1 HDFS 架构
HDFS作为分布式文件管理系统,Hadoop的基础。HDFS整体架构包括:NameNode、DataNode、Secondary NameNode,如图:
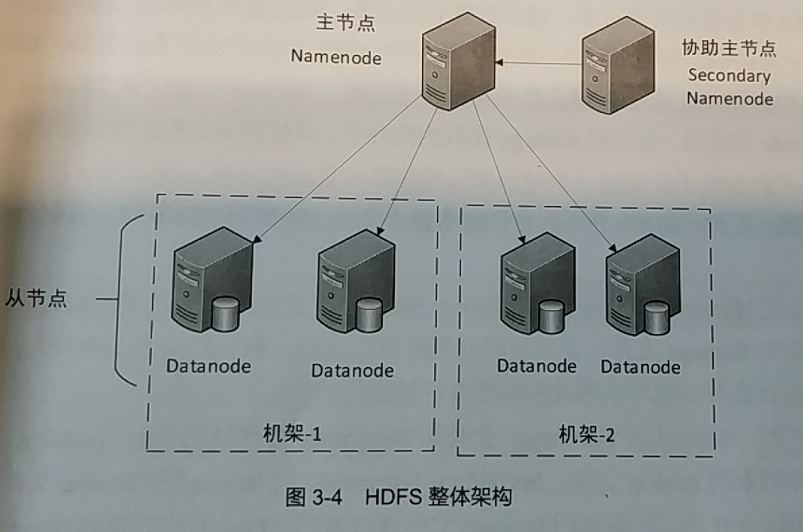
HDFS采用主从式的分布式架构。
- Namenode:是主节点,负责存储文件的元数据,包括目录、文件、权限等信息和文件分块、副本存储等。Namenode会对HDFS的全局情况进行管理。
- Datanode:是从节点,负责自身存储的数据块(block),根据Namenode的指令,对本身存储的文件数据块进行读写,并且对数据块进行定期自检,向Namenode上报节点与数据的健康情况,Namenode根据Datenode的上报信息,决定是否对数据存储状况进行调整,并将超时(默认是10分钟)未上报数据的Datanode标记为异常状态。一台主机只部署一个Datanode角色。
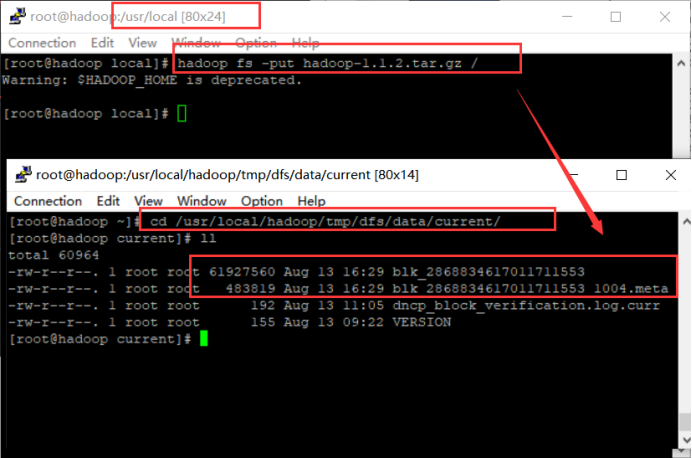
Hadoop shell上传的文件是存放在DataNode的block中,通过linux shell只能看到block,不能看到文件。
HBase、Hive、Solr等分布式数据库或数据仓库均使用HDFS作为其底层存储系统。
以下是本章的重点:
- 分布式文件系统与HDFS
- HDFS体系结构与基本概念
- HDFS的shell操作
2 分布式文件系统与HDFS
DFS:Distributed File System
分布式文件管理系统:数据量越来越多,在一个操作系统管辖的范围存不下,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件。分布式文件管理系统就是一种允许文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和存储空间。
HDFS只是DFS中的一种,适应于一次写、多次查询的情况,不支持并发写情况,小文件不合适。HDFS:把客户端的大文件存放在很多节点的数据块中,记住三个关键词:文件、节点、数据块。
从分布式存储的角度看,HDFS的主要优势在于:
- 将大文件分块,实现元数据统一管理,数据分布式存储,且具有良好的横向扩展性.
- 实现数据的多副本存储,不必担心由于节点或网络故障造成的数据不可用.
- 隐藏分块,副本等存储细节,上层应用可以通过类POSIX接口实现文件读写.
更简单的一点来说:HDFS就是windows中存在的文件系统。
3 HDFS的shell操作
HDFS是存取数据的分布式文件系统,对HDFS的操作,就是文件系统的基本操作,比如文件的创建、修改、删除、修改权限等,文件夹的创建、删除、重命名等。对HDFS的操作命令类似于linux的shell对文件的操作,如ls、mkdir、rm等。
对hdfs的操作方式:hadoop fs xxx
- hadoop fs -ls / ----查看hdfs根目录下的内容的
- hadoop fs -lsr / ----递归查看hdfs的根目录下的内容的
- hadoop fs -mkdir /d1 ----在hdfs上创建文件夹d1
- hadoop fs -put <linux source > <hdfs destination> ----把数据从linux上传到hadfs的特定路径中
- hadoop fs -get <hdfs source> <linux destination>----把数据从hdfs下载到linux的特定路径下
- hadoop fs -text <hdfs文件> ----查看hdfs文件
- hadoop fs -rm 删除具体的文件 ----删除hdfs中文件
- hadoop fs -rmr 删除具体的文件夹 ----删除hdfs中的文件夹
具体命令:
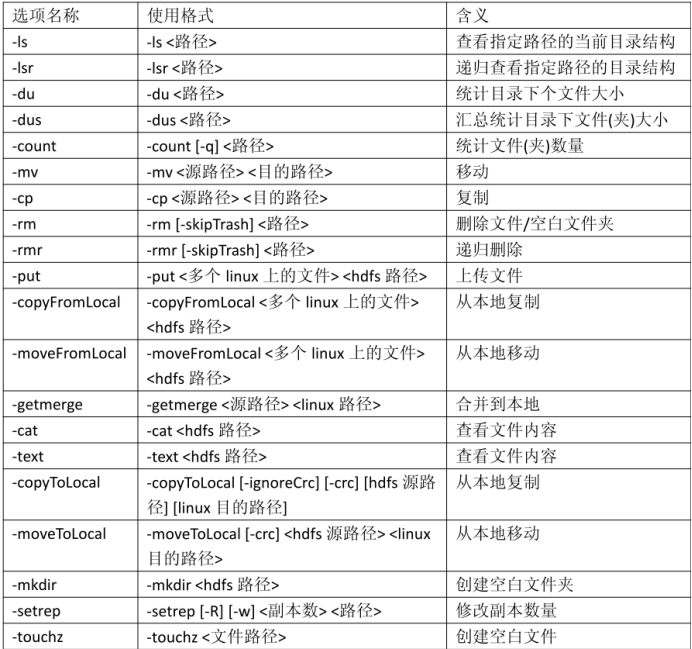
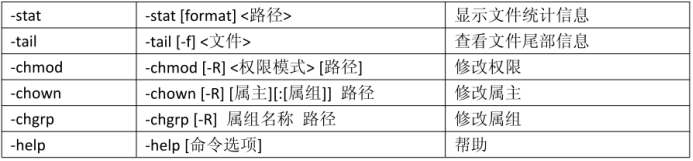
注意:以上表格中对于路径,包括 hdfs 中的路径和 linux 中的路径。对于容易产生歧义的地方,会特别指出“linux 路径”或者“hdfs 路径”。如果没有明确指出,意味着是 hdfs路径。
比如:

红框内-内容格式如下:l
-首字母表示文件夹(如果是“d”)还是文件(如果是“-”);
-后面的 9 位字符表示权限;
-后面的数字或者“-”表示副本数。如果是文件,使用数字表示副本数;文件夹没有副本;
-后面的“root”表示属主;
-后面的“supergroup”表示属组;
-后面的“0”、“6176”、“37645”表示文件大小,单位是字节;
-后面的时间表示修改时间,格式是年月日时分;
-最后一项表示文件路径。
hdfs帮助文档:hadoop fs -help +具体的命令


4 NameNode(管理节点)的数据结构
NameNode:将文件系统的元数据信息存储为fsimage文件。该文件在Namenode启动时被加载到内存中,之后该文件(及内存文件)一直保持只读状态。在fsimage文件中,每一条目录、文件或数据块信息基于大约占用150个字节。
查询时,直接从内存查;修改时,则不能直接从内存或磁盘中修改fsimage文件,而是将修改事务写到一系列新的editlog文件中。editlog文件会定期合并,形成新的fsimage文件,例如在Namenode再次启动时。
Namenode各个角色部署在linux系统之上,一般文件都存在linux本地文件系统中。

NameNode作用是管理文件目录结构,是管理数据节点。
名字节点维护两套数据,一套是文件目录与数据块之间的关系,另一套是数据块与节点之间的关系。前一套数据是静态的,是存放在磁盘上的,通过fsimage和edits文件来维护;后一套数据是动态的,不持久化到磁盘的,每当集群启动的时候,会自动建立这些信息。
NameNode包含整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表,接收用户的操作请求。core-default.xml中的dfs.name.dir属性、dfs.name.edits.dir属性,配置的是NameNode的核心文件fsimage、edits的存放位置。
文件包括:
- fsimage:元数据镜像文件,存储某一时段NameNode内存元数据信息。
- edits:操作日志文件
- fstime:保存最近一次checkpoint的时间
以上这些文件是保存在linux的文件系统中。
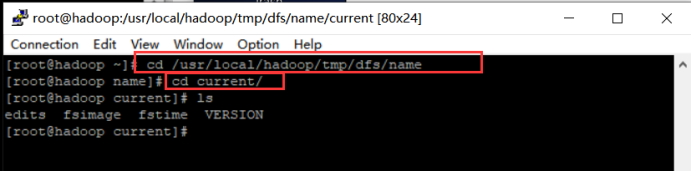
具体路径:/usr/local/hadoop/tmp、/usr/local/hadoop/tmp/dfs/name目录下。
5 SecondaryNameNode
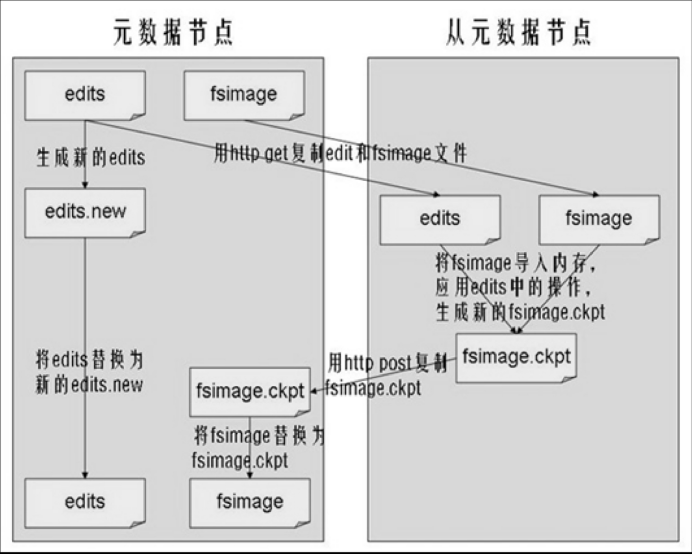
SecondaryNameNode作用:为了降低Namenode的压力,SecondaryNameNode角色可以负责将fsimage和editlog文件进行合并,形成新的fsimage文件。
执行过程:Secondary NameNode会通知Namenode暂停使用当前的editlog,Namenode会将新纪录写入一系列新的editlog文件。Secondary NameNode将fsimage和editlog文件通过HTTP协议复制到本地,进行合并后,再将新的fsimage文件通过HTTP Post方式复制到Namenode。Namenode会用新的fsimage代替旧的文件,将其读入内存。
或者从NameNode上下载元数据信息(fsimage,edits),然后把二者合并,生成新的fsimage,在本地保存,并将其推送到NameNode,同时重置NameNode的edits.
默认在安装在NameNode节点上。
合并原理:

6 Datanode(存储数据)
DataNode作用:HDFS中真正存储数据的。
提供真实文件数据的存储服务:
- 文件块(block):最基本的存储单位。对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block.HDFS默认Block大小是64MB,以一个256MB文件,共有256/64=4个Block。core-default.xml中找到参数ds.block.name去修改block的大小。
- 不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间。
- replication,多复本。默认是三个。hdfs-site.xml的dfs.replication属性。
DataNode存放的目录:core-default.xml中参数dfs.data.dir的值就是block存放在linux文件系统中的位置。



7 数据分块和多副本机制
HDFS采用了数据分块(block)存储和分块多副本两种重要的机制。
7.1 数据分块
文件分块机制使HDFS可以利用分布式方法存储大于单节点或单磁盘存储容量的文件。
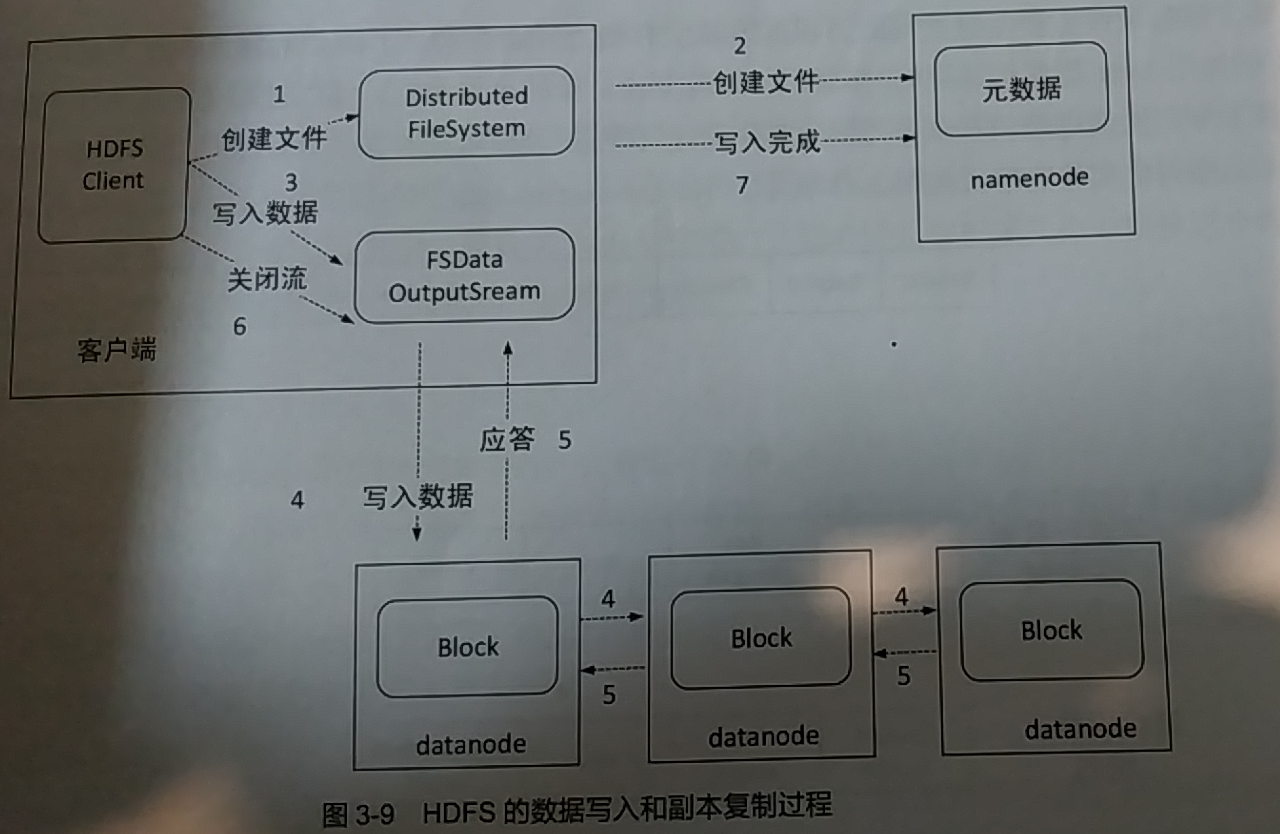
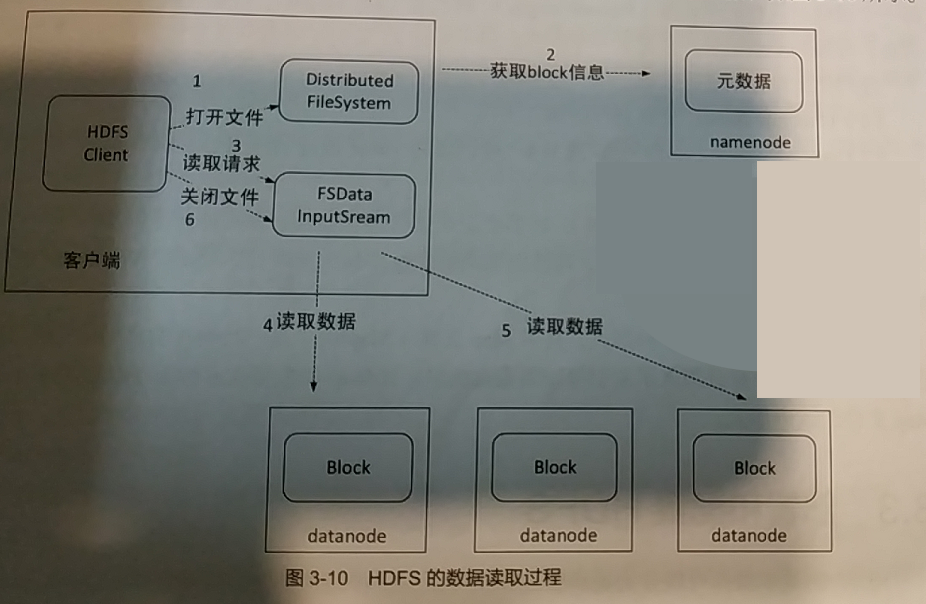
HDFS将文件分割成数据块,具体大小视用户配置而定,一般64~256MB。写入文件时,Namenode会指示客户端将文件切成小块,并且将数据块存储在多个Datanode上,Namenode会记录文件的分块存储情况。读取文件时,Namenode会根据客户端到相应的Datanode读取所需的数据块。
数据分块存储在各个Datanode的本地文件系统中,路径由用户配置文件指定。
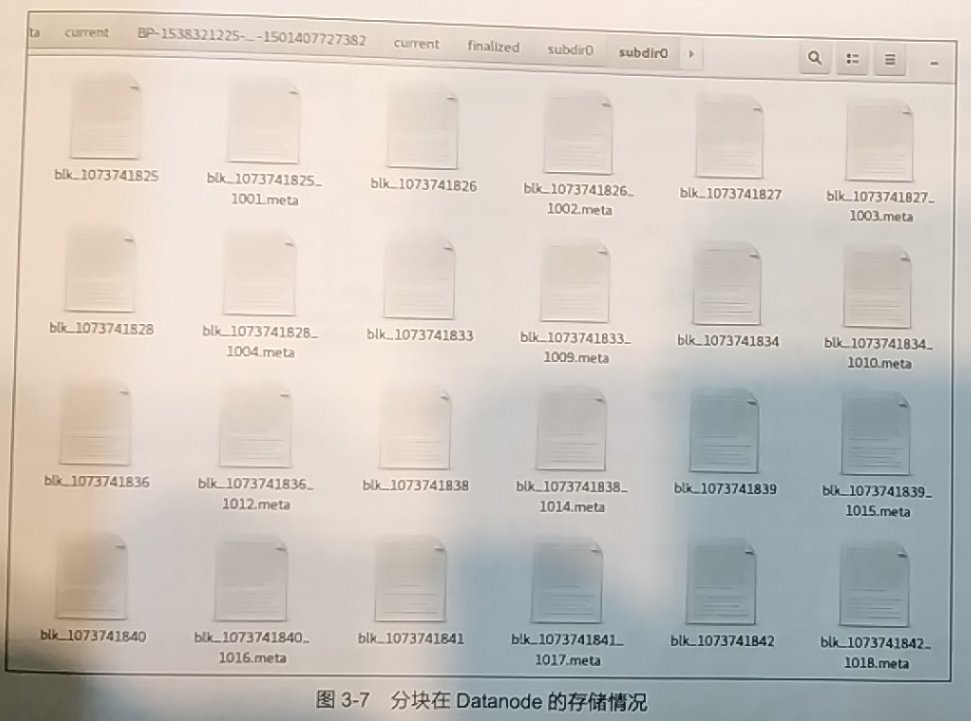
其中.meta的文件为分块的元数据信息,blk_xxx即为分块文件,除此之外,Datanode还可以本地保存若干集群信息、版本信息或临时文件等。
HDFS分块目的:一方面是有利于分布式环境下的均匀存储和分区容错,另一方面是MapReduce等分布式架构进行数据处理时,方便将数据一次性读入内存,当Map出现故障时,也有利于任务恢复。
7.2 数据多副本机制
HDFS默认情况下,可以将数据块复制为三个副本。
8 HDFS存在的问题
- HDFS不支持随机改写,数据都是一次写入,多次读取的.
- HDFS没有表的概念,无法定义列名等信息
- HDFS无法针对行数统计,过滤扫描等常见数据查询功能实现快捷操作,需要通过MapReduce编程实现,且无法实现实时检索.