一般大数据的工具包都是tar包,直接下载下来,然后进行解压缩,修改配置文件,最后执行对应的sh文件。
1.phoenix
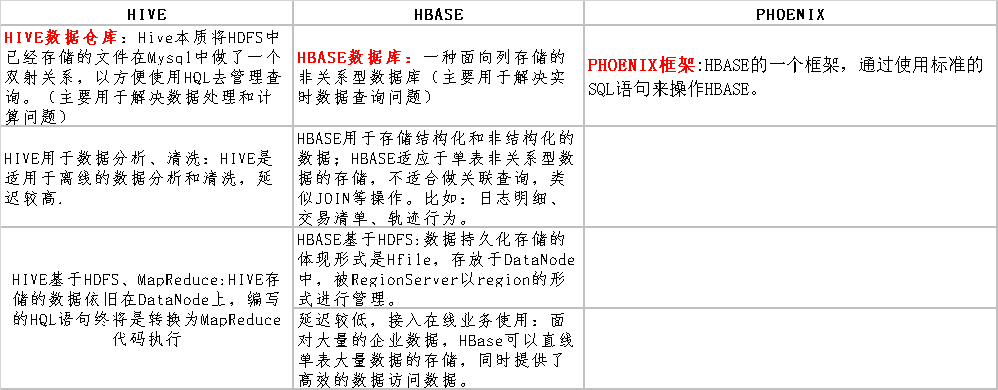
phoenix:JAVA语言编写,查询引擎会将SQL查询语句转化成一个或多个HBase Scanner,且并行执行生成标准的JDBC结果集。phoenix使用标准JDBC API代替HBase客户端API来创建表、插入数据和查询HBase数据。我可以理解为phoenix是HBASE的一个框架,通过使用标准的SQL语句来操作HBASE。
phoenix语法:https://phoenix.apache.org/language/index.html
phoenix函数:https://phoenix.apache.org/language/functions.html
phoenix支持的数据类型:https://phoenix.apache.org/language/datatypes.html
phoenix参考语句:
UPSERT INTO TEST VALUES('foo','bar',3); UPSERT INTO TEST(NAME,ID) VALUES('foo',123); UPSERT INTO TEST(ID, COUNTER) VALUES(123, 0) ON DUPLICATE KEY UPDATE COUNTER = COUNTER + 1; UPSERT INTO TEST(ID, MY_COL) VALUES(123, 0) ON DUPLICATE KEY IGNORE; SELECT * FROM TEST LIMIT 1000; SELECT * FROM TEST LIMIT 1000 OFFSET 100; SELECT full_name FROM SALES_PERSON WHERE ranking >= 5.0 UNION ALL SELECT reviewer_name FROM CUSTOMER_REVIEW WHERE score >= 8.0
2.HBASE
HBASE是一个高可靠、高性能、面向列、可伸缩的分布式存储系统,与HDFS一样都是分布式存储系统,而且HBASE还是利用HADOOP HDFS作为文件存储系统,利用ZK作为协同服务。之所以有HBASE的存在,目的是弥补HDFS只能存储和MP不能进行实时计算的问题。
比如HBASE的操作:
- 下载hbase包:hbase-0.95-SNAPSHOT.tar.gz
- 执行hbase压缩后的包:./bin/start-hbase.sh
- 执行hbase shell文件:./bin/hbase shell
create 'test', 'cf' list 'test' put 'test', 'row1', 'cf:a', 'value1' put 'test', 'row2', 'cf:b', 'value2' put 'test', 'row3', 'cf:c', 'value3' put 'test', 'row4', 'cf:d', 'value4' scan 'test' get 'test', 'row1' disable 'test' enable 'test'
HBASE中文:http://abloz.com/hbase/book.html#datamodel
HBASE官网:http://hbase.apache.org/1.4/book.html
3.HIVE
Hive:提供了一系列的工具,可以用来进行数据提取转化加载(ETL),Hive定义了简单的类SQL查询语言,称为QL,它允许熟悉SQL的用户查询数据。本质上讲,Hive是一个SQL解析引擎,有一套映射工具metastore,可以把SQL转换为MapReduce中的job,可以把SQL中的表、字段转换为HDFS中的文件(夹)以及文件中的列,存放在derby、mysql中。我所理解的HIVE的这样一个功能就实现了把放在hadoop下的数据与关系型数据展示上联系起来了。
HIVE更详细的资料:https://www.cnblogs.com/wendyw/p/11389971.html
4.HBASE、HIVE、phoenix三者之间的关系
5.python之三方库HappyBase
通过python的三方库happyBase,可以对hbase进行连接使用。
happybase三方库参考文档:https://happybase.readthedocs.io/en/latest/user.html