如果你对这三个东西还不清楚,我相信阅读本篇博客会使你正确认识他们。
进入正题前,建议你带着这几个问题食用~
- xxx是什么?
- xxx怎么用?
- 为什么要用xxx?
存储引擎
简介 :用大白话来说,存储引擎就是表存储/组织数据的方式,每个表都可以指定存储引擎,不同的存储引擎组织数据的方式不一样。(注:存储引擎是MySQL特有的术语,其他数据库也有这东西,但不叫这名字)
A、如何使用?
就在建表的时候,往小括号后边用 “ENGINE”来指定即可

B、MySQL支持哪些存储引擎?
输入一条命令即可查看;如下图,MySQL支持这九种存储引擎,并且版本不同支持情况不同
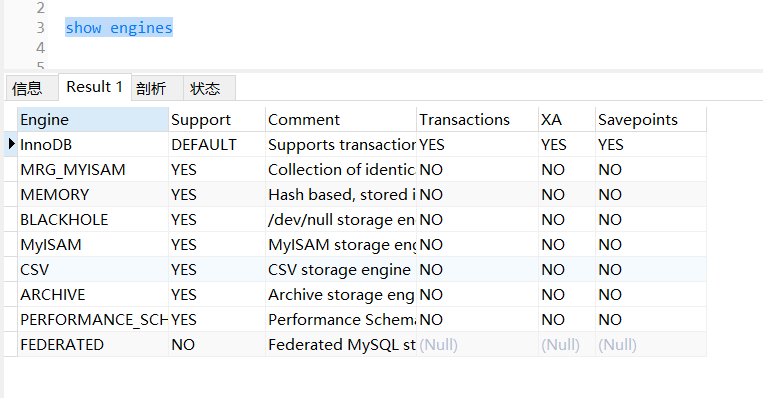
C、常用存储引擎?
作为一名java程序猿,我们了解常用的几种存储引擎即可
第一种:【MyISAM】
它是最常用的存储引擎
当某张表被它管理后,会以数据库目录的三个文件来表示那张表。即创建了一张表,就会生成三个文件(如下:)
1、格式文件(xxx.frm):存储表结构
2、数据文件(xxx.myd):存储表内容
3、索引文件(xxx.myi):存储表索引
优势:这仨兄弟可以被压缩、转换为只读,这样可以节省空间
劣势:不支持事务
第二种:【InnoDB】
它是MySQL默认的存储引擎
当某张表被它管理后,会以数据库目录中的一个(.frm)文件来表示那张表。即创建了一张表,就会生成一个文件
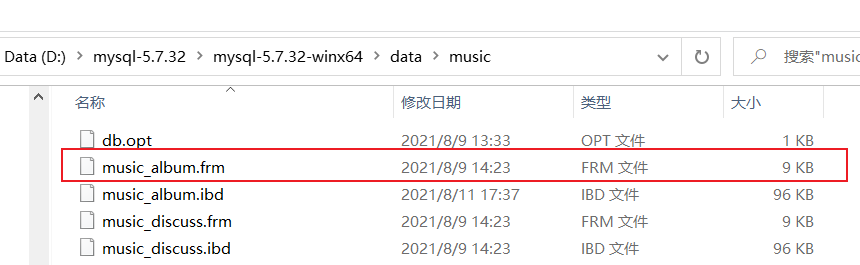
优势:支持事务、支持“数据库崩溃后自动恢复”机制、非常安全、是默认的
劣势:重量级,效率不是很高
第三种:【MEMORY】
当某张表被它管理后,会以数据库目录中的一个(.frm)文件来表示那张表。即创建了一张表,就会生成一个文件
这张表的数据和索引存储在内存中,所以其速度会非常快,
优势:查询效率高;不用和硬盘交互
劣势:不安全,数据断电即失;不支持事务
(注:内存和硬盘的区别?内存直接取,电流的速度,而硬盘是机械行为)
事务(敲黑板!!!)
简介:一个事务就是一个完整的业务逻辑,这个业务时最小的逻辑单元,不可再分,要么同时成功,要么同时失败。
只有DML语句(数据操纵语言,即【增删改】)才会有事务一说,其余语句与事务无关。
注意,问题来了!
A、为何会存在事务一说?
就是在要完成某项业务时,需要多条DML语句共同完成。假如一条就能完成,那就不需要事务了……
B、事务的本质?
本质上就是多条sql语句同时成功或同时失败
C、事务操作?
注意:MySQL默认是自动提交的,即执行一条DML语句就提交一次。但我们可是要多条执行完一起提交的,这可就得关掉自动提交了~
其实,打开事务的命令就是表示关闭自动提交事务的
开启事务(关闭自动提交):start transaction;
提交事务:commit;
回滚事务:rollback;
D、事务是咋做到同时成功/失败的?
有一个叫【事务性活动】的文件,在事务执行过程中,每条语句的操作都会记录在其中。
1、当我们提交事务时:之前所进行的DML语句产生的数据会被持久化到数据库表中,并清空文件里的内容
2、当我们回滚事务时:之前所进行的DML语句操作将会被全部撤销,并清空文件里的内容
E、事务的特性?
A:原子性。最小的工作单元,不可再分
C:一致性。同时成功或同时失败
I:隔离性。A事务和B事务之间有隔离
D:持久性。事务提交后,事务执行所产生的数据将会被持久化到数据库表中
F、隔离级别?
这个可是重中之重,面试的百年老题了。答应我,好好看,可以吗?
隔离:事务A和事务B之间有一道墙;
级别:墙的厚度,级别越高,墙越厚。
MySQL有四个隔离级别,且听我慢慢道来~
-
读未提交【read uncommitted】
最低的隔离级别,就是说 事务A在执行过程中,能够读取到事务B已执行但未提交的数据结果
存在的问题:脏读(Dirty Read),即读到了脏数据。这种隔离级别已经是理论上的了,因为大多数据库使用的都是二挡起步,没人用这种。 -
读已提交【read committed】
事务A只能读到事务B已执行并且已提交的数据,解决了脏读问题,每一次读到的都是真实的数据
存在的问题:不可重复读 -
可重复读【repeatable read】
MySQL默认的隔离级别,就是事务A开启后,并且没有提交或回滚之前,读取到的数据都是停留在刚开启事务的时候,即便事务B修改了表中的数据,事务A读到的还是事务B提交之前的数据。这就解决了不可重复读的问题,但是也迎来了新的问题:幻读
(举个例子:比如一个事务A,它从开始执行到执行结束,花了一个小时。那么在这一个小时内,无论其他事务提交了多少次,数据被修改多少次,丝毫不会影响到事务A,它操作的数据还是其他事务提交之前的。) -
序列化/串联化【serializable】
最高的隔离级别,解决了所有问题,但是效率最低。这种隔离级别表示让事务排队执行,就类似于 synchronized,每一次读取到的数据都是真实的。
(举个例子:当事务A在执行时,事务B想执行?不允许,后边排队去,等事务A执行完才到事务B执行)
G、查看当前隔离级别?
select @@tx_isolation
H、设置隔离级别?
如:将隔离级别设置为读未提交
set global translation isolation level read uncommitted;