淘宝天猫商品抓取
分类: python
数据来源 --TTyb 2017-11-11 858 1833
本文基于 360 浏览器查看源码, python3.4 编码 ,爬虫基础需要学习的请看 爬虫教程。
淘宝天猫的网页反爬虫很严重,存在大量的 验证码 、 登陆提示 、 浏览限制 等等机制,但是毕竟一山还有一山高,机器永远比不上人的聪明,所以我发现了一个抓取的方法。
任何网页存在反爬虫都是很棘手的,例如淘宝的反爬虫很严重。但是众所周知,手机端的页面往往比电脑端的页面好抓取,所以我打开了淘宝的手机端网页 https://m.taobao.com ,点击上面的搜索框,网页自动跳转:
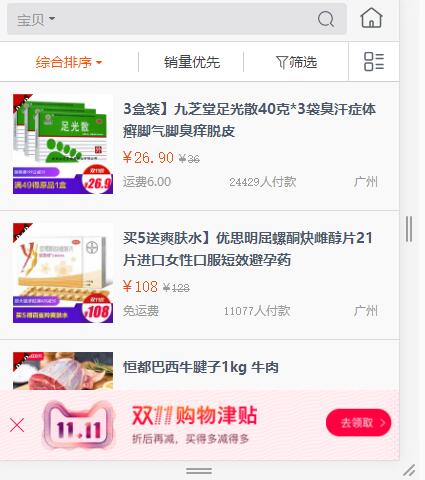
此时 网址已经变化成:
https://s.m.taobao.com/h5?search-btn=&event_submit_do_new_search_auction=1&_input_charset=utf-8&topSearch=1&atype=b&searchfrom=1&action=home%3Aredirect_app_action&from=1
F12 查看网址的表单,找到 Headers ,看到请求的 host 变成了 s.m.taobao.com ,请求携带的表单有:
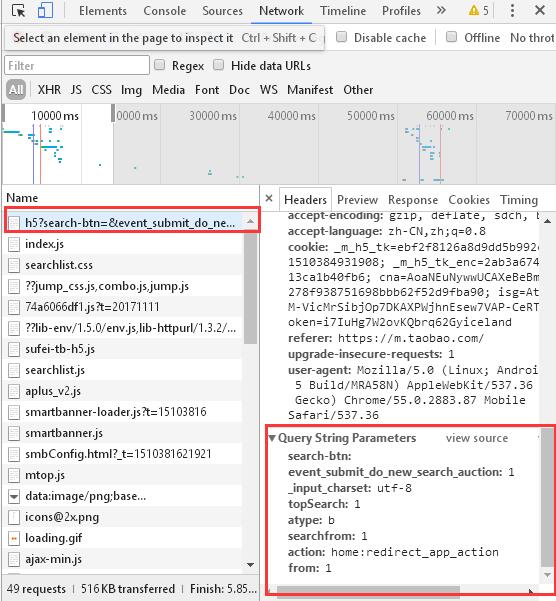
清除表单的信息,鼠标往下拉,看下翻页的信息:
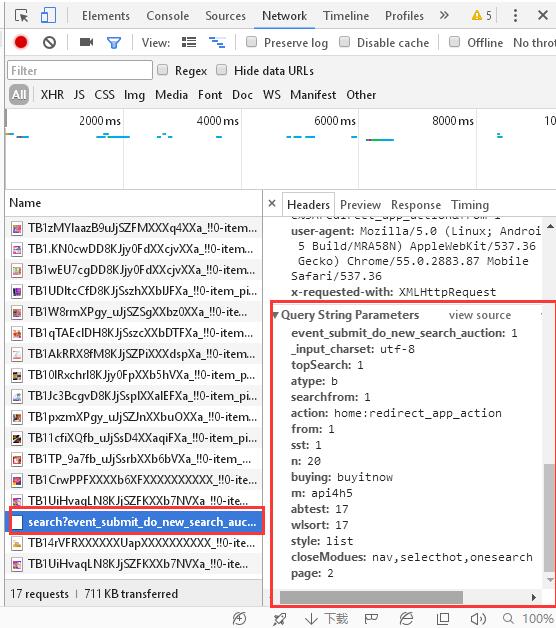
可以看到 get 的表单变成了:
event_submit_do_new_search_auction:1
_input_charset:utf-8
topSearch:1
atype:b
searchfrom:1
action:home:redirect_app_action
from:1
sst:1
n:20
buying:buyitnow
m:api4h5
abtest:17
wlsort:17
style:list
closeModues:nav,selecthot,onesearch
page:2
很明显的发现翻页的表单为 page ,数了一下每一页是 20 个商品的信息。这样就找到了翻页的部分。继续清除加载好的表单,搜索看一下:
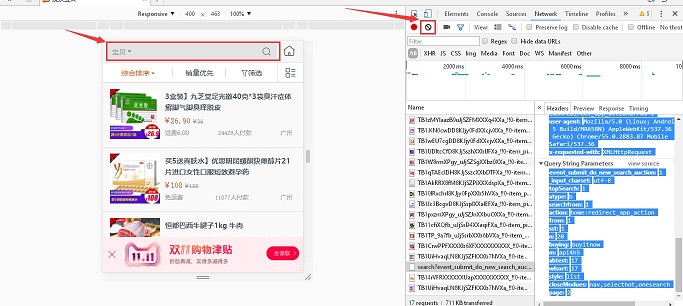
查看得到请求头是:
event_submit_do_new_search_auction:1
_input_charset:utf-8
topSearch:1
atype:b
searchfrom:1
action:home:redirect_app_action
from:1
sst:1
n:20
buying:buyitnow
q:Iphone
我搜索的是 Iphone ,基本确认 keyword 是 q 了,再搜索 Ipad 看一下,表单为:
q:Ipad
search:提交
tab:all
每次请求的表单都不一样,我把他们汇总在一起是这样子:
"event_submit_do_new_search_auction": "1",
"search": "提交",
"tab": "all",
"_input_charset": "utf-8",
"topSearch": "1",
"atype": "b",
"searchfrom": "1",
"action": "home:redirect_app_action",
"from": "1",
"q": keyword,
"sst": "1",
"n": "20",
"buying": "buyitnow",
"m": "api4h5",
"abtest": "30",
"wlsort": "30",
"style": "list",
"closeModues": "nav,selecthot,onesearch",
"page": page
只要请求的 url 携带这些参数就可以了。其中查看头部知道:
Referer="http://s.m.taobao.com"
Host="s.m.taobao.com"
到这里其实就可以写代码了,但是发现表单中出现了一个 style:list ,敏感的嗅觉觉得这里有猫腻,应该是展现的样式,所以我点击销量优先,发现 style:list 没变,但是增加了 sort:_sale ,这里会排序,再点其他发现如下信息:
综合排序sort:""
销量优先sort:_sale
价格低到高sort:bid
价格高到低sort:_bid
信用排序sort:_ratesum
起始价格:start_price:价格
终止加个:end_price:价格
既然这样已经找到请求表单,那么构造 python 爬虫代码,安装必要的爬虫库 pip3 install requests ,首先抓取首页保持爬虫链接,这个是为了使头部自动增加 cookie :
headers = {
"User-Agent": "Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5"
}
session = requests.session()
session.get("https://s.m.taobao.com/", headers=headers)
根据抓取到的表单构造 getdata :
getData = {
"event_submit_do_new_search_auction": "1",
"search": "提交",
"tab": "all",
"_input_charset": "utf-8",
"topSearch": "1",
"atype": "b",
"searchfrom": "1",
"action": "home:redirect_app_action",
"from": "1",
"q": keyword,
"sst": "1",
"n": "20",
"buying": "buyitnow",
"m": "api4h5",
"abtest": "30",
"wlsort": "30",
"style": "list",
"closeModues": "nav,selecthot,onesearch",
"page": page
}
url 前缀 preUrl = "http://s.m.taobao.com/search?" ,升级头部使其携带 Referer 和 Host :
# 升级头部
headers.update(
dict(Referer="http://s.m.taobao.com", Host="s.m.taobao.com"))
抓取网页:
# 抓取网页
aliUrl = session.get(url=preUrl, params=getData, headers=headers)
输入关键词和页数,打印抓取下来的东西,居然发现是 json :
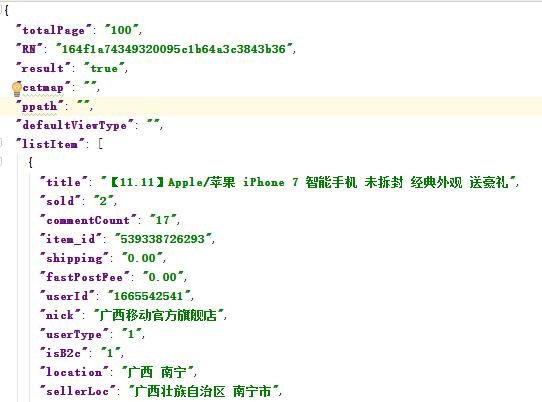
这样就很满足了,解析这段 json :
dictInfo = json.loads(content.decode("utf-8", "ignore"))
infoList = dictInfo["listItem"]
由于我抓取的是 1 页,所以得到 20 个商品的 infoList ,infoList 里面的每个元素都是一个字典,提取 dict 里面的店铺信息:
for dict in infoList:
store = dict["nick"]
print(store)