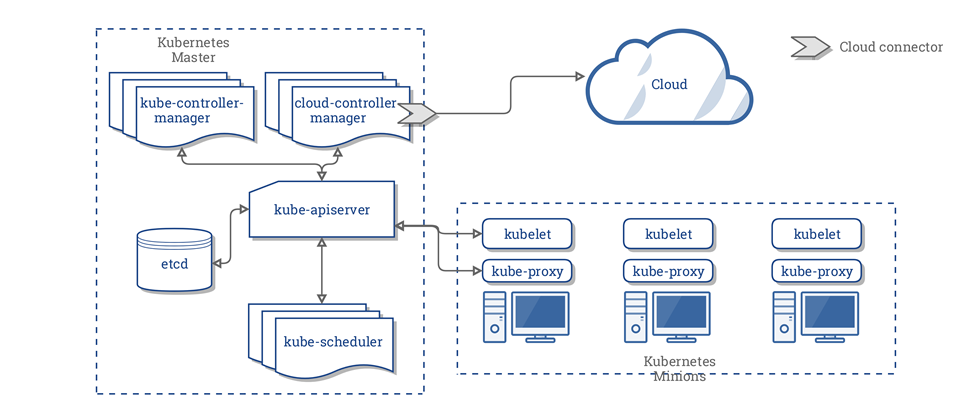
前言:
大部分情况下,kubernetes中的Pod只是容器的载体,通过Deployment、DaemonSet、RC、Job、Cronjob等对象来完成一组Pod的调度与自动控制功能。
Pod调度是由Scheduler组件完成的,可见图中位置。

Scheduler工作原理
pod创建流程及Scheduler调度步骤:
- 节点预选(Predicate):排除完全不满足条件的节点,如内存大小,端口等条件不满足。基于一系列的预选规则对每个节点进行检查,将那些不符合条件的节点过滤,从而完成节点的预选。
- 节点优先级排序(Priority):根据优先级选出最佳节点,对预选出的节点进行优先级排序,以便选出最合适运行Pod对象的节点。
- 节点择优(Select):根据优先级选定节点,从优先级排序结果中挑选出优先级最高的节点运行Pod,当这类节点多于1个时,则进行随机选择。

1.首先用户通过 Kubernetes 客户端 Kubectl 提交创建 Pod 的 Yaml 的文件,向Kubernetes 系统发起资源请求,该资源请求被提交到
Kubernetes 系统中,用户通过命令行工具 Kubectl 向 Kubernetes 集群即 APIServer 用 的方式发送“POST”请求,即创建 Pod 的请求。
2.APIServer 接收到请求后把创建 Pod 的信息存储到 Etcd 中,从集群运行那一刻起,资源调度系统 Scheduler 就会定时去监控 APIServer
3.通过 APIServer 得到创建 Pod 的信息,Scheduler 采用 watch 机制,一旦 Etcd 存储 Pod 信息成功便会立即通知APIServer,
4.APIServer会立即把Pod创建的消息通知Scheduler,Scheduler发现 Pod 的属性中 Dest Node 为空时(Dest Node=””)便会立即触发调度流程进行调度。
5.而这一个创建Pod对象,在调度的过程当中有3个阶段:节点预选、节点优选、节点选定,从而筛选出最佳的节点
官网解析:https://kubernetes.io/docs/concepts/scheduling-eviction/kube-scheduler/
kube-scheduler 给一个 pod 做调度选择包含两个步骤: 1.过滤(节点预选),2.打分(节点优选,节点选定)
调度场景详解
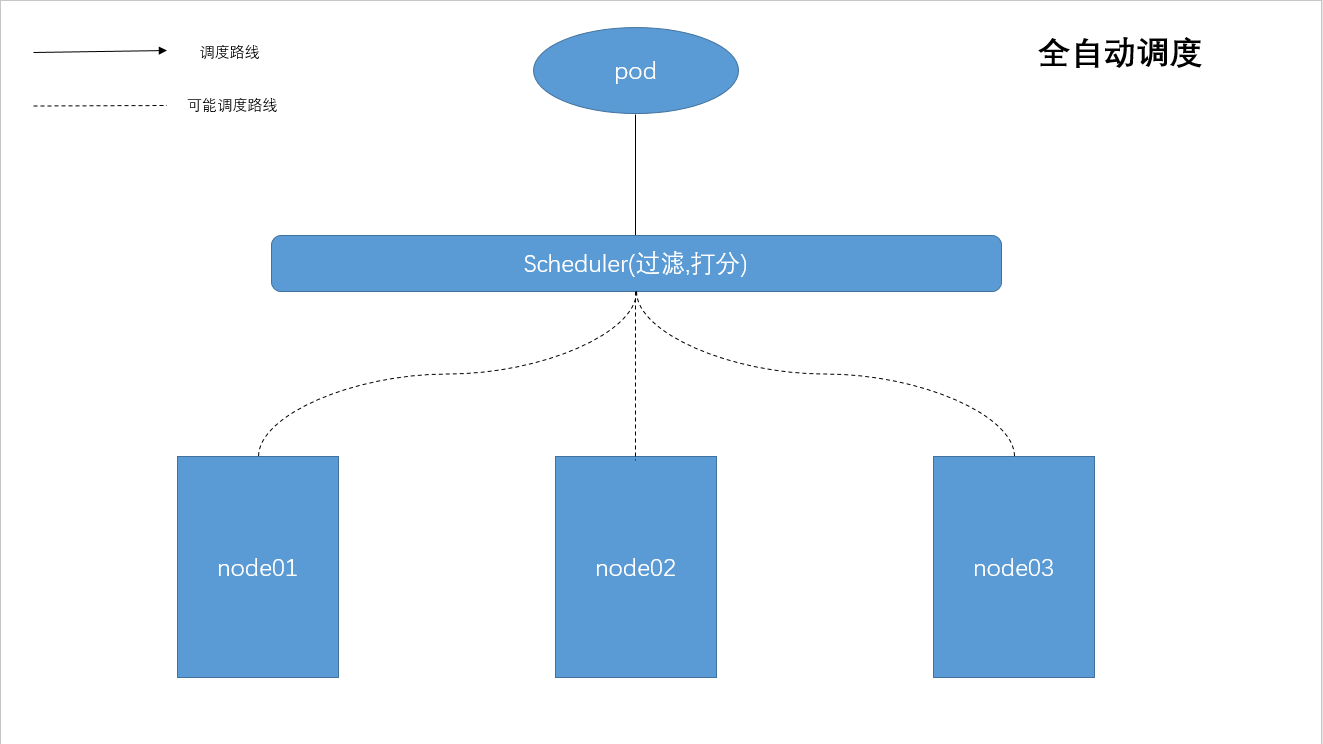
场景一:Deployment/RC:全自动调度
Deployment/RC主要是自动部署应用的多个副本,并持续监控,以维持副本的数量。默认是使用系统Master的Scheduler经过一系列算法计算来调度,用户无法干预调度过程与结果。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
spec:
replicas: 1
template:
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
restartPolicy: Always
selector:
matchLabels:
app: nginx
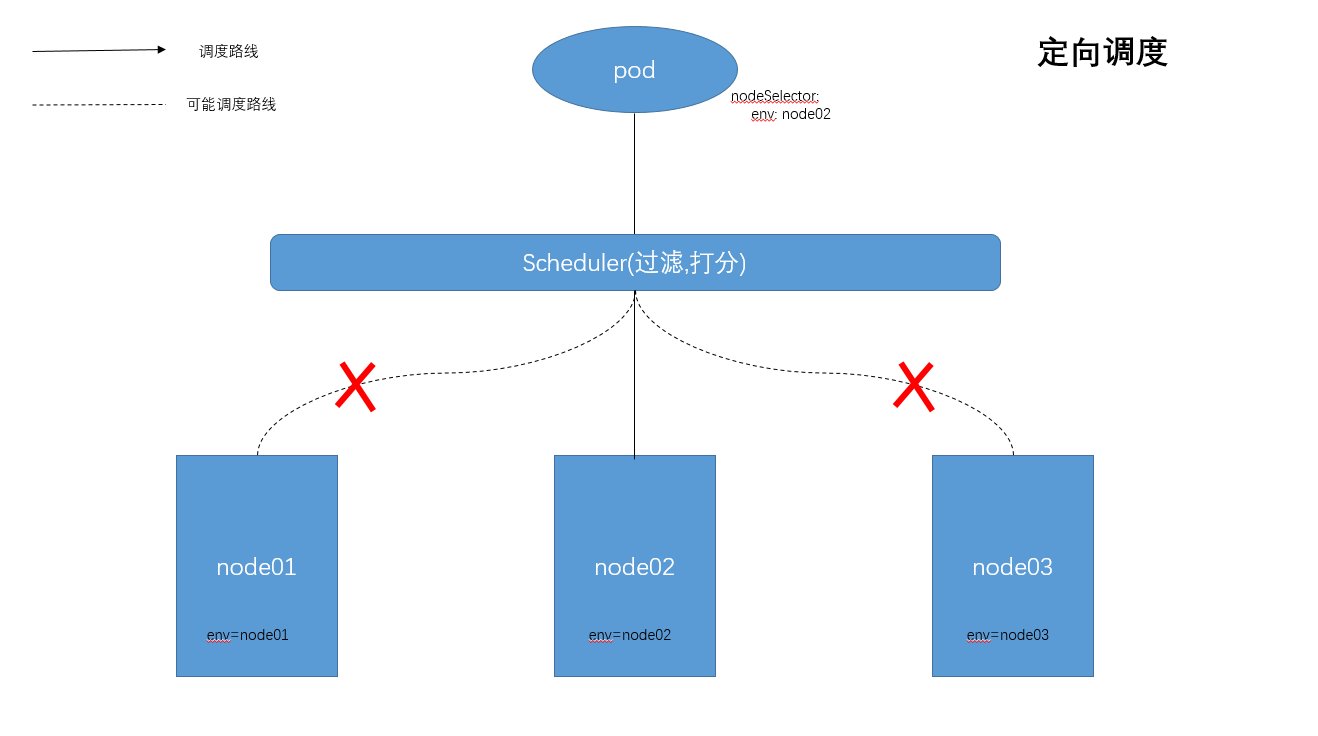
场景二:NodeSelector:定向调度
通过Node的标签和Pod的nodeSelector属性相匹配,可以达到将pod调度到指定的一些Node上。
#oc label nodes <node-name> env=dev
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
spec:
replicas: 1
template:
metadata:
name: nginx
labels:
app: nginx
spec:
nodeSelector:
env: 'node02'
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
restartPolicy: Always
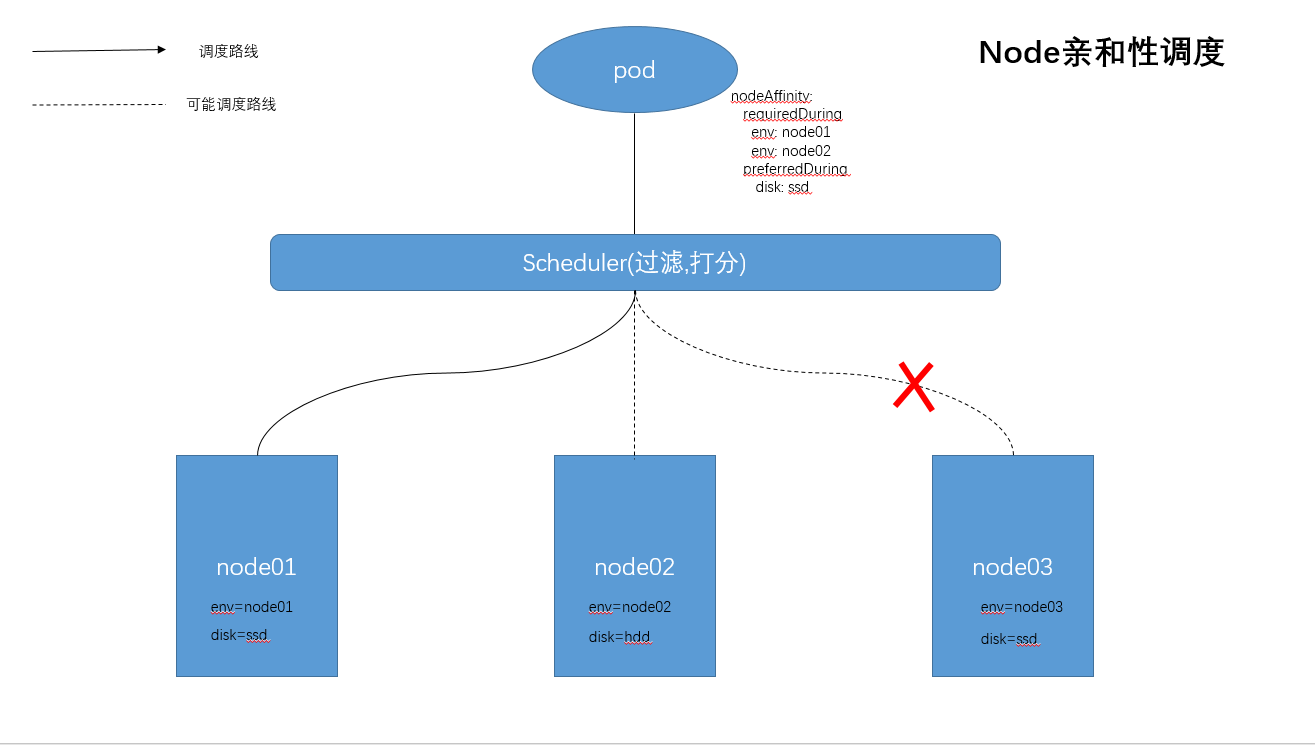
场景三:Node亲和性调度
目前有两种亲和性表达,NodeAffinity语法支持的操作符包括In/NotIn/Exists/DoesNotExist/Gt/Lt
In:label 的值在某个列表中
NotIn:label 的值不在某个列表中
Exists:某个 label 存在
DoesNotExist: 某个 label 不存在
Gt:label 的值大于某个值(字符串比较)
Lt:label 的值小于某个值(字符串比较
(1) RequiredDuringSchedulingIgnoreDuringExecution
必须满足指定的规则才可以调度Pod到Node上(与nodeSelector类似),为硬限制
(2)PreferredDuringSchedulingIgnoreDuringExecution
强调优先满足指定规则,调度器优先选择合适的Node,但不强求,为软限制。多个优先级规则还可以设置权重值,以定义执行的先后顺序
注意事项
- 同时定义了nodeSelector与nodeAffinity,那必须两个条件都满足,Pod才被调度到指定的Node上。
- nodeAffinity指定了多个nodeSelectorTerms规格时(如:require或preferred),那么只需要满足其中一个就能够匹配成功就可以完成调度。
- nodeSelectorTerms中有多个matchExpressions,则一个节点必须满足所有matchExpressions才能运行Pod。
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
restartPolicy: Always
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: env
operator: In
values:
- node02
- node01
preferredDuringSchedulingIgnoredDuringExecution:
- preference:
weight: 1
matchExpressions:
- key: disk
operator: In
values:
- ssd
这条规则表示,pod可以被调度到key为“env”,值为“node01”或“node02”的节点。另外,在满足该条件的节点中,优先使用具有“disk”标签,且值为“ssd”的节点。
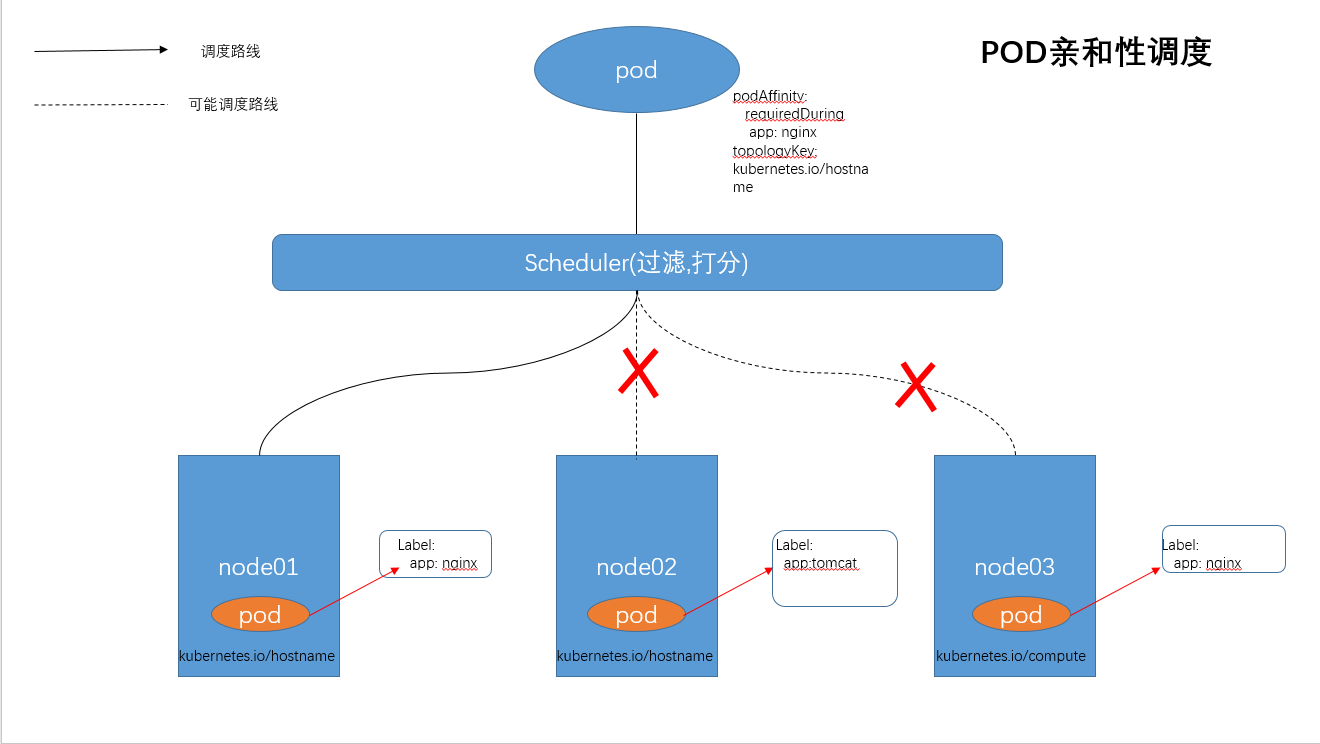
场景四:POD亲和性调度
POD亲和性表示POD部署到满足某些label的pod所在的NODE上.
(1)matchExpressions 表示符合label条件的pod,根据节点上正在运行的其它Pod的标签来进行限制。
(2)topologyKey 表示作用域key,这里使用 kubernetes.io/hostname表示所有的节点,因为所有的节点默认都会打上这个标签。
注意:PodAffinity规则设置注意事项
- RequiredDuringSchedulingIgnoreDuringExecution 必须满足指定的规则才可以调度Pod到Node上(与nodeSelector类似),为硬限制
- PreferredDuringSchedulingIgnoreDuringExecution强调优先满足指定规则,调度器优先选择合适的Node,但不强求,为软限制。多个优先级规则还可以设置权重值,以定义执行的先后顺序
- 除了设置Label Selector和topologyKey,还可以指定namespaces列表来进行限制,namespaces定义与Label Selector和topologyKey同级。默认namespaces设置表示为Pod所在的namespaces,如果namespaces设置为“”则表示所有的namespaces。
*在所有关联requiredDuringSchedulingIgnoredDuringExecution的matchExpressions全部满足后,才将Pod调度到指定的Node上。
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: affinity
labels:
app: affinity
spec:
replicas: 3
revisionHistoryLimit: 15
template:
metadata:
labels:
app: affinity
role: test
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
name: nginxweb
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution: # 硬策略
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: kubernetes.io/hostname
这条规则表示,pod需要被调度到某个NODE节点上,该节点属于kubernetes.io/hostname 这个域,并且上面运行了这样的 pod:这个pod 有一个app=nginx的 label。
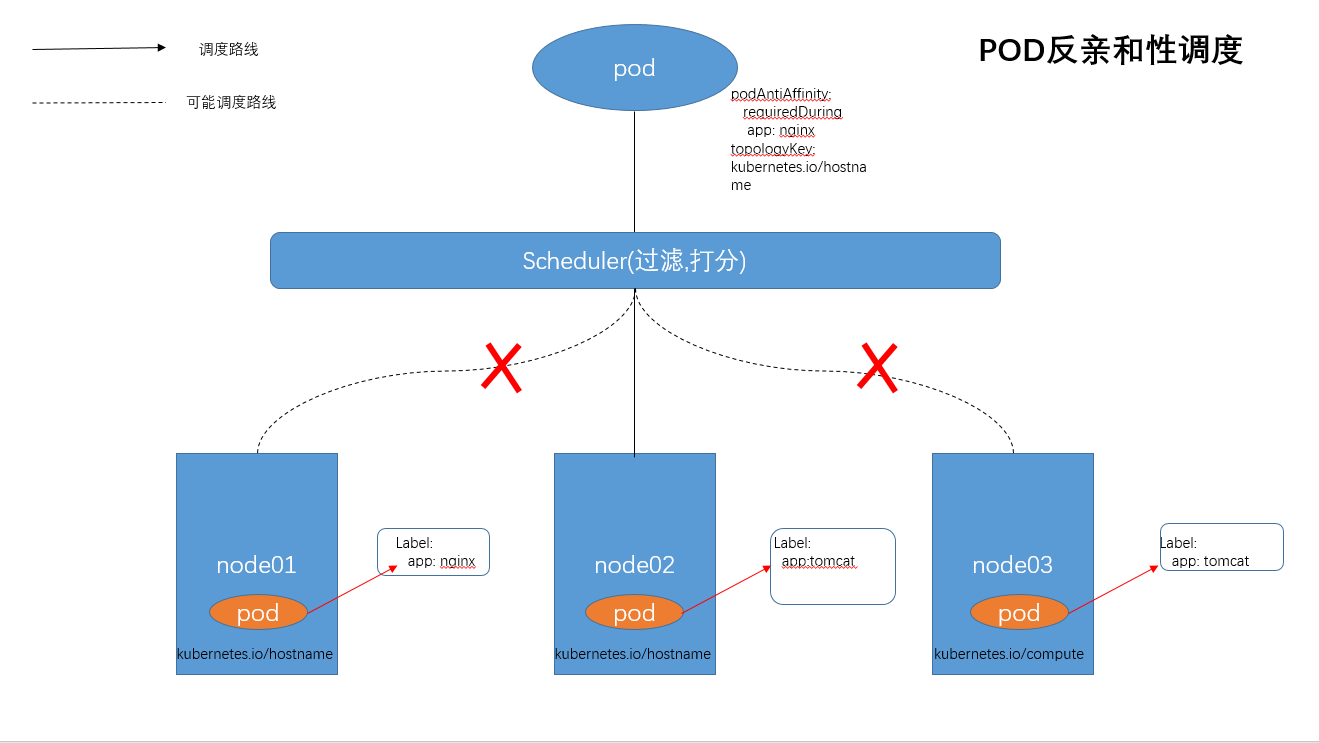
场景五:POD反亲和性调度
POD反亲和性表示POD不能部署到满足某些label的pod所在的NODE上.
(1)matchExpressions 表示符合label条件的pod,根据节点上正在运行的其它Pod的标签来进行限制。
(2)topologyKey 表示作用域key,这里使用 kubernetes.io/hostname表示所有的节点,因为所有的节点默认都会打上这个标签。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
selector:
matchLabels:
app: nginx
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: "kubernetes.io/hostname"
containers:
- name: nginx-server
image: nginx:latest
这条规则表示,pod不能被调度到某个NODE节点上,该节点属于kubernetes.io/hostname 这个域,并且上面运行了这样的 pod:这个pod 有一个app=nginx的 label。
场景六: Taints与Tolerations(污点与容忍)
Taints与前面的Affinity相反,它让Node拒绝Pod的运行。为node添加一个Taint,效果是NoSchedule(除了NoSchedule还可以取值PreferNoSchedule/NoExecute)。意味着除非Pod明确声明可以容忍这个Taint,否则不会被调度到该Node上。使用PodToleratesNodeTaints预选策略和TaintTolerationPriority优选函数完成该机制
定义污点和容忍度: 污点定义于nodes.spec.taints容忍度定义于pods.spec.tolerations 语法: key=value:effect
管理节点的污点: 同一个键值数据,effect不同,也属于不同的污点
effect定义排斥等级:
NoSchedule:不能容忍,但仅影响调度过程,已调度上去的pod不受影响,仅对新增加的pod生效。
PreferNoSchedule:柔性约束,节点现存Pod不受影响,如果实在是没有符合的节点,也可以调度上来
NoExecute:不能容忍,当污点变动时,Pod对象会被驱逐,如果Pod无法容忍NoExecute的Taint,则上面已经运行的Pod会被驱逐。
在Pod上定义容忍度时:
等值判断 容忍度与污点在key、value、effect三者完全匹配
存在性判断 key、effect完全匹配,value使用空值
一个节点可配置多个污点,一个Pod也可有多个容忍度
给节点添加污点:
#oc taint nodes <node-name> key1=value1:NoSchedule
#oc taint nodes <node-name> key1=value1:NoExecute
#oc taint nodes <node-name> key2=value2:NoSchedule
删除节点污点:
kubectl taint node <node-name> <key>[:<effect>]-
kubectl patch nodes <node-name> -p '{"spec":{"taints":[]}}'
kubectl taint node kube-node1 node-type=production:NoSchedule
kubectl get nodes kube-node1 -o go-template={{.spec.taints}}
删除key为env,effect为NoSchedule的污点:
kubectl taint node kube-node1 env:NoSchedule-
删除key为env的所有污点:
kubectl taint node kube-node1 env-
删除所有污点:
kubectl patch nodes kube-node1 -p '{"spec":{"taints":[]}}'
给Pod对象容忍度
spec.tolerations字段添加
tolerationSeconds用于定义延迟驱逐Pod的时长
等值判断:
tolerations:
- key: "key1"
operator: "Equal" #判断条件为Equal
value: "value1"
effect: "NoExecute"
tolerationSeconds: 3600
存在性判断:
tolerations:
- key: "key1"
operator: "Exists" #存在性判断,只要污点键存在,就可以匹配
effect: "NoExecute"
tolerationSeconds: 3600
问题节点标识:
自动为节点添加污点信息,使用NoExecute效用标识,会驱逐现有Pod,K8s核心组件通常都容忍此类污点:
node.kubernetes.io/not-ready 节点进入NotReady状态时自动添加
node.alpha.kubernetes.io/unreachable 节点进入NotReachable状态时自动添加
node.kubernetes.io/out-of-disk 节点进入OutOfDisk状态时自动添加
node.kubernetes.io/memory-pressure 节点内存资源面临压力
node.kubernetes.io/disk-pressure 节点磁盘面临压力
node.kubernetes.io/network-unavailable 节点网络不可用
node.cloudprovider.kubernetes.io/uninitialized kubelet由外部云环境程序启动时,自动添加,待到去控制器初始化此节点时再将其删除
实例:
#oc taint nodes node01 key1=value1:NoSchedule
#oc taint nodes node02 key1=value1:NoExecute
#oc taint nodes node03 key2=value2:NoSchedule
apiVersion: v1
kind: Deployment
metadata:
name: myapp-deploy
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: myapp
release: canary
template:
metadata:
labels:
app: myapp
release: canary
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
ports:
- name: http
containerPort: 80
tolerations:
- key: "env"
operator: "Equal"
value: "node02":
effect: "NoExecute"
tolerationSeconds: 3600
这条规则表示,该pod容忍env=node02 且 effect 为 NoExecute的节点。可以进行调度

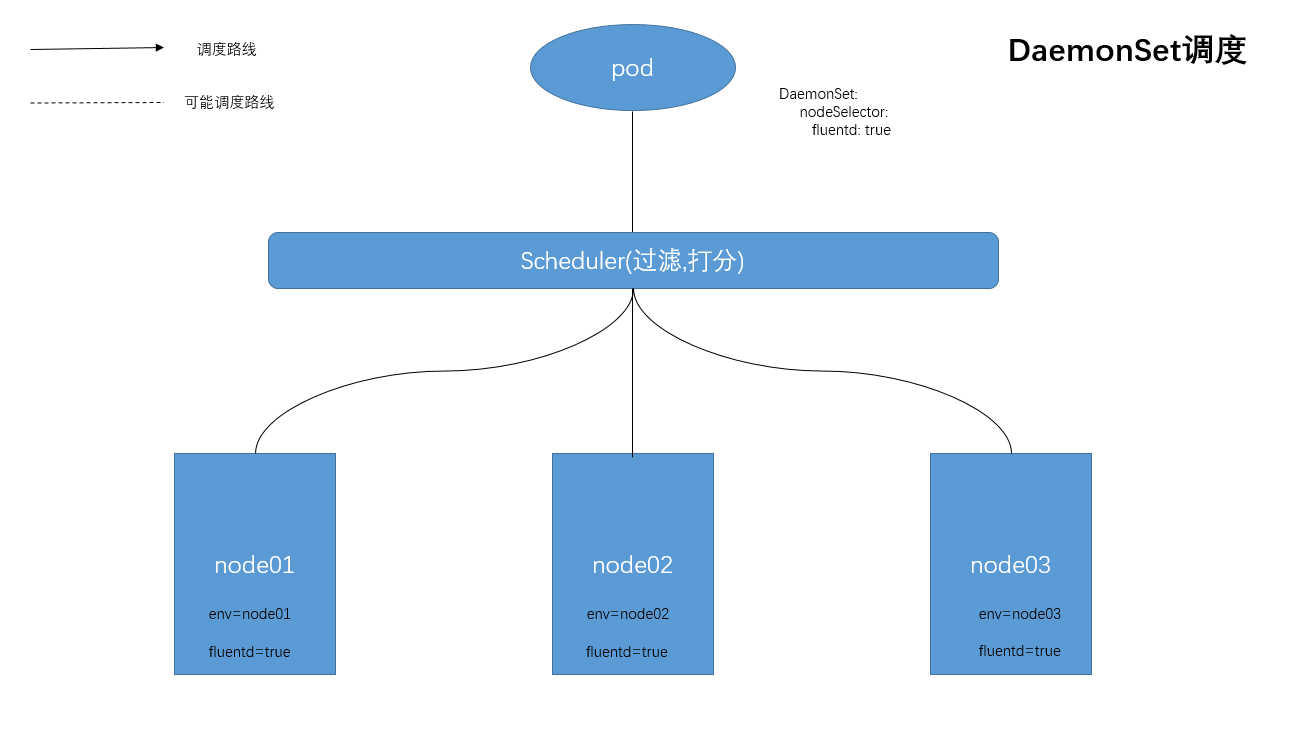
场景七:DaemonSet调度:在每个Node上调度一个Pod
管理集群中每个Node上仅运行一份Pod的副本实例。
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
labels:
component: fluentd
name: logging-fluentd
namespace: logging
spec:
selector:
matchLabels:
component: fluentd
template:
metadata:
labels:
component: fluentd
name: fluentd-elasticsearch
spec:
containers:
image: docker.io/openshift/origin-logging-fluentd:latest
imagePullPolicy: IfNotPresent
name: fluentd-elasticsearch
nodeSelector:
fluentd: true
这条规则表示,pod会在每一个符合调度的node 节点上启动一个实例。该节点必须存在fluentd=true 的标签。
结尾:
本文内容到此就结束了,优良的调度是分布式系统的核心。Scheduler调度器做为Kubernetes三大核心组件之一, 承载着整个集群资源的调度功能,其根据特定调度算法和策略,将Pod调度到最优工作节点上,从而更合理与充分的利用集群计算资源,使资源更好的服务于业务服务的需求。