,第二个参数是与传入的字符串格式化时间相对应的格式,即传入的字符串格式化时间的格式是什么,第二个参数传入的格式就要完全与其对应。
>>> today = time.strftime('%Y-%m-%d %H:%M:%S') >>> today '2018-10-30 16:56:13' >>> time.strptime(today, '%Y-%m-%d %H:%M:%S') time.struct_time(tm_year=2018, tm_mon=10, tm_mday=30, tm_hour=16, tm_min=56, tm_sec=13, tm_wday=1, tm_yday=303, tm_isdst=-1)
datetime模块
datetime模块中有以下几个类。
date:日期类,常用的属性有year/month/day。
time:时间类,常用的有hour/minute/second/microsecond。
datetime:日期时间类。
timedelta:时间间隔,即两个时间点之间的时间长度。
tzinfo:时区类。
date类
>>> [item for item in dir(datetime.date) if not item.startswith('_')] ['ctime', 'day', 'fromisoformat', 'fromordinal', 'fromtimestamp', 'isocalendar', 'isoformat', 'isoweekday', 'max', 'min', 'month', 'replace', 'resolution', 'strftime', 'timetuple', 'today', 'toordinal', 'weekday', 'year']
可以看到date类中有很多的方法和属性,就几个常用的作简单介绍。
>>> td = datetime.date.today() # 生成一个日期对象 >>> td # 可以利用这个日期对象操作各种属性和方法 datetime.date(2018, 10, 30) >>> print(td) # 以字符串的形式打印日期 2018-10-30 >>> print(td.ctime()) # 调用对象的ctime()方法,将日期转换为星期、月、日、时间、年 Tue Oct 30 00:00:00 2018 >>> print(td.timetuple()) # 调用对象的timetuple()方法,将日期转换为时间元组 time.struct_time(tm_year=2018, tm_mon=10, tm_mday=30, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=1, tm_yday=303, tm_isdst=-1) >>> print(td.toordinal()) # 调用对象的toordinal()方法,将日期转换为ordinal时间 736997 >>> print(td.year) # 调用对象的year属性,取出日期对象的年 2018 >>> print(td.month) # 调用对象的month属性,取出日期对象的月 10 >>> print(td.day) # 调用对象的day属性,取出日期对象的日 30 >>> print(datetime.date.fromordinal(736997)) # 调用对象的fromordinal()方法, 2018-10-30 # 将ordinal时间转换为字符格式的时间 >>> print(datetime.date.fromtimestamp(time.time())) # 调用date类的 2018-10-30 # fromtimestamp()方法将时间戳转换为字符格式的时间 >>> d1 = datetime.date(2018, 10, 29) # 实例化date类对象 >>> d1 datetime.date(2018, 10, 29) >>> print(d1) 2018-10-29 >>> d2 = d1.replace(year=2008, day=9) # 调用对象的replace()方法,修改日期 >>> print(d2) # 并返回一个新的已修改的日期对象 2008-10-09
time类
>>> [item for item in dir(datetime.time) if not item.startswith('_')] ['dst', 'fold', 'fromisoformat', 'hour', 'isoformat', 'max', 'microsecond', 'min', 'minute', 'replace', 'resolution', 'second', 'strftime', 'tzinfo', 'tzname', 'utcoffset'] 可以看到time类中有很多的方法和属性,就几个常用的作简单介绍。 >>> tm = datetime.time(1, 2, 3) # 生成time类对象 >>> tm datetime.time(1, 2, 3) >>> print(tm) 01:02:03 >>> print(tm.hour) # 调用对象的hour属性,取出时间对象的时 1 >>> print(tm.minute) # 调用对象的minute属性,取出时间对象的分 2 >>> print(tm.second) # 调用对象的second属性,取出时间对象的秒 3 >>> print(tm.tzinfo) # 调用对象的tzinfo属性,取出时间对象的时区信息 None
timedelta类
timedelta类主要是用来做时间的运算。
>>> now = datetime.datetime.now() # 获取当前时间 >>> print(now) 2018-10-30 20:59:34.799856 >>> b = now + datetime.timedelta(hours=5) # 对now增加5小时 >>> print(b) 2018-10-31 01:59:34.799856 >>> c = now + datetime.timedelta(weeks=2) # 对now增加两周 >>> print(c) 2018-11-13 20:59:34.799856 >>> d = c - b # 计算时间差 >>> print(d) 13 days, 19:00:00
random模块
random.random():0-1之间的随机浮点数,不包含0和1。
random.randint(a, b):a和b之间的任意整数,包含a和b。
random.randrange(a, b):a和b之间的任意整数,包含a,不包含b。
random.uniform(a, b):a和b之间的任意浮点数。
random.shuffle(item):将可迭代对象item中的顺序打乱,原地修改,没有返回值。
xml.etree.ElementTree模块(处理XML)
XML的定义:
XML指可扩展标记语言(EXtensible Markup Language);
XML是一种标记语言,类似HTML;
XML的设计宗旨是传输数据,而非显示数据;
XML标签没有被预定义,而需自行定义标签;
XML被设计为具有自我描述特性。
python提供了多种模块来处理XML,下面介绍xml.etree.ElementTree(简称ET):元素树。
先做一个XML文档,基于此文档练习。
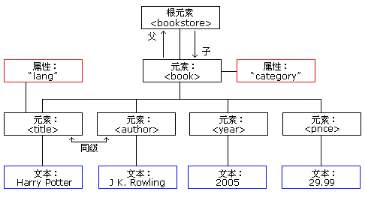
这是一棵树,写成XML文档格式:
<bookstore> <book category="COOKING"> <title lang="en">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price> </book> <book category="CHILDREN"> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> <book category="WEB"> <title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price>39.95</price> </book> </bookstore>
以上的XML文档,保存并命名为web.xml文件。利用python中的模块进行处理。
>>> import xml.etree.ElementTree as ET >>> tree = ET.ElementTree(file='web.xml') # 建立XML解析树对象 >>> tree <xml.etree.ElementTree.ElementTree object at 0x10b545828>
建立起XML解析树对象,然后通过根节点向下开始读取各个元素对象。
在上述的XML文档中,根元素是bookstore,它没有属性,或者属性为空。 >>> root = tree.getroot() # 通过对象获取根节点 >>> root.tag # 根节点的标签名 'bookstore' >>> root.attrib # 根节点的属性 {} 通过如下的操作,将根节点下面的元素都读出来。 >>> for child in root: # 获取根节点下面的一级子节点 ... print(child.tag, child.attrib) ... book {'category': 'COOKING'} book {'category': 'CHILDREN'} book {'category': 'WEB'} 也可以这样读取指定元素的信息: >>> root[0].tag # 获取根节点下一级子节点的信息 'book' >>> root[0].attrib {'category': 'COOKING'} >>> root[0].text # 没有内容 ' ' 再深入一层,获取子孙节点的信息: >>> root[0][0].tag # 子孙节点的信息 'title' >>> root[0][0].attrib {'lang': 'en'} >>> root[0][0].text 'Everyday Italian' 对于ElementTree对象,有一个iter()方法可以对指定名称的子节点进行深度优先遍历。 >>> for ele in tree.iter(tag='book'): # 遍历名称为book的节点 ... print(ele.tag, ele.attrib) ... book {'category': 'COOKING'} book {'category': 'CHILDREN'} book {'category': 'WEB'} >>> for ele in tree.iter(tag='title'): # 遍历名称为title的节点 ... print(ele.tag, ele.attrib, ele.text) ... title {'lang': 'en'} Everyday Italian title {'lang': 'en'} Harry Potter title {'lang': 'en'} Learning XML 如果不指定元素名称,就是将所有的元素遍历一遍。 >>> for ele in tree.iter(): # 不指定元素名称,遍历所有元素 ... print(ele.tag, ele.attrib) ... bookstore {} book {'category': 'COOKING'} title {'lang': 'en'} author {} year {} price {} book {'category': 'CHILDREN'} title {'lang': 'en'} author {} year {} price {} book {'category': 'WEB'} title {'lang': 'en'} author {} year {} price {} 通过路径搜索到指定的元素,读取其内容,类似于xpath。 >>> for ele in tree.iterfind('book/title'): # 通过路径搜索到指定的元素 ... print(ele.text) ... Everyday Italian Harry Potter Learning XML 利用findall()方法,也可以实现查找功能。 >>> for ele in tree.findall('book'): ... title = ele.find('title').text ... price = ele.find('price').text ... lang = ele.find('title').attrib ... print(title, price, lang) ... Everyday Italian 30.00 {'lang': 'en'} Harry Potter 29.99 {'lang': 'en'} Learning XML 39.95 {'lang': 'en'} 除了读取有关数据,还能对XML进行编辑,即增、删、改、查功能。 >>> root[1].tag 'book' >>> del root[1] # 删除一个节点 >>> for ele in root: ... print(ele.tag) ... book book
成功删除了一个节点,原来有三个book节点,现在就剩下两个了。但是源文件里却并没有删除节点,这是因为至此的修改还是停留在内存中,还没有将修改的结果输出到文件。我们是在内存中创建的ElementTree对象,对此对象进行操作的。
可以这样做,将修改后的内容保存到文件中。 >>> import os >>> outpath = os.getcwd() >>> file = outpath + 'web.xml' # 拼接当前文件路径 >>> tree.write(file) # 修改后的内容写入文件保存 上面是用del来删除某个元素,在编程中,更多的会用remove()方法来执行删除操作。 >>> for book in root.findall('book'): ... price = book.find('price').text ... if float(price) > 40: # 删除价格大于40的标签 ... root.remove(book) ... >>> for price in root.iter('price'): ... print(price.text) # 价格大于40的标签被删除 ... 37.0 除了删除,还可以修改内容。 >>> for price in root.iter('price'): # 原来的内容 ... print(price.text) ... 30.00 39.95 >>> for price in root.iter('price'): # 修改后的内容,价格上涨7元 ... new_price = float(price.text) + 7 ... price.text = str(new_price) ... price.set('updated', 'up') # 设置属性 ... >>> for price in root.iter('price'): ... print(price.text) ... 37.0 46.95 增加元素。 >>> for ele in root: ... print(ele.tag) ... book # 原文件里只有一个book标签 >>> ET.SubElement(root, 'book') # 在root里面添加book节点 <Element 'book' at 0x1022f5f98> >>> for ele in root: ... print(ele.tag) ... book book # 新增的book节点 >>> b = root[1] # 得到新增的book节点 >>> b.text = 'python' # 添加内容 >>> for ele in root: ... print(ele.tag, ele.text) ... book book python # 添加的内容 自己创建XML文档 import xml.etree.ElementTree as ET new_xml = ET.Element("namelist") name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"}) age = ET.SubElement(name,"age",attrib={"checked":"no"}) sex = ET.SubElement(name,"sex") sex.text = '33' name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"}) age = ET.SubElement(name2,"age") age.text = '19' et = ET.ElementTree(new_xml) #生成文档对象 et.write("test.xml", encoding="utf-8",xml_declaration=True) ET.dump(new_xml) #打印生成的格式 创建xml文档
ET里常用的属性和方法总结:
Element对象
常用属性如下。 tag:string,元素数据种类。 text:string,元素的内容。 attrib:dictionary,元素的属性字典。 tail:string,元素的尾形。 针对属性的操作如下。 clear():清空元素的后代、属性、text和tail也设置为None。 get(key, default=None):获取key对应的属性值,如果该属性不存在,则返回default值。 items():根据属性字典返回一个列表,列表元素为(key, value)。 keys():返回包含所有元素属性键的列表。 set(key, value):设置新的属性键与值。 针对后代的操作如下。 append(subelement):添加直系子元素。 extend(subelements):增加一串元素对象作为子元素。 find(match):寻找第一个匹配子元素,匹配对象可以为tag或path。 findall(match):寻找所有匹配子元素,匹配对象可以为tag或path。 findtext(match):寻找第一个匹配子元素,返回其text值,匹配对象可以为tag或path。 insert(index, element):在指定位置插入子元素。 iter(tag=None):生成遍历当前元素所有后代或者给定tag的后代的迭代器。 iterfind(match):根据tag或path查找所有的后代。 itertext():遍历所有后代并返回text值。 remove(subelement):删除子元素。
ElementTree对象
find(match)。 findall(match)。 findtext(match, default=None)。 getroot():获取根节点。 iter(tag=None)。 iterfind(match)。 parse(source, parser=None):装载XML对象,source可以为文件名或文件类型对象。 write(file, encoding=’us-ascii’, xml_declaration=None, default_namespace=None, method=’xml’)。
JSON模块
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML。但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:
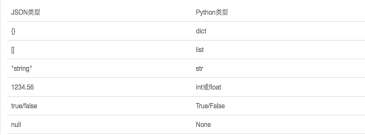
就传递数据而言,XML是一种选择,JSON也是一种选择。JSON是一种轻量级的数据交换格式,可以在任何语言之间进行数据的传递。
JSON建构于两种结构:
“名称/值”对的集合(A collection of name/value pairs)。不同的语言中,它被理解为对象(object),纪录(record),结构(struct),字典(dictionary),哈希表(hash table),有键列表(keyed list),或者关联数组 (associative array)。
值的有序列表(An ordered list of values)。在大部分语言中,它被理解为数组(array)。
python标准库中有JSON模块,主要执行序列化和反序列化功能,实现不同语言的数据类型和json数据类型之间的转换。
序列化:
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
序列化:encoding,把一个python对象编码转换为JSON字符串;
反序列化:decoding,把JSON格式字符串解码转换为python数据对象。
基本操作:
>>> import json >>> json.__all__ ['dump', 'dumps', 'load', 'loads', 'JSONDecoder', 'JSONDecodeError', 'JSONEncoder'] 1. encoding:dumps() >>> data = [{'name': 'xx', 'lang': ('python', 'java'), 'age': 22}] >>> data [{'name': 'xx', 'lang': ('python', 'java'), 'age': 22}] >>> data_json = json.dumps(data) >>> data_json '[{"name": "xx", "lang": ["python", "java"], "age": 22}]'
encoding的操作比较简单,注意观察data和data_json的区别,lang的值从元组变成了列表;data中的元素不论是以双引号还是单引号,json的dumps都会处理为双引号。即json会先将原数据中的单引号变成双引号,然后将整个数据包装成符合json格式的字符串。二者的类型也有区别。
>>> type(data) <class 'list'> >>> type(data_json) # json的dumps将传入的数据转换为了符合json格式的字符串类型 <class 'str'> 2. decoding:loads() >>> new_data = json.loads(data_json) >>> new_data [{'name': 'xx', 'lang': ['python', 'java'], 'age': 22}] # lang的值依然是列表,没有转回元组 >>> type(new_data) <class 'list'> JSON的dumps()提供了可选参数,能够在输出上更友好。 >>> data_j = json.dumps(data, sort_keys=True, indent=2) >>> print(data_j) [ { "age": 22, "lang": [ "python", "java" ], "name": "xx" } ]
sort_keys=True, 意思是按照键的字典顺序排序;indent=2是让每个键值对显示的时候,以缩进两个字符对齐。
pickle模块
pickle模块的使用方法和用途和json完全一致,pickle中的函数名称和用法和json也完全一致。区别在于pickle支持更多的数据类型:支持类,而json不支持类。除此之外,pickle的dumps将数据转换为bytes类型,而json的dumps将数据转换为json字符串类型。pickle只适用于python,而json适用于所有语言。
# 序列化 import pickle dic={'name':'alvin','age':23,'sex':'male'} print(type(dic)) <class 'dict'> j=pickle.dumps(dic) print(type(j)) <class 'bytes'> f=open('序列化对象_pickle','wb') # 注意是w是写入str,wb是写入bytes,j是'bytes' f.write(j) # 等价于pickle.dump(dic,f) f.close() # 反序列化 import pickle f=open('序列化对象_pickle','rb') data=pickle.loads(f.read()) # 等价于data=pickle.load(f) print(data['age'])
Pickle的问题和所有其他编程语言特有的序列化问题一样,它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。