爬取并写入MySQL中
import pymysql
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/80.0.3987.163 Safari/537.36 '
}
connect = pymysql.Connect(
host='localhost',
port=3306,
user='root',
passwd='root',
db='python',
charset='utf8'
)
# 获取游标
cursor = connect.cursor()
def toMySQL(imgBlob, titleSQL, starringSQL, releaseTimeSQL, scoreSQL):
print(requests.get(imgBlob).content)
print(imgBlob)
print(titleSQL)
print(starringSQL[3:])
print(releaseTimeSQL[5:])
print(scoreSQL)
insertSql = """INSERT INTO `python`.`maoyan`(`img`, `title`, `starring`, `release_time`, `score`) VALUES ('{a}','{b}','{c}','{d}','{e}')"""
cursor.execute(
insertSql.format(a=r'' + str(requests.get(imgBlob).content), b=titleSQL, c=starringSQL[3:], d=releaseTimeSQL[5:],
e=scoreSQL))
print("------------------执行了插入")
connect.commit()
def mingzihaonanqi(page):
url = 'https://maoyan.com/board/4?offset=' + str(page)
res = requests.get(url, headers=headers)
# 页面session失效, 需要重新验证, 打印出来方便使用
print(res.url)
# 打印出页面的所有代码
# print(res.text)
soup = BeautifulSoup(res.text, 'html.parser')
ResultSets = soup.find_all('dd')
for resultSet in ResultSets:
tag = resultSet
soupTag = BeautifulSoup(str(tag), 'html.parser')
Title = soupTag.find('a').get('title')
imgSrc = soupTag.find('img', class_='board-img').get('data-src')
starring = soupTag.find('p', class_='star').text.strip()
releaseTime = soupTag.find('p', class_='releasetime').text.strip()
score = soupTag.find('p', class_='score').text.strip()
toMySQL(imgSrc, Title, starring, releaseTime, score)
print(str(page) + "----------")
if __name__ == '__main__':
for i in range(30, 100, 10):
print(i) # 0 10 20 ````
mingzihaonanqi(i)
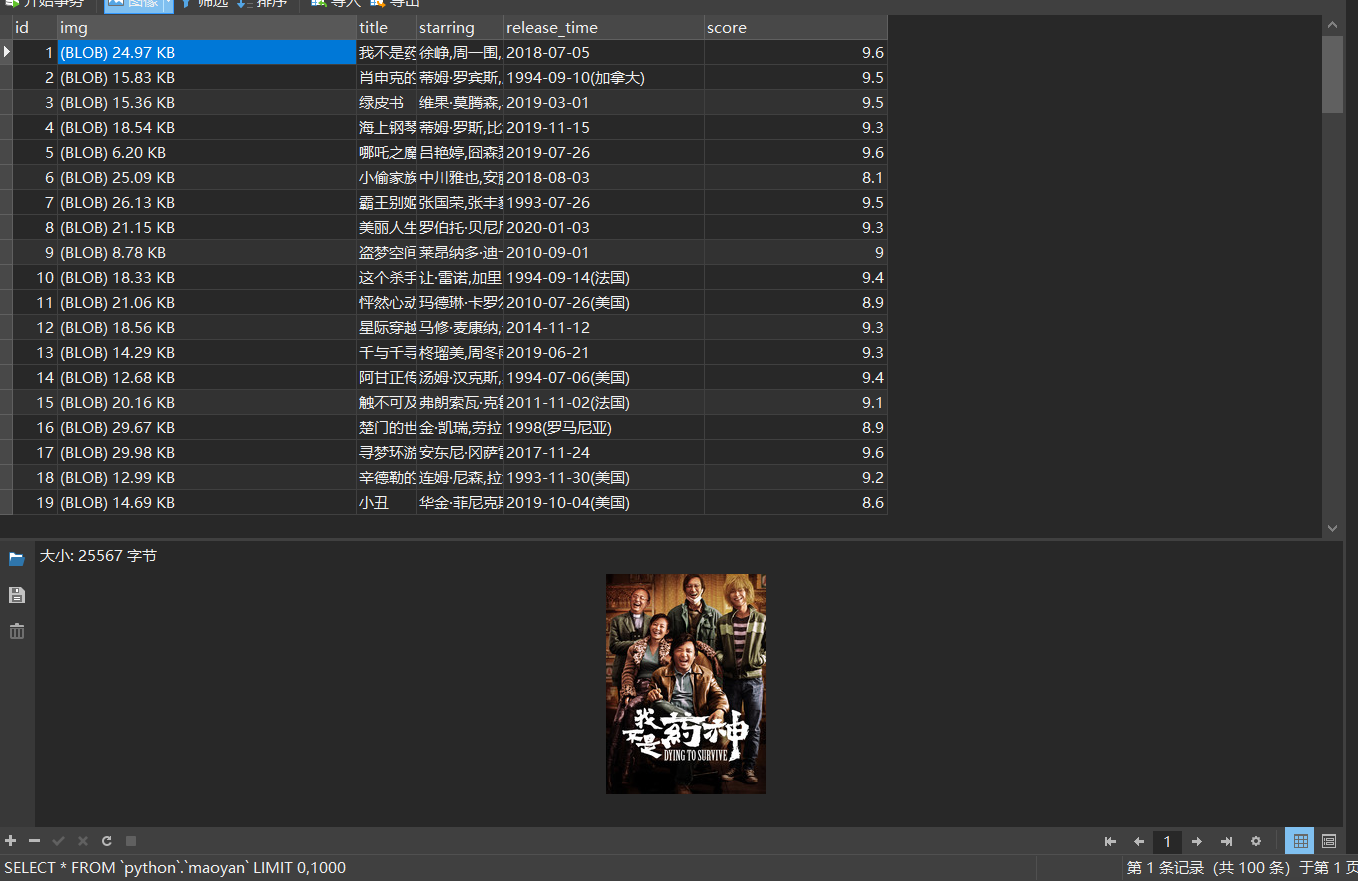
库表信息

运行结果:
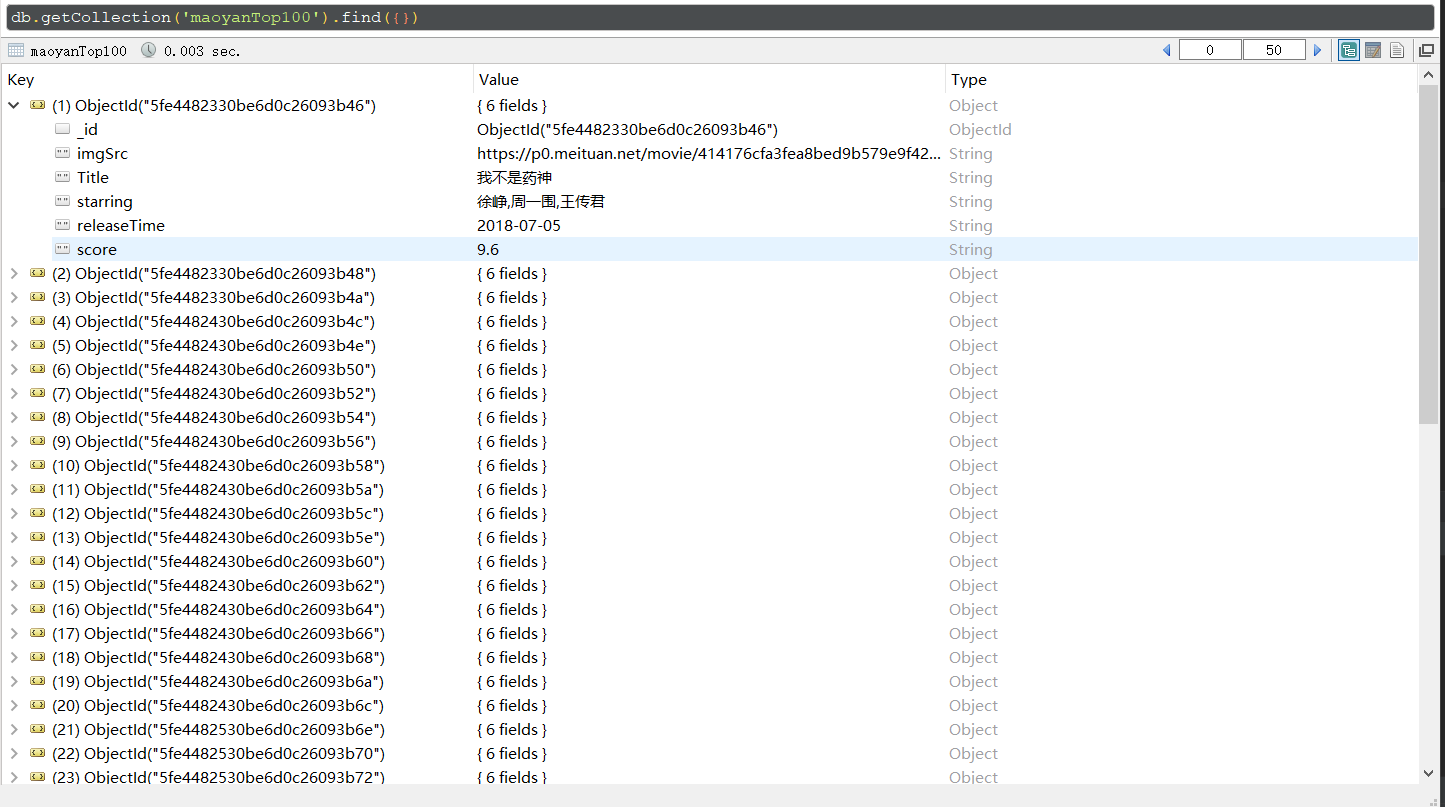
爬取后写入MongoDB
import pymongo
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/80.0.3987.163 Safari/537.36 '
}
def toMongoDB(imgSrc, Title, starring, releaseTime, score):
print(imgSrc)
print(Title)
print(starring[3:])
print(releaseTime[5:])
print(score)
myClient = pymongo.MongoClient("mongodb://localhost:27017/")
myDb = myClient["maoyan"]
myCollection = myDb["maoyanTop100"]
myDictionary = {
"imgSrc": imgSrc,
"Title": Title,
"starring": starring[3:],
"releaseTime": releaseTime[5:],
"score": score
}
result = myCollection.insert_one(myDictionary)
print(result)
pass
def mingzihaonanqi(page):
url = 'https://maoyan.com/board/4?offset=' + str(page)
res = requests.get(url, headers=headers)
# 页面session失效, 需要重新验证, 打印出来方便使用
print(res.url)
# 打印出页面的所有代码
# print(res.text)
soup = BeautifulSoup(res.text, 'html.parser')
ResultSets = soup.find_all('dd')
for resultSet in ResultSets:
tag = resultSet
soupTag = BeautifulSoup(str(tag), 'html.parser')
Title = soupTag.find('a').get('title')
imgSrc = soupTag.find('img', class_='board-img').get('data-src')
starring = soupTag.find('p', class_='star').text.strip()
releaseTime = soupTag.find('p', class_='releasetime').text.strip()
score = soupTag.find('p', class_='score').text.strip()
# 写入MongoDB
toMongoDB(imgSrc, Title, starring, releaseTime, score)
print(str(page) + "----------")
if __name__ == '__main__':
for i in range(0, 100, 10):
print(i) # 0 10 20 ````
mingzihaonanqi(i)
运行结果