以Wordcount为例,解释MapReduce工作原理
-
结合图解释

解释:MapReduce分为两部分,map阶段和reduce阶段。
(1)map阶段是读取文件内容,将每行解析成键(key)值(value)对。key是字节的偏移量,value值是每一行的内容,每一键值对经过自定义的map函 数,形成新的key 和value。对输出的key,value进行分区.根据业务要求,把map输出的数据分成多个区。
(2)shuffle:把map中的数据分发到reduce中去的一个过程,分组还是仍然是map的gognzuo neirong .按照key进行排序,分组.相同key的value放到一个集合中.(分组不是合并,只是把相同的key的value放到一起,并不会减少数据.分组是给了同一个map中相同key的value见面的机会.作用是为了在reduce中 进行处理.map函数仅能处理一行,两行中出现的这个单词是无法在一个map中处理的.map不能处理位于多行中的相同的单词.分组是为了两行中的相同 的key的value合并到一起.)
(3)reduce阶段将分组的key和value进行自定义的reduce函数处理,生成新的key和value。
-
结合代码解释
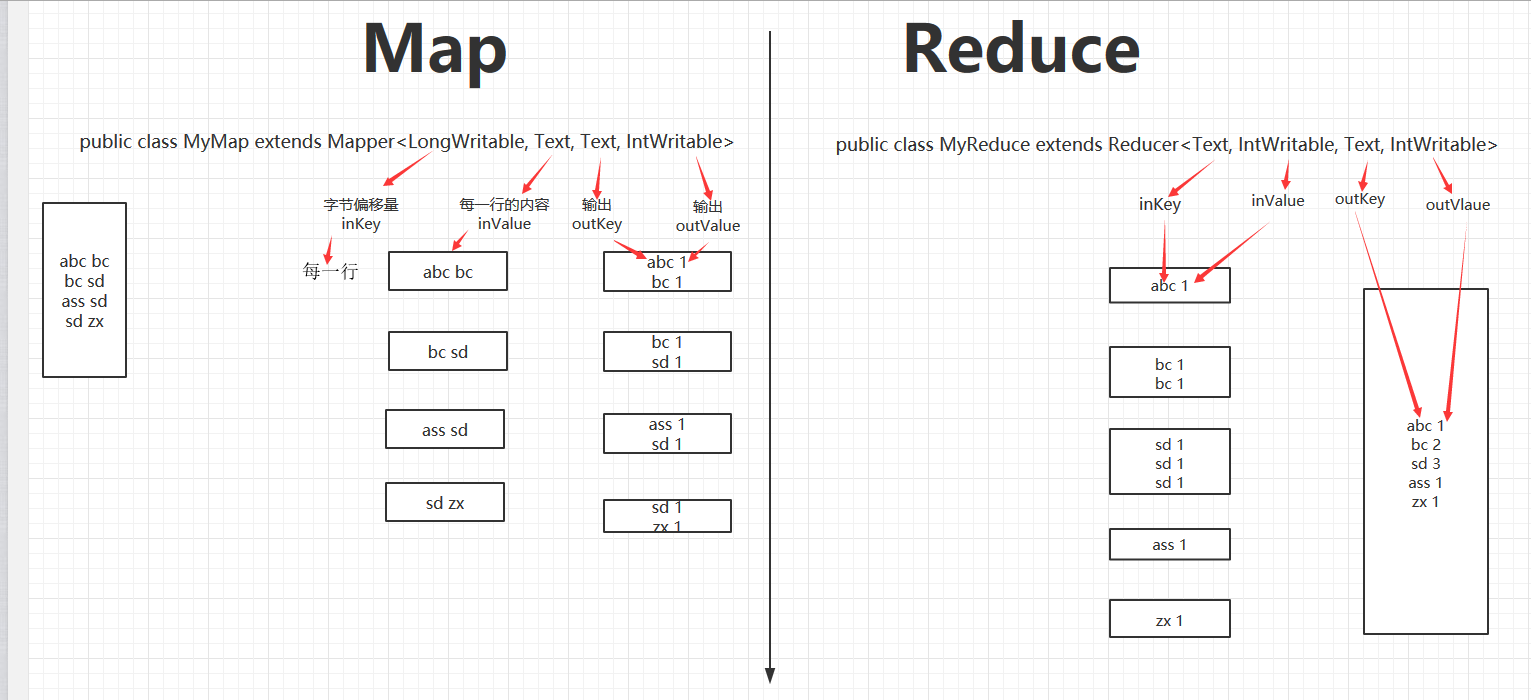
注意:自定义的map函数每次只处理一行,自定义的reduce函数每次处理一组!!!