我们经常能看到如下的逻辑架构图,但是往往不能进行很好的记忆,看过就忘记了,也不知道它的实现方式。今天通过简单的画图来简单了解一下mysql到底是如何执行一个select语句,如何update一条语句。
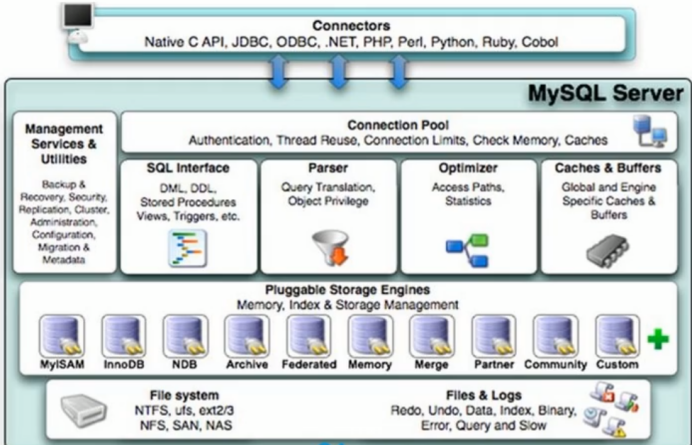
1、Mysql逻辑架构图
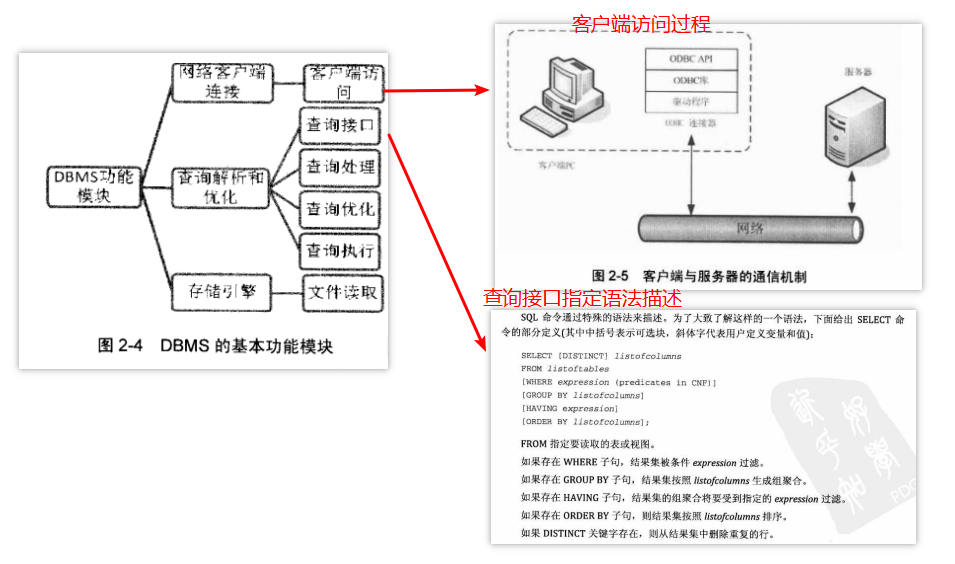
场景一:一条SQL语句如何执行?
1.1 一条SQL语句的执行过程
如图:
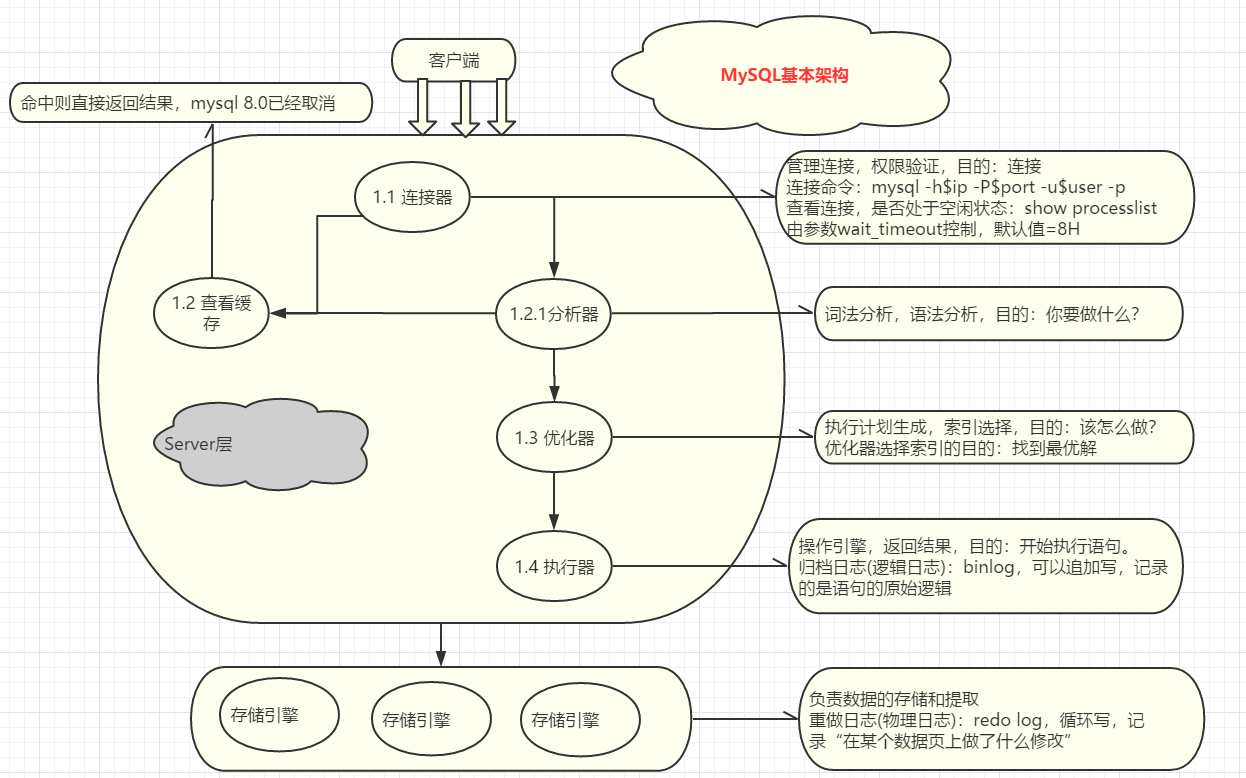
大体来说,MySQL可以分为Server层和存储引擎层两部分。
Server层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖MySQL的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
而存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持InnoDB、MyISAM、Memory等多个存储引擎。现在最常用的存储引擎是InnoDB,它从MySQL 5.5.5版本开始成为了默认存储引擎。
也就是说,你执行create table建表的时候,如果不指定引擎类型,默认使用的就是InnoDB。不过,你也可以通过指定存储引擎的类型来选择别的引擎,比如在create table语句中使用engine=memory, 来指定使用内存引擎创建表。不同存储引擎的表数据存取方式不同,支持的功能也不同。 不同的存储引擎共用一个Server层,也就是从连接器到执行器的部分。
A.连接器:show processlist; 查看连接状态,Sleep表示空间连接,query表示操作状态

B.分析器:如果没有命中查询缓存,就要开始真正执行语句了。首先,MySQL需要知道你要做什么,因此需要对SQL语句做解析。
分析器先会做“词法分析”。你输入的是由多个字符串和空格组成的一条SQL语句,MySQL需要识别出里面的字符串分别是什么,代表什么。
MySQL从你输入的"select"这个关键字识别出来,这是一个查询语句。它也要把字符串“T”识别成“表名T”,把字符串“ID”识别成“列ID”。
做完了这些识别以后,就要做“语法分析”。根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个SQL语句是否满足MySQL语法。
C.优化器:经过了分析器,MySQL就知道你要做什么了。在开始执行之前,还要先经过优化器的处理。
1.2 执行器的执行流程

D.执行器:MySQL通过分析器知道了你要做什么,通过优化器知道了该怎么做,于是就进入了执行器阶段,开始执行语句。
比如我们这个例子中的表T中,ID字段没有索引,那么执行器的执行流程是这样的:
-
调用InnoDB引擎接口取这个表的第一行,判断ID值是不是10,如果不是则跳过,如果是则将这行存在结果集中;
-
调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行。
-
执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。
总结,MySQL包含如下子系统和核心库:
- 网络连接和网络通信协议子系统[NET协议建立在TCP/IP协议栈上,为上层其他子系统提供数据包的读、写、解析和发送]
- 线程、进程和内存分配子系统[自启动准备过程]
- 查询解析和查询优化子系统
- 存储引擎接口子系统
- 各类存储接口子系统
- 安全管理子系统[验证和访问控制等手段来保护服务器]
- 日志子系统[Error日志、查询日志、慢查询日志、二进制日志]
- 其他子系统-如复制功能、错误处理
- mysys核心库文件
2、Mysql日志系统
日志系统只要有2个模块:存储引擎里的redo log重做日志;服务器-执行器中的binlog归档日志。
说到日志系统,需要了解几个概念:creash-safe、redo log、binlog、WAL技术。
Redo log:用于保证crash-safe能力。innodb_flush_log_at_trx_commit =1表示每次事务的redo log 都持久化到磁盘,保证mysql异常重启之后数据不丢失。Sync_binlog=1参数设置为1,表示每次事务的binlog都持久化到磁盘,保证mysql异常重启之后binlog不丢失。
Crash-safe:有了redo log,InnoDB就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失。
WAL技术:Write-Ahead Loggin,先记录到归档日志redo log里面,更新完成。InnoDB引擎在适当的时候,将这个更新记录更新到(服务器-执行器)磁盘。(闲时)
PS:归档日志大小可以进行配置
2.1 redo log日志与change buffer的区别
redo log:主要节省的是随机写磁盘的IO消耗(转成顺序写)。
change buffer:主要节省的则是随机读磁盘的IO消耗。
2.2 场景一:一条SQL更新语句是如何执行的?
前提:创建表 create table T(ID int primary key,c int),插入一条ID=2的语句。
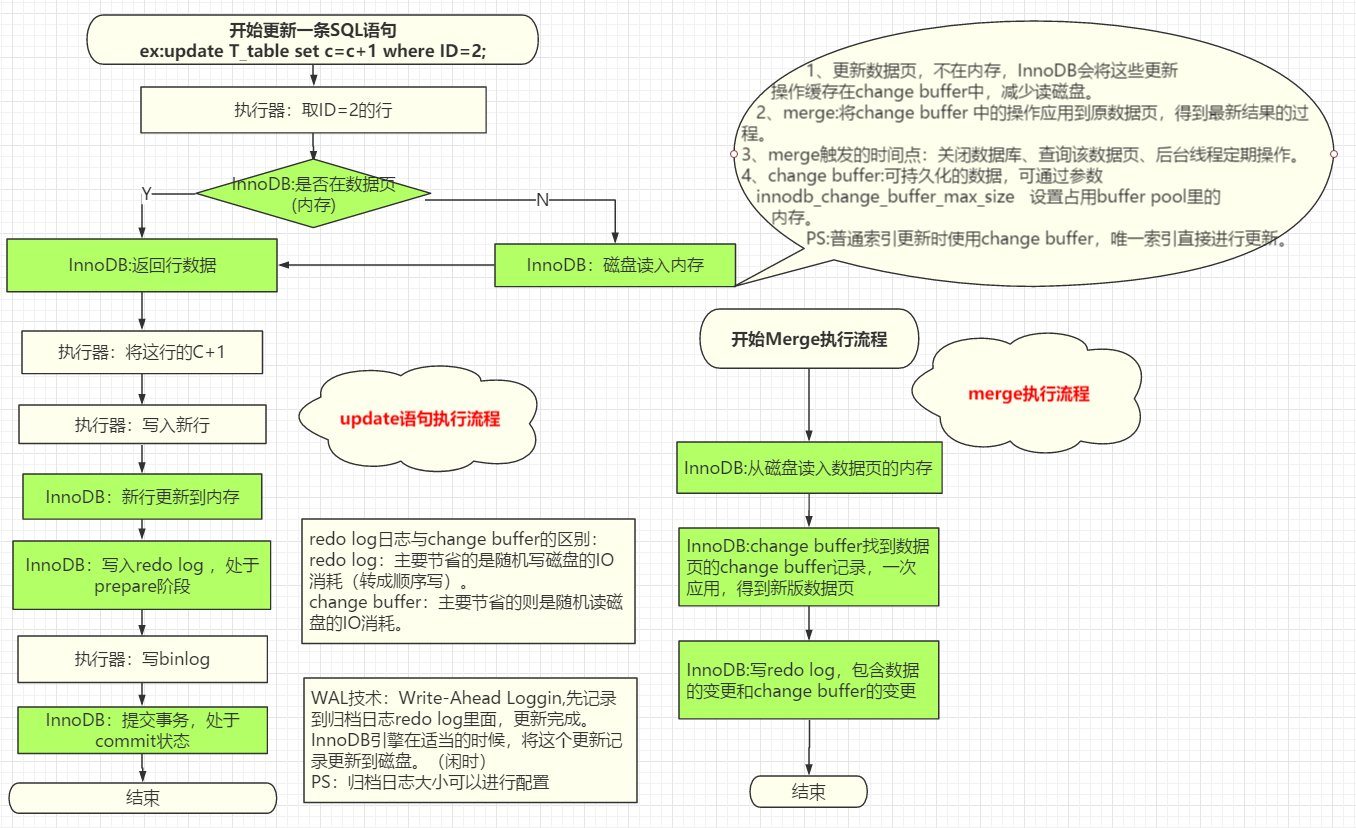
更新语句不在内存时的操作过程:并不会立马从磁盘去读入内存
1、更新数据页,不在内存,InnoDB会将这些更新操作缓存在change buffer中,减少读磁盘。
2、merge:将change buffer 中的操作应用到原数据页,得到最新结果的过程。
3、merge触发的时间点:关闭数据库、查询该数据页、后台线程定期操作。
4、change buffer:可持久化的数据,可通过参数innodb_change_buffer_max_size 设置占用buffer pool里的内存。
PS:普通索引更新时使用change buffer,唯一索引直接进行更新。