一、消息队列
1.如何保证消息队列的高可用?
1.1 kafka的高可用性
HA机制,就是Replication副本机制。只能读写leader。
多副本 -> leader & follower -> broker挂了重新选举leader即可对外服务。
2.如何保证消息不被重复消费(幂等性)?
幂等性:通俗点说,就一个数据,或者一个请求,给你重复来多次,你得确保对应的数据是不会改变的,不能出错。
可以基于数据库的唯一键来保证重复数据不会重复插入多条。
3.如何保证消息的可靠性传输(如何处理消息丢失的问题)?
分析生产者、消息队列和消费者哪个环节造成了消息丢失,然后解决。
kafka消费端丢失:kafka会自动提交offset,那么只要关闭自动提交offset,在处理完之后自己手动提交offset,就可以保证数据不会丢。但是此时确实还是会重复消费,比如你刚处 理完,还没提交offset,结果自己挂了,此时肯定会重复消费一次,自己保证幂等性就好了。
解决方案:关闭自动更新offset,等到数据被处理后再手动跟新offset。
在消费前做验证前拿取的数据是否是接着上回消费的数据,不正确则return先行处理排错。
一般来说zookeeper只要稳定的情况下记录的offset是没有问题,除非是多个consumer group 同时消费一个分区的数据,其中一个先提交了,另一个就丢失了。
4.如何保证消息的顺序性?
1)rabbitmq:拆分多个queue,每个queue一个consumer,就是多一些queue而已,确实是麻烦点;或者就一个queue但是对应一个consumer,然后这个consumer内部用内存队列做排队,然后分发给底层不同的worker来处理。
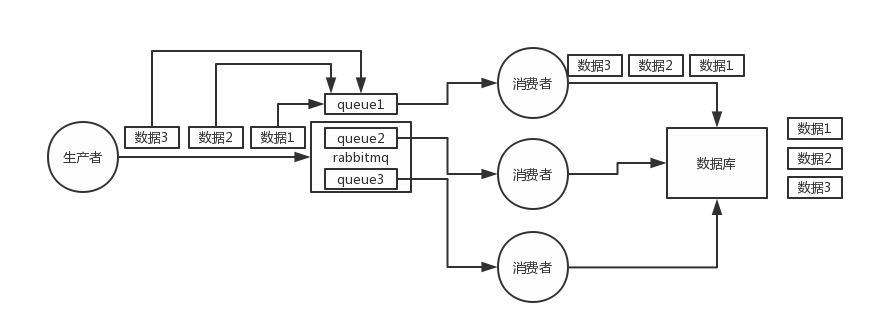
2)kafka:一个topic,一个partition,一个consumer,内部单线程消费,写N个内存queue,然后N个线程分别消费一个内存queue即可。

5.如何解决消息队列的延时以及过期失效问题?消息队列满了以后该怎么处理?有几百万消息持续积压几小时,怎么解决?
恢复消费端。
6.如果让你写一个消息队列,该如何进行架构设计啊?
参照kafka:broker -> topic -> partition
7.Kafka吞吐量高的原因?
Kafka快的原因是他将一个个消息变成一个文件,通过mmp提高IO速度,写入时在末尾直接添加,读取时通过偏移量直接返回。