1 Hadoop环境搭建
hadoop 的6个核心配置文件的作用:
- core-site.xml:核心配置文件,主要定义了我们文件访问的格式hdfs://。
- hadoop-env.sh:主要配置我们的java路径。
- hdfs-site.xml:主要定义配置我们的hdfs的相关配置。
- mapred-site.xml:主要定义我们的mapreduce相关的一些配置。
- slaves:控制我们的从节点在哪里,datanode nodemanager在哪些机器上。
- yarn-site.xml:配置我们的resourcemanager资源调度。
2 Hadoop部署方式:本地模式、伪分布模式、集群模式
- 安装前准备工作:virtualbox、jdk、hadoop-1.1.2.tar.gz
- 本文主要是通过伪分布模式进行安装,伪分布模式安装步骤:关闭防火墙、修改ip、修改hostname、设置SSH自动登录、安装jdk、安装hadoop
2.1 Hadoop伪分布具体安装步骤
——前提条件:【使用root用户登录】
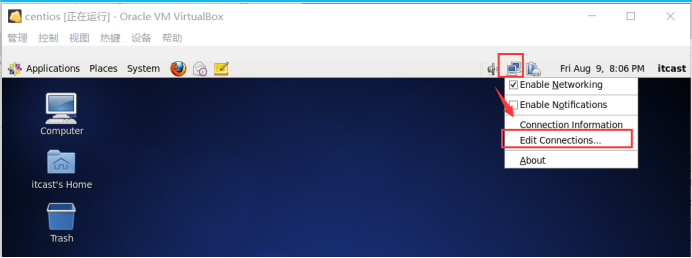
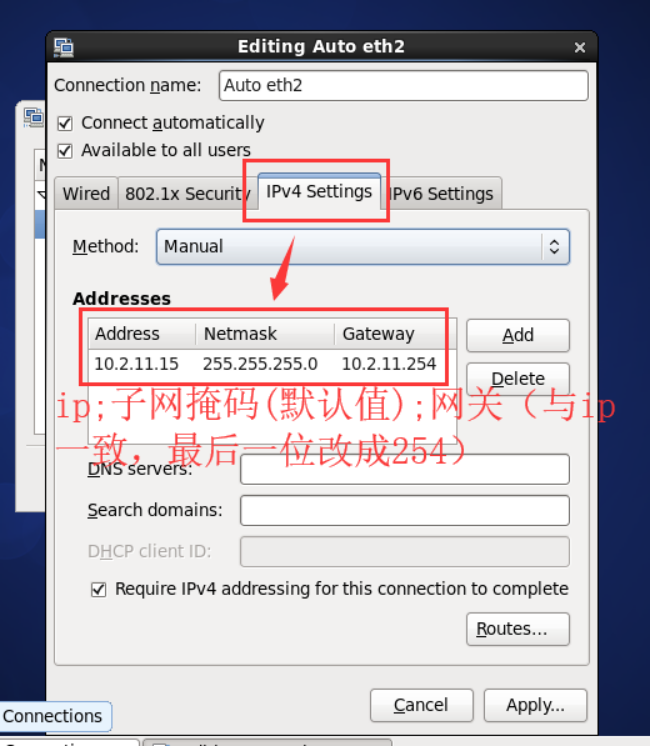
A.设置静态ip
在centos桌面右上角的图标上,右键修改,或者执行命令 vi /etc/sysconfig/network-scripts/ifcfg-eth2
重启网卡 执行命令service network restart
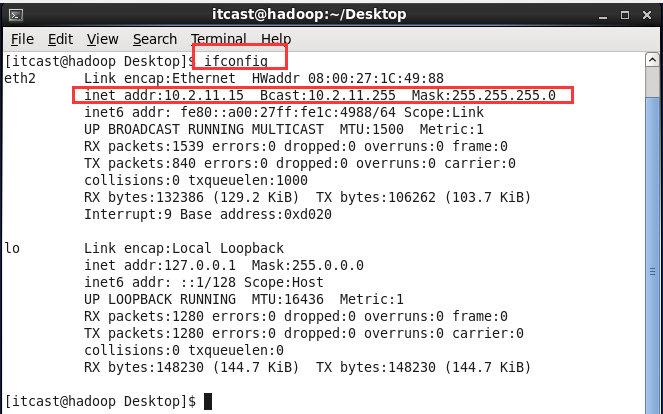
验证:执行命令ifconfig
B.修改主机名
步骤(1)和(2)最好操作步骤二
(1)修改当前会话中的主机名,执行命令 vi /etc/sysconfig/network
(2) 修改配置文件中的主机名,执行命令vi /etc/hosts
验证:重启机器 reboot -h now

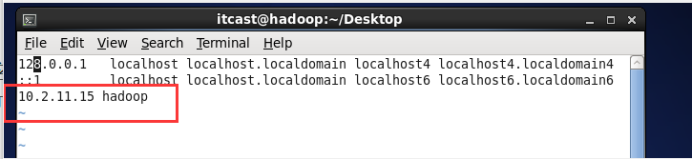
C.把hostname和ip绑定
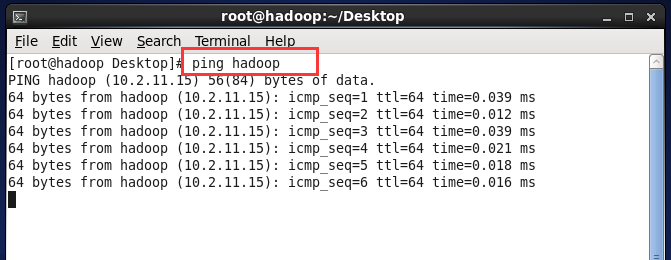
执行命令vi /etc/hosts,增加一行内容,如下:10.2.11.15 hadoop 保持退出
验证ping hadoop

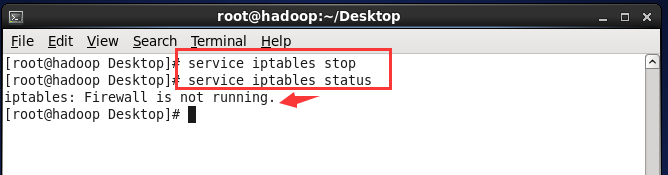
D.关闭防火墙
执行命令 service iptables stop
验证:service iptables status
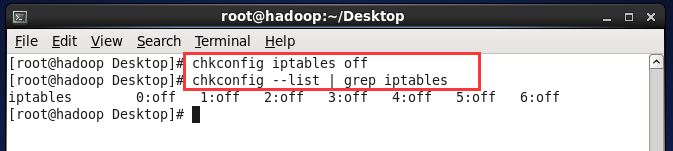
E.关闭防火墙的自动运行
执行命令 chkconfig iptables off
验证:chkconfig --list | grep iptables
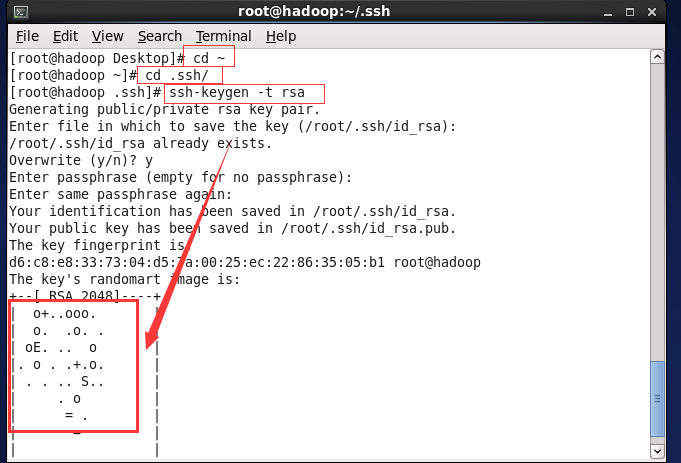
F.SSH(secure shell)的免密登录
存放在cd下的ssh目录下(cd ~ cd .ssh/)
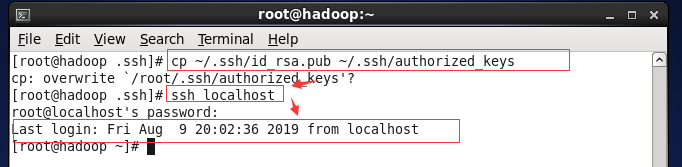
(1) 执行命令 ssh-keygen -t rsa 产生秘钥,位于~/ .ssh 文件夹
(2) 执行命令 cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
验证:ssh localhost
G.安装jdk
(1) 执行命令rm -rf /usr/local/* 删除所有内容

(2)使用winscp把jdk、hadoop文件从windows复制到/usr/downloads目录下

(3)执行命令 chmod u+x jdk-6u24-linux-i586.bin 赋予执行
(4)执行命令./jdk-6u24-linux-i586.bin 解压缩
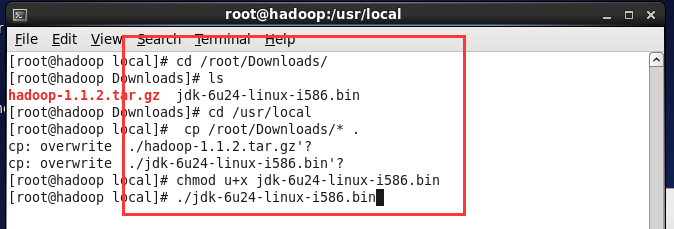
(5)执行命令mv jdk1.6.0_24 jdk 重命名

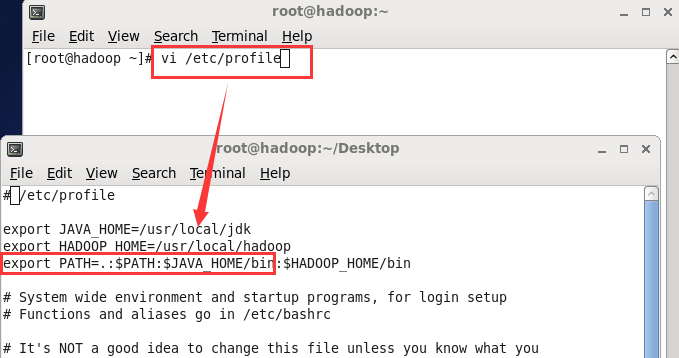
(6)执行命令vi /etc/profile 设置环境变量,增加2行内容
Export JAVA_HOME=/usr/local/jdk
Export PATH=.:$PATH:JAVA_HOME/bin
保持退出
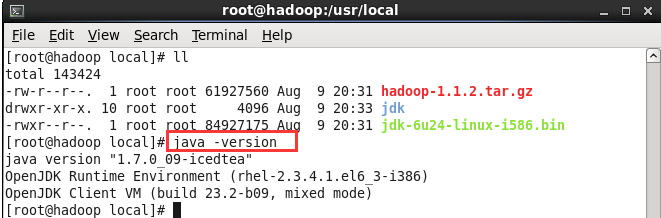
执行命令立即生效 source /etc/profile

H.安装hadoop
(1) 执行命令 tar -zxvf hadoop-1.1.2.tar
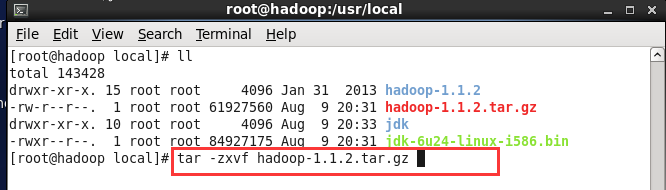
(2) 执行命令 mv hadoop-1.1.2 hadoop重命名
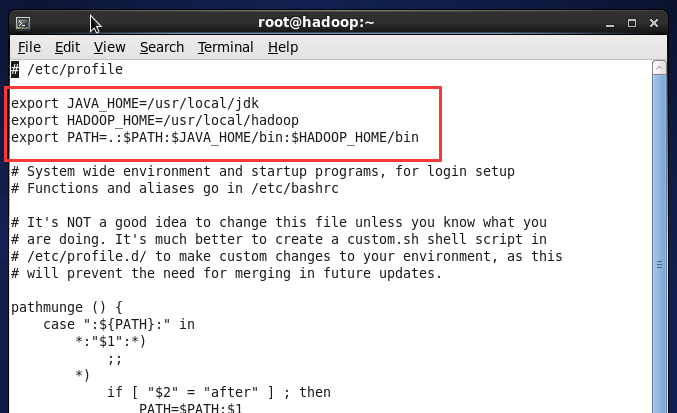
(3) 执行命令 vi /etc/profile 设置环境变量,增加了一行内:
export HADOOP_HOME=/usr/local/hadoop
修改一行内容:
Export PATH=.:$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
保持退出
执行命令 source /etc/profile 让该设置立即生效

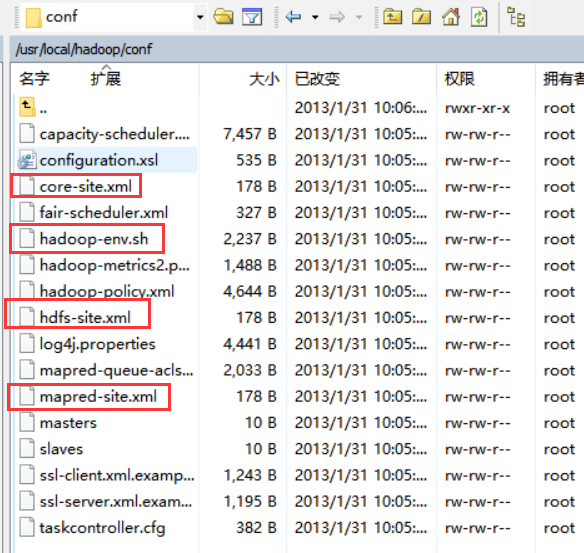
(4) 执行hadoop的配置文件,位于$HADOOP_HOME/conf目录下,修改配置文件hadoop-env.sh,core-site.xml,hdfs-site.xml、mapred-site.xml.
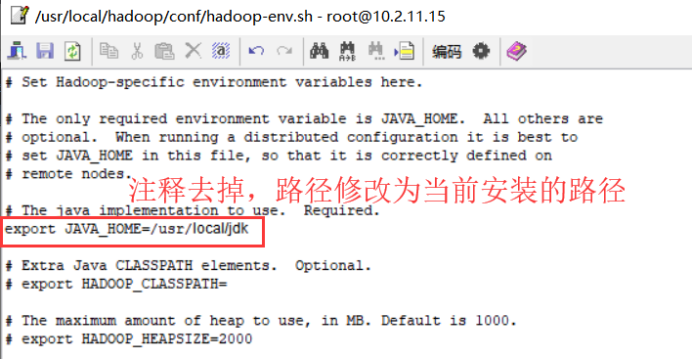
export JAVA_HOME=/usr/local/jdk
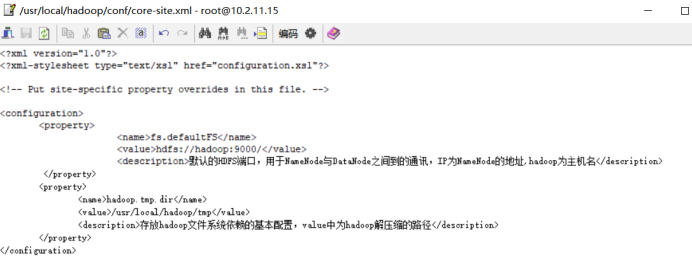
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop:9000/</value> <description>默认的HDFS端口,用于NameNode与DataNode之间到的通讯,IP为NameNode的地址,hadoop为主机名</description> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value> <description>存放hadoop文件系统依赖的基本配置,value中为hadoop解压缩的路径</description> </property> </configuration>
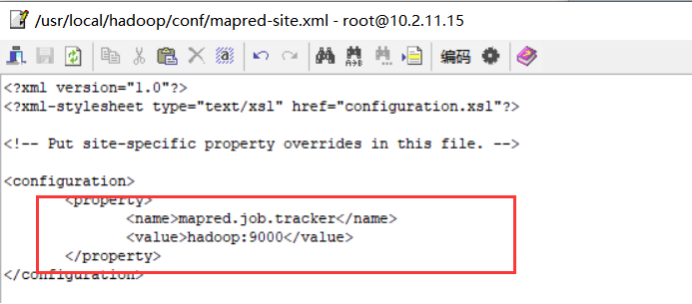
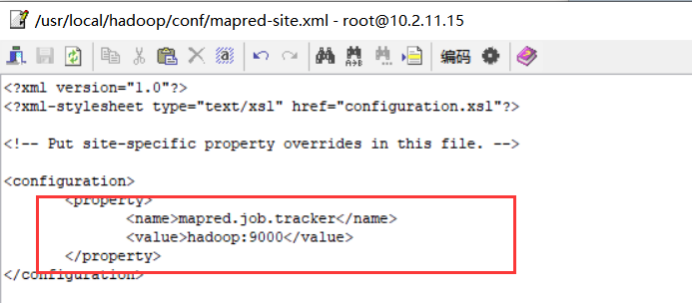
<configuration> <property> <name>mapred.job.tracker</name> <value>hadoop:9000</value> </property> </configuration>
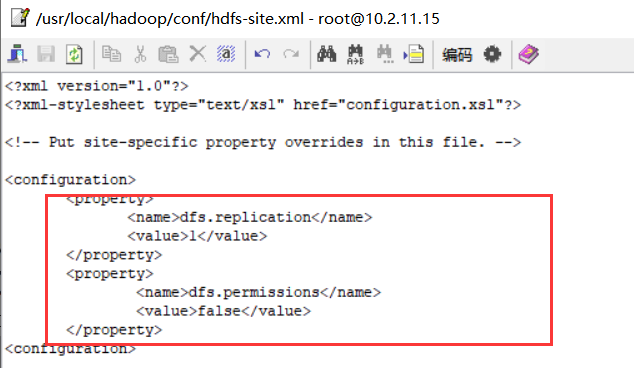
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> <configuration>
(5) 执行命令 hadoop namenode -format 对hadoop进行格式化
(6) 执行命令 start-all.sh 启动
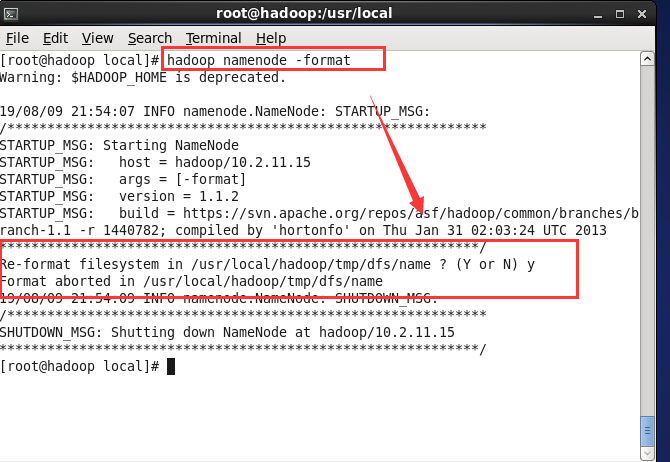
验证:
(1) 执行命令jps,发现5个java进程,分别是NameNode , DataNode , SecondaryNameNode, JobTracker, TaskTracker。
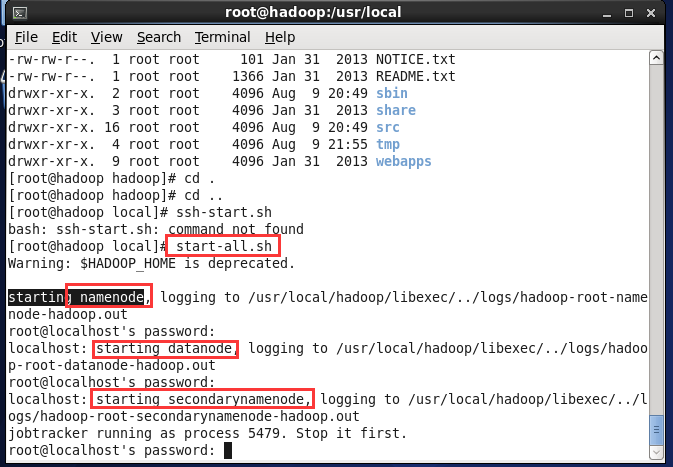
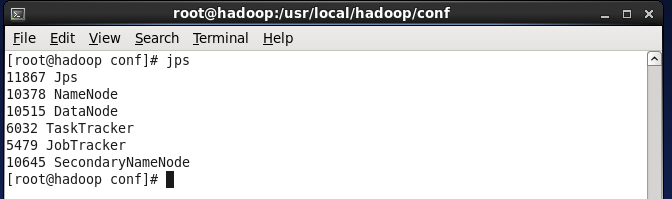
(2) 通过浏览器执行
NameNode:http://hadoop:50030
jobtracker:http://hadoop:50070
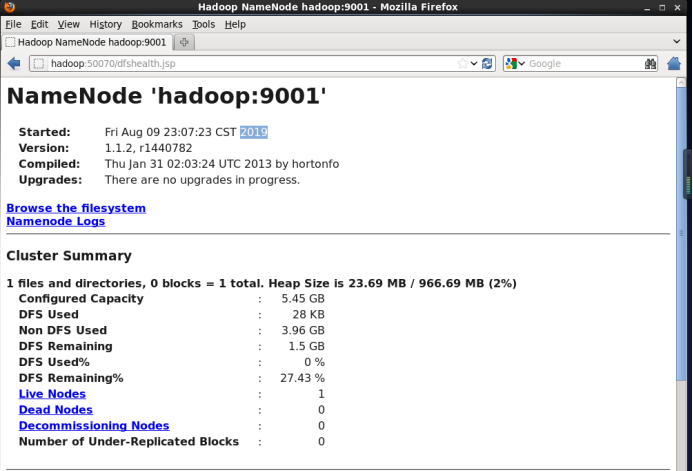
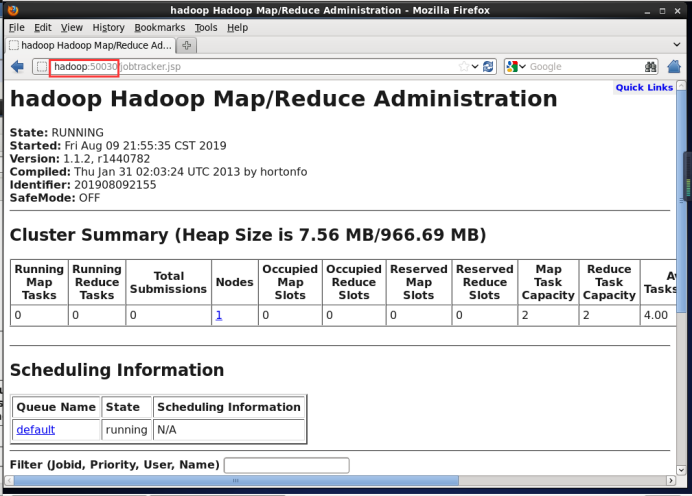
PS:9000和9001 不知道为什么,配置文件的时候这么修改,就能正常配置hadoop
疑问
1、为什么要配置静态IP?
在实际应用中,默认我们使用的是DHCP(动态主机分配协议)来分配地址的,那么ip地址有可能是会变动的。
而我们用Linux来搭建集群学习Hadoop的话,是希望IP固定不变的, 那么这个时候就需要我们配置静态IP。
2、配置ip,可以参考如下博文
https://baijiahao.baidu.com/s?id=1618628054855105015&wfr=spider&for=pc
3.修改root密码,可以参考如下博文
https://www.cnblogs.com/wenrulaogou/p/9409251.html
执行命令:passwd root 修改完成后ctrl+d 进行重启
4.网络采用桥接方式(桥接的网络选择对应实际网络)
