1.1 什么是机器学习
1.1.1 定义
机器学习是从数据中自动分析获得模型,并利用模型对未知数据进行预测。
1.1.2 解释

- 我们人从大量的日常经验中归纳规律,当面临新的问题的时候,就可以利用以往总结的规律去分析现实状况,采取最佳策略。
- 从数据(大量的猫和狗的图片)中自动分析获得模型(辨别猫和狗的规律),从而使机器拥有识别猫和狗的能力。
- 从数据(房屋的各种信息)中自动分析获得模型(判断房屋价格的规律),从而使机器拥有预测房屋价格的能力。
从历史数据当中获得规律?这些历史数据是怎么的格式?
1.1.3 数据集构成
- 结构:特征值+目标值
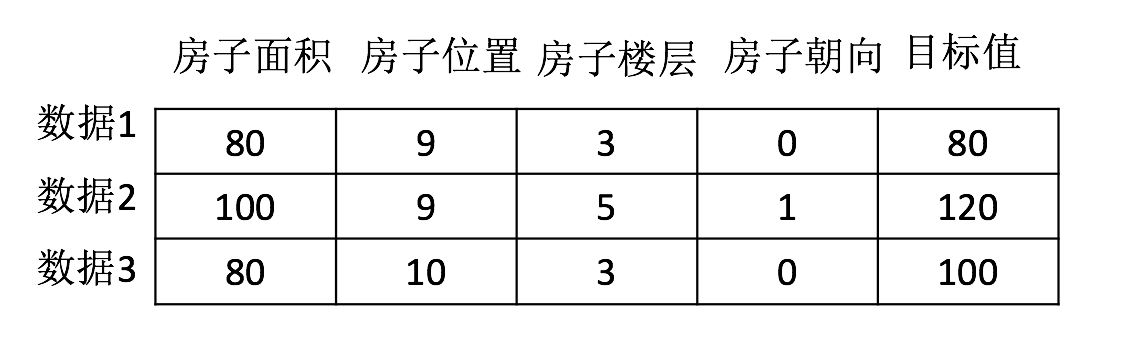
注:
- 对于每一行数据我们可以称之为样本。
- 有些数据集可以没有目标值:
1.2 机器学习算法分类
- 监督学习(supervised learning)(预测)
- 定义:输入数据是由输入特征值和目标值所组成。函数的输出可以是一个连续的值(称为回归),或是输出是有限个离散值(称作分类)。
- 分类 k-近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归、神经网络
- 回归 线性回归、岭回归
- 无监督学习(unsupervised learning)
- 定义:输入数据是由输入特征值所组成。
- 聚类 k-means
1.3 机器学习开发流程

1.4 学习框架和资料介绍
需明确几点问题:
(1)算法是核心,数据与计算是基础
(2)找准定位
大部分复杂模型的算法设计都是算法工程师在做,而我们
- 分析很多的数据
- 分析具体的业务
- 应用常见的算法
- 特征工程、调参数、优化
-
我们应该怎么做?
-
学会分析问题,使用机器学习算法的目的,想要算法完成何种任务
- 掌握算法基本思想,学会对问题用相应的算法解决
- 学会利用库或者框架解决问题
当前重要的是掌握一些机器学习算法等技巧,从某个业务领域切入解决问题。
1.4.1 机器学习库与框架

1.4.2 书籍资料

1.4.3 提深内功(但不是必须)
