Introduction
该模型来自于文章 A General Framework for Information Extraction using Dynamic Span Graphs , 简称 Dynamic Graph IE (DYGIE)模式, 是事件抽取中一些数据集的 SOTA.
这是一个多任务模型, 同时训练的任务是 NER(命名实体识别), RE(事件抽取), coreferences solution(实体指代消解), 基本思想是这三个任务之间的相关性可以充分使用文本的信息,
这篇文章使用的实体关系抽取的解码层的解码方式是片段分类, 后面会给出细节, 这些片段向量构成图神经网络的节点, 边是关系类型的权重或者指代消解的权重, (指代消解我并不是很熟悉, 只知道在本文的用法).
Model
Problem Definition
我们定义输入为 (S= {s_1,...,s_T}), 表示所有的 Text Span, 最长的长度为字符长度 (L), 输出根据三个任务, 分成三部分, 实体类型 (E), 同一句话中, 所有实体对 (S imes S) 之间的关系 (R), 句子之间的实体对应的 coreference links, 表示从一个句子中的实体到其对应的antecedent 之间的链接. 实际上是对于 Text span (s_i), 找到它的最优antecedent (c_i).也就是前一句中, 和它意义相同的 span.
Model Introduction
模型的基本思路是首先使用枚举所有的 text span, 然后使用图神经网络来并入(整合) 整句话的信息到这个 text span representation(vector) 中, 整合信息(或者说加入邻接节点信息), 的方式是使用临近的 relation type 和 共指的实体.
Model Architecture
模型的整体结构如下, 我们会分部分解释:
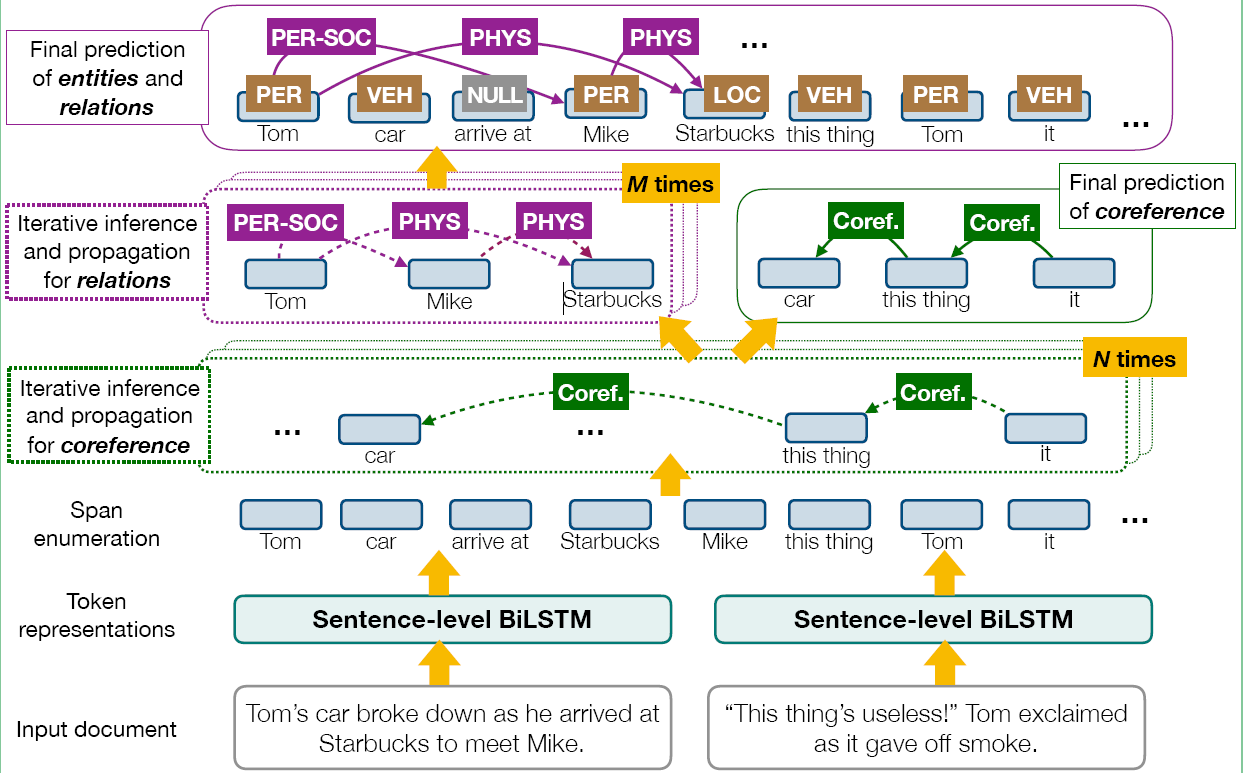
Token Representation Layer
输入是按照句子级别输入, 具体细节在代码里面, 后面会分析, 分词之后, 每个 token 的输入是由 1. 字符表示, 2. Glove 预训练模型的 embedding, 3. ELMo 的embedding, 然后将 token 的输入经过 BiLSTM, 使用输出作为每个 Token 的representation,
Span Representation Layer
对于一个 text span (s_i), 它的初始向量 (g_i^0) 也由三部分组合(concatenated)而成,
- text span 的左侧和右侧的 token representation,
- 一个基于 Attention 的"head word"
- 还有一个embedded 后的span 的长度特征, 也就是长度特征的编码
Coreference Propagation Layer
这一层是共指传播层, 在上图中就是 text span 枚举后面的那一层, 我们可以看到输入是 span 的初始向量, (g_i^0), 每次迭代的过程中, 输入是 span 的representation (g_i^t) 我们首先为每个 span (s_i) 计算更新矩阵 (u_C^t) , 然后使用这个更新矩阵更新当前状态, 得到下一个状态 (g_i^{t+1}), 重复 (N) 次得到, (g_i^N), 这个向量就包含了 span (s_i) 的共指的span 的信息.
Relation Propagation Layer
我们将Coreference Propagation Layer 的输出, (g_i^N), 作为这一层的输入, 同样, 我们首先计算span 的更新矩阵 (u_R^t), 然后计算 (g_i^{t+1}), 重复迭代 (M) 次, 那么输出 (g_i^{N+M}) 就包含 relation 的信息.
Final Prediction Layer
这一层是三个任务的预测:
- 使用relation Layer 的输出 (g_i^{M+N}) ,使用 (FFNN), 进行分类, 计算类别的 (P_E(i)).
- 对于每个 spans pair, (<s_i, s_j>) 使用对应的 (g_i^{M+N}) 和 (g_j^{M+N}) 的 concatenation, 经过 (FFNN), 计算关系类别
- 对于每个 span pairs,
Dynamic Graph Construction and Span Refinement
动态图中的节点是span (S_i) 的第 (t) 轮迭代的 representation (g_i^t), 图中的边是共指或者关系的权重, 动态图更新与构建的过程就是要更新span 的 representation 与边的 representation.
Coreference Propagation
首先定义一组 spans 表示可能是共指的 spans, 用 (B_C) 表示这个集合, 用 (K) 表示对于一个 span 的antecedents的最大数量, 在集合 (B_C) 中, (P_C^t) 就表示集合中 spans 之间的coreference confidence scores, 它的大小是 (b_c imes K), (b_c) 表示集合(B_C)中 spans 的个数. 对于 (B_C) 中的一个 span (s_i), 假设其 antecedent 是 (s_j), 那么动态图中的边用 (P_C^t(i,j)) 来表示, 它的计算方式是:
首先计算 (V_C^t(i,j) = FFNN([g_i^t,g_j^t,g_i^t odot g_j^t])) 得到的 (V_C^t(i,j)) 是一个标量, 然后对于 (B_C) 中的所有 (j), 计算:
我们可以看出, 动态图中的边表示的就是 spans 之间的coreference confidence scores, 我们根据这个边,来计算spans representation 的更新矩阵:
然后使用更新矩阵更新 (g_i^t) , 更新的方式后面会讲, 有点类似与 LSTM 的门方式.
Relation Propagation
从图的结构中, 我们知道, 关系图是在共指图的后面, 但是实际上, 更新的方式是类似的, 首先定义集合 (B_R) 表示可能有关系的 (b_r) 个spans, 不同于共指, 关系抽取, 两个 spans 之间可能有多种关系, 而共指中只有一种关系. 假设关系的类别为 (L_R), 那么关系图的边表示 (V_R^t), 它的维度是 (mathbb{R}^{b_R imes b_R imes L_R}) , 这是因为需要表示 (L_R) 种关系, 其中一条边计算方式是:
(V_R^t(i,j)) 的维度是 (L_R), 那么在关系图中更新span representation 的矩阵 (u_R^t(i) in mathbb{R}^d) 计算公式如下:
其中 (f) 可以使用 ReLU函数进行分类, (A_R in mathbb{R}^{L_R imes d}) 是一个参数矩阵.
Updating Span Representations with Gating
之前我们讲到的迭代, 感觉有点类似与 LSTM 的方式, 本质上只有一个模块, 然后上层的输出作为下层的输入, 不断迭代, 这里每次迭代更新 (g_i^t) 的方式有点类似, 使用门的方式, 更新的过程可以表示为:
其中 (f_x^t(i) in mathbb{R}^d) , (x) 表示共指阶段图与关系抽取图可以使用不同的参数, (W_x^f in mathbb{R}^{d imes 2d}) 是训练的参数. (g) 是 sigmoid 函数, 上述表示一次迭代过程中更新的方式.
整个过程就是图神经网络的部分, 共指关系图 和关系抽取图 部分, spans representation的更新方式, 也就是图神经网络的输出部分, 但是我们可以看到, 实际上这个图神经网络并不是十分复杂的图神经网络,
Training
训练过程中, 我们需要最大化极大似然估计, 由于三个都是分类问题, 本质上是最小化交叉熵损失函数,
其中(R^*, E^*, C^*) 是我们的预测值, (D) 是输入的documents, (lambda_E, lambda_R, lambda_C) 是损失函数三个任务部分的超参数.
关于代码部分, 目前不打算继续分析后面的实验以及代码细节, 因为新的文章已经出来了, 谷歌就像挤牙膏, 把这个模型用于事件抽取, 也是 SOTA, 因为我主要是做事件抽取的, 所以会好好分析下一篇文章以及它的代码实现.