1、集合
在Java中,如果一个Java对象可以在内部持有若干其他 Java 对象,并对外提供访问接口,我们把这种Java对象称为集合。很显然,Java 的数组可以看作是一种集合。
在Java中数组有如下限制:
- 数组初始化后大小不可变;
- 数组只能按索引顺序存取。
因此,我们需要各种不同类型的集合类来处理不同的数据,例如:
- 可变大小的顺序链表;
- 保证无重复元素的集合.....
最常用的集合有:ArrayList,HashSet,HashMap,Array(数组)。
Java标准库自带的java.util包提供了集合类:Collection ,它是除 Map 外所有其他集合类的根接口。Java的java.util包主要提供了以下三种类型的集合:
List:一种有序列表的集合,例如,按索引排列的Student的List;Set:一种保证没有重复元素的集合,例如,所有无重复名称的Student的Set;Map:一种通过键值(key-value)查找的映射表集合,例如,根据Student的name查找对应Student的Map。
1.1、集合的特点
java 中的集合可以存放不同类型、不限数量的数据类型(可以通过泛型来限制只可以存入某种类型的数据)。Java 中的集合只能存放对象,比如你把一个 int 类型的数据 1 放入集合,其实它是自动转换成 Integer 类后放入的。
Java集合的其他特点:
- 实现了接口和实现类相分离,例如,有序表的接口是
List,具体的实现类有ArrayList,LinkedList等, - 支持泛型,我们可以限制在一个集合中只能放入同一种数据类型的元素,例如:List<String> list = new ArrayList<>(); // 只能放入String类型
- Java访问集合总是通过统一的方式——迭代器(Iterator)来实现,通过迭代器访问无需知道集合内部的元素的存储方式
2、List 集合(有序可重复,可变长度数组)
List 集合是一种有序列表,它的行为和数组几乎完全相同:List 内部按照放入元素的先后顺序存放,每个元素都可以通过索引确定自己的位置,List的索引和数组一样,从0开始。List 集合的大小是可变的。
List 代表一个元素有序且可重复的集合,集合中的每个元素都有其对应的顺序索引。
List 允许使用重复元素,可以通过索引来访问指定位置的集合元素。List 默认按元素的添加顺序设置元素的索引
2.1、ArrayList 有序列表
在实际应用中,需要增删元素的有序列表,我们使用最多的是ArrayList。实际上,ArrayList在内部是使用数组来存储所有元素的。
2.2、LinkedList 有序列表
ArrayList 通过数组的方式实现了 List 接口,LinkedList通过“链表”的方式实现了List接口,在LinkedList中,它的内部每个元素都指向下一个元素:

2.3、ArryList 和 LinkedList 的对比
ArrayList 集合的底层数据结构是数组,它查询快,增删慢!线程不安全,但是效率高!
LinkedList 集合的底层数据结构是链表,它查询慢,但是增删快!线程不安全,但是效率高!

在各种Lists中,最好的做法是以 ArrayList 作为缺省选择。当插入、删除频繁时,可以使用 LinkedList()
2.4、List 集合的几个主要接口方法
List<E>接口的几个主要的接口方法:
- 在末尾添加一个元素:
void add(E e) - 在指定索引添加一个元素:
void add(int index, E e) - 删除指定索引的元素:
int remove(int index) - 删除某个元素:
int remove(Object e) - 获取指定索引的元素:
E get(int index) - 获取链表大小(包含元素的个数):
int size() - 获取元素第一次出现的位置:int indexOf(E e)
- 修改指定位置的元素:E set(int index, E e )
示例:
List<String> list = new ArrayList<>(); list.add("apple"); list.add("null"); // 允许添加 null list.add("apple"); // 允许重复添加元素 System.out.println(list.size()); //size: 3 String str = list.get(0); // "apple"
创建 List:
除了使用ArrayList和LinkedList,我们还可以通过List接口提供的of()方法,根据给定元素快速创建List:
List<Integer> list = List.of(1, 2, 5);
但是List.of()方法不接受null值,如果传入null,会抛出NullPointerException异常。
2.5、遍历 List 集合
2.5.1、for 循环遍历(不推荐使用)
和数组类型一样,我们要遍历一个List,完全可以用for循环根据索引配合get(int)方法遍历:
List<String> list = List.of("apple", "pear", "banana");
for (int i=0; i<list.size(); i++) {
String s = list.get(i);
System.out.println(s);
}
但这种方式并不推荐,一是代码复杂,二是因为get(int)方法只有ArrayList的实现是高效的,换成LinkedList后,索引越大,访问速度越慢。
2.5.2、迭代器 Iterator 遍历(推荐使用)
for 循环使用迭代器
我们应该始终坚持使用迭代器本身也是一个对象,但它是由Iterator来访问List,IteratorList的实例调用iterator()方法的时候创建的。Iterator对象知道如何遍历一个List,并且不同的List类型,返回的Iterator对象实现也是不同的,但总是具有最高的访问效率。
List<String> list = List.of("apple", "pear", "banana");
for (Iterator<String> it = list.iterator(); it.hasNext(); ) {
String s = it.next();
System.out.println(s);
}
for each 循环使用迭代器
通过Iterator遍历List永远是最高效的方式。由于Iterator遍历非常常用,为了简洁代码,在 Java 中也支持通过 for each 循环来使用Iterator遍历
public class Main { public static void main(String[] args) { List<String> list = List.of("apple", "pear", "banana"); for (String s : list) { System.out.println(s); } } }
实际上,只要实现了Iterable接口的集合类都可以直接用for each循环来遍历,Java编译器本身并不知道如何遍历集合对象,但它会自动把for each循环变成Iterator的调用,原因就在于Iterable接口定义了一个Iterator<E> iterator()方法,强迫集合类必须返回一个Iterator实例。
2.6、编写equals()方法以满足contains()和indexOf()方法的使用
要正确使用List的contains()、indexOf()方法,放入的实例必须正确覆写equals()方法。
List提供了boolean contains(Object o)方法来判断List是否包含某个指定元素。此外,int indexOf(Object o)方法可以返回某个元素的索引,如果元素不存在,就返回-1。
List<String> list = List.of("A", "B", "C");
System.out.println(list.contains("C")); // true
System.out.println(list.contains("X")); // false
System.out.println(list.indexOf("C")); // 2
System.out.println(list.indexOf("X")); // -1
List内部并不是通过==判断两个元素是否相等,而是使用equals()方法判断两个元素是否相等。因此,要正确使用List的contains()、indexOf()这些方法,放入的实例必须正确覆写equals()方法,否则,放进去的实例,查找不到。我们之所以能正常放入String、Integer这些对象,是因为Java标准库定义的这些类已经正确实现了equals()方法。
代码示例:
//下面的list集合中虽然放入了new Person("Bob"),但是用另一个new Person("Bob")查询不到,原因就是Person类没有覆写equals()方法。 public class Main { public static void main(String[] args) { List<Person> list = List.of( new Person("Bob") ); System.out.println(list.contains(new Person("Bob"))); // false } } class Person { String name; public Person(String name) { this.name = name; } }
2.6.1、如何覆写equals方法
equals()方法的正确编写方法:
- 先确定实例“相等”的逻辑,即哪些字段相等,就认为实例相等
- 用
instanceof判断传入的待比较的Object是不是当前类型,如果是,继续比较,否则,返回false; - 对引用类型用
Objects.equals()比较,对基本类型直接用==比较。使用Objects.equals()比较两个引用类型是否相等可以省去判断null的麻烦。两个引用类型都是null时它们也是相等的。
首先,我们要定义“相等”的逻辑含义。比如对于Person类,如果name相等,并且age相等,我们就认为两个Person实例相等。
public boolean equals(Object o) { if (o instanceof Person) { Person p = (Person) o; return Objects.equals(this.name, p.name) && this.age == p.age; } return false; }
如果不调用List的contains()、indexOf()这些方法,那么放入的元素就不需要实现equals()方法
3、Map 集合(key--value,类似于对象)
Map 集合是一种通过键值(key-value)查找的映射表集合,map 集合的作用就是能高效地通过 key 来查找对应的 value 值,提高查找效率。
Map 中不允许存在重复的 key,如果放入相同的key,只会把原有的 key-value 对应的 value 给替换掉。
和 List 类似,Map 也是一个接口,最常用的实现类是 HashMap。
3.1、关于Map集合的方法
put(k, v) 和 get(k) 方法存取元素
通过 put(key, value) 方法来放入值,如果 key 已经存在,该方法返回已经存在的 key 对应的 value 值,并且后放入的 value 将会替代掉旧的 value。如果 key 不存在,该方法返回 null。
通过 get(key) 方法来取值,如果 key 在 map 集合中不存在,将返回 null 。
public class Main { public static void main(String[] args) { Student s = new Student("Xiao Ming", 99); Map<String, Student> map = new HashMap<>(); map.put("Xiao Ming", s); // 插入值,将"Xiao Ming"和Student实例映射并关联 Student target = map.get("Xiao Ming"); // 取值,通过key查找并返回映射的Student实例 System.out.println(target == s); // true,同一个实例 Student another = map.get("Bob"); // 未找到返回 null } } class Student { public String name; public int score; public Student(String name, int score) { this.name = name; this.score = score; } }
Map 集合可以重复放入key-value,但是一个key只能关联一个value,后面放入的value会替代掉前面的value。如果放入的key已经存在,put()方法会返回被删除的旧的value,否则,返回null。
在一个Map中,虽然key不能重复,但value是可以重复的
查询key是否存在(containsKey(k)):如果只是想查询某个key是否存在,可以调用boolean containsKey(K key)方法。
查询value是否存在(containsValue(v))
根据key值移除元素(mapObj.remove(k))
3.2、遍历 Map
Map和List不同,Map存储的是key-value的映射关系,并且,它不保证顺序。在遍历的时候,遍历的顺序既不一定是put()时放入的key的顺序,也不一定是key的排序顺序。遍历的时候,每个key会保证被遍历一次且仅遍历一次,但顺序完全没有保证,甚至对于不同的JDK版本,相同的代码遍历的输出顺序都是不同的!
HashMap 内部的 key 是无序的,TreeMap 的 key 是有序的。
3.2.1、遍历所有的key(keySet())
要遍历 Map 集合的 key 可以使用 for each 循环来遍历 Map 实例的 keySet() 方法返回的 Set 集合,该 Set 集合包含不重复的key的集合:
Map<String, Integer> map = new HashMap<>(); map.put("apple", 123); map.put("pear", 456); map.put("banana", 789); for (String key : map.keySet()) { //keySet()方法返回一个不包含重复key的set集合 Integer value = map.get(key); System.out.println(key + " = " + value); }
3.2.2、直接遍历key--value(entrySet())
同时遍历key和value可以使用for each循环遍历Map对象的entrySet()集合,它包含每一个key-value映射:
Map<String, Integer> map = new HashMap<>(); map.put("apple", 123); map.put("pear", 456); map.put("banana", 789); for (Map.Entry<String, Integer> entry : map.entrySet()) { String key = entry.getKey(); Integer value = entry.getValue(); System.out.println(key + " = " + value); }
3.3、覆写equals()和hashcode()方法
正确使用 Map 必须保证:
-
作为
key的对象必须正确覆写equals()方法,相等的两个key实例调用 eauals() 必须返回 true,不同的key返回false -
作为
key的对象还必须正确覆写hashCode()方法,且hashCode()方法要严格遵循以下规范:如果两个对象相等,则两个对象的hashCode()必须相等;如果两个对象不相等,则两个对象的hashCode()不要相等。
我们经常使用String作为key,因为String已经正确覆写了equals()和hashCode()方法。
3.3.1、覆写equals()方法
要想保证通过内容相同但不一定是同一个对象的 key 获取到同一个 value 值,必须得保证作为 key 的对象已经正确地覆写了 equals() 方法。
通过不是同一个对象,但是内容相同的 key 实例可以取到同一个 value 值,这是因为 Map 内部对 key 做比较是通过 equals 方法实现的,这一点和List查找元素需要正确覆写equals()是一样的,即正确使用Map必须保证:作为key的对象必须正确覆写equals()方法。
我们经常使用String作为key,因为String已经正确覆写了equals()方法。但如果我们放入的key是一个自己写的类,就必须保证正确覆写了equals()方法。
3.3.2、覆写hashcode()方法
Map 集合是通过 key 来计算出 value 存储的索引的,计算方式是调用了 key 对象的 hashcode() 方法,它返回一个 int 整数,HashMap 正是通过这个方法直接定位key对应的value的索引,继而直接返回value。
在正确实现equals()的基础上,我们还需要正确实现hashCode(),代码示例:
public class Person { String firstName; String lastName; int age; @Override int hashCode() { int h = 0; h = 31 * h + firstName.hashCode(); h = 31 * h + lastName.hashCode(); h = 31 * h + age; return h; } //为了避免firstName或lastName为null,代码抛NullPointerException异常,hashCode方法可以这么写 @Override int hashCode() { return Objects.hash(firstName, lastName, age); } }
equals()方法中用到的用于比较的每一个字段,都必须在hashCode()中用于计算;equals()中没有使用到的字段,绝不可放在hashCode()中计算。
3.4、TreeMap(元素有序)
HashMap 内部的 key 是无序的,还有一种Map,它在内部会对Key进行排序,这种Map就是SortedMap。注意到SortedMap是接口,它的实现类是TreeMap。TreeMap不使用equals()和hashCode(),所以不需要覆写equals和hashCode方法。
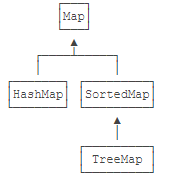
SortedMap保证遍历时以Key的顺序来进行排序。例如,放入的Key是"apple"、"pear"、"orange",遍历的顺序一定是"apple"、"orange"、"pear",因为String默认按字母排序:
使用TreeMap时,放入的Key必须实现Comparable接口。String、Integer这些类已经实现了Comparable接口,因此可以直接作为Key使用。
如果作为Key的class没有实现Comparable接口,那么,必须在创建TreeMap时传入Comparator即指定一个自定义排序算法:
import java.util.*; public class Main { public static void main(String[] args) { Map<Person, Integer> map = new TreeMap<>(new Comparator<Person>() { //在创建 TreeMap 时传入一个排序算法 public int compare(Person p1, Person p2) { return p1.name.compareTo(p2.name); } }); map.put(new Person("Tom"), 1); map.put(new Person("Bob"), 2); map.put(new Person("Lily"), 3); for (Person key : map.keySet()) { System.out.println(key); // {Person: Bob}, {Person: Lily}, {Person: Tom} } System.out.println(map.get(new Person("Bob"))); // 2 } } class Person { public String name; Person(String name) { this.name = name; } public String toString() { return "{Person: " + name + "}"; } } //比较的值是数字 Map<Student, Integer> map = new TreeMap<>(new Comparator<Student>() { public int compare(Student p1, Student p2) { if (p1.score == p2.score) { return 0; } return p1.score > p2.score ? -1 : 1; //或者可以直接借助Integer.compare(int, int)也可以返回正确的比较结果,就不用写上面这么多判断了 } });
4、Set 集合(元素不重复)
Set用于存储不重复的元素集合,它主要提供以下几个方法:
添加元素:boolean add(E e)- 删除元素:
boolean remove(Object e) - 判断是否包含元素:
boolean contains(Object e)
代码示例:
Set<String> set = new HashSet<>(); System.out.println(set.add("abc")); // true System.out.println(set.add("abc")); // false,添加失败,因为元素已存在,不可添加重复元素 System.out.println(set.contains("abc")); // true,元素存在 System.out.println(set.contains("xyz")); // false,元素不存在 System.out.println(set.remove("hello")); // false,删除失败,因为元素不存在 System.out.println(set.size()); // 1,一共1个元素
放入Set的元素和Map的key类似,都要正确实现 equals() 和 hashCode()方法,否则该元素无法正确地放入 Set。
最常用的Set实现类是HashSet,实际上,HashSet仅仅是对HashMap的一个简单封装。
继承关系:

4.1、HashSet
Set接口并不保证有序,而SortedSet接口则保证元素是有序的。HashSet 是无序的,它实现了Set接口,但没有实现SortedSet接口;
当向一个 HashSet 集合存入一个元素时,HashSet 会调用该对象的 hashCode() 方法来得到该对象的 hashCode 值,然后根据 hashCode值决定该元素在 HashSet 中的存储位置。如果两个元素的 equals 方法返回 true,但它们的 hashCode() 返回值不相等,那这两个元素仍然可以添加成功,hashSet 会将它们存储在不同的位置。
HashSet 集合判断两个元素相等的标准:两个对象通过 equals() 方法比较返回 true,并且两个对象的 hashCode() 方法返回值也相等。
如果两个对象通过 equals() 方法返回 true,这两个对象的 hashCode 值也应该相同。
HashSet 是无序的,可以存放 null。
public class Main { public static void main(String[] args) { Set<String> set = new HashSet<>(); set.add("apple"); set.add("banana"); set.add("pear"); set.add("orange"); for (String s : set) { System.out.println(s); //乱序输出 banana apple pear ... } } }
4.2、TreeSet
TreeSet 是有序的,因为它实现了SortedSet接口。在遍历TreeSet时,输出就是有序的,顺序按插入的元素ASCll码排序。
public class Main { public static void main(String[] args) { Set<String> set = new TreeSet<>(); set.add("apple"); set.add("banana"); set.add("pear"); set.add("orange"); for (String s : set) { System.out.println(s); //输出apple banana orange pear } } }
使用TreeSet和使用TreeMap的要求一样,添加的元素必须正确实现Comparable接口,如果没有实现Comparable接口,那么创建TreeSet时必须传入一个Comparator对象。
5、迭代器的使用
迭代器是一种设计模式,它是一个对象,它可以遍历并选择序列中的对象,而开发人员不需要了解该序列的底层结构。迭代器通常被称为“轻量级”对象,因为创建它的代价小。
Java中的Iterator功能比较简单,并且只能单向移动:
- 使用 iterator() 方法会返回一个 Iterator 对象。第一次调用 Iterator 对象的 next() 方法时,它返回序列的第一个元素。(注意,iterator() 方法是 java.lang.Iterable接口,被 Collection 继承)
- 使用 next() 获得序列中的下一个元素
- 使用 hasNext() 检查序列中是否还有元素
- 使用 remove() 将迭代器新返回的元素删除
Iterator 是Java迭代器最简单的实现,为 List 设计的 ListIterator 具有更多的功能,它可以从两个方向遍历List,也可以从 List 中插入和删除元素。
list l = new ArrayList(); l.add("aa"); l.add("bb"); for (Iterator iter = l.iterator(); iter.hasNext();) { String str = (String)iter.next(); System.out.println(str); } /*迭代器用于 while 循环遍历 Iterator iter = l.iterator(); while(iter.hasNext()){ String str = (String) iter.next(); System.out.println(str); } */ /*迭代器用于 for each 循环遍历 for(Object obj : iter) { System.out.println(obj); } */