Hadoop的核心组件之er: mapreduce
目前的计算框架
mapreduce
spark
storm
flink(阿里)
mapreduce的核心理念:
移动计算, 而不是移动数据(reducetask中仍然有移动数据的情况)
分而治之
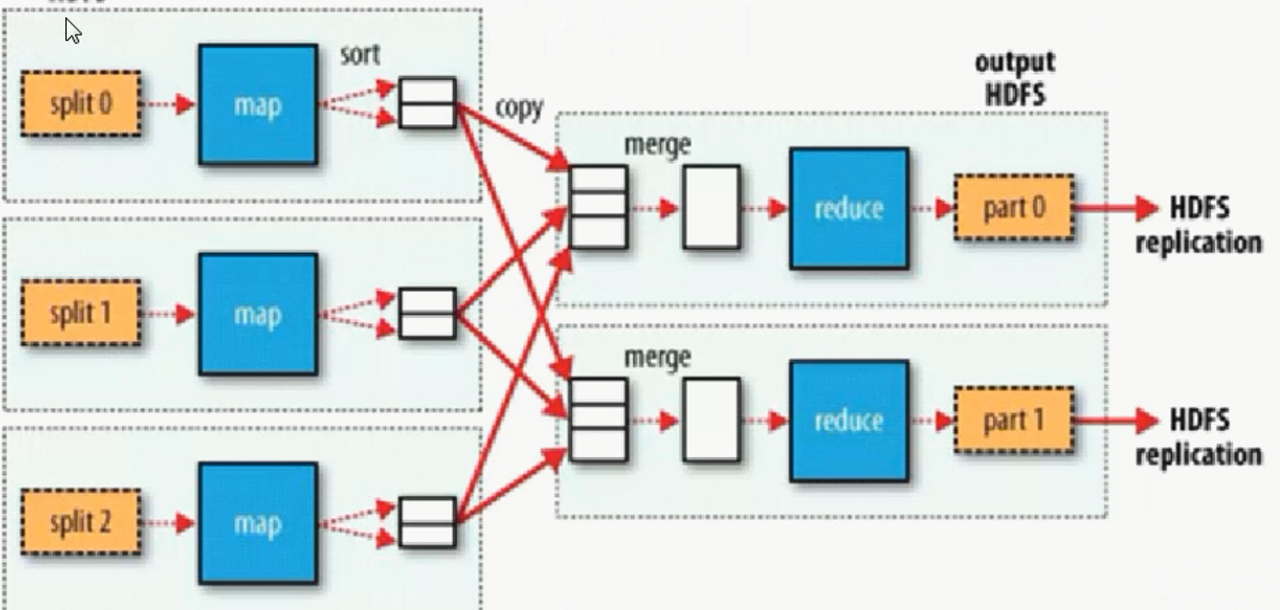
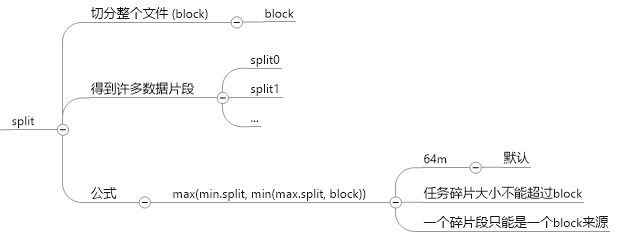
split: 切分hadoop上传的block
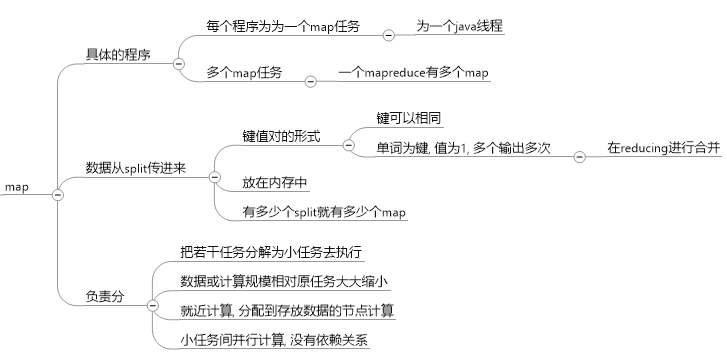
map: 对split后的结果进行分组
shaffer: 对map后的键值对进行排序, 分组, 合并, (根据键)x
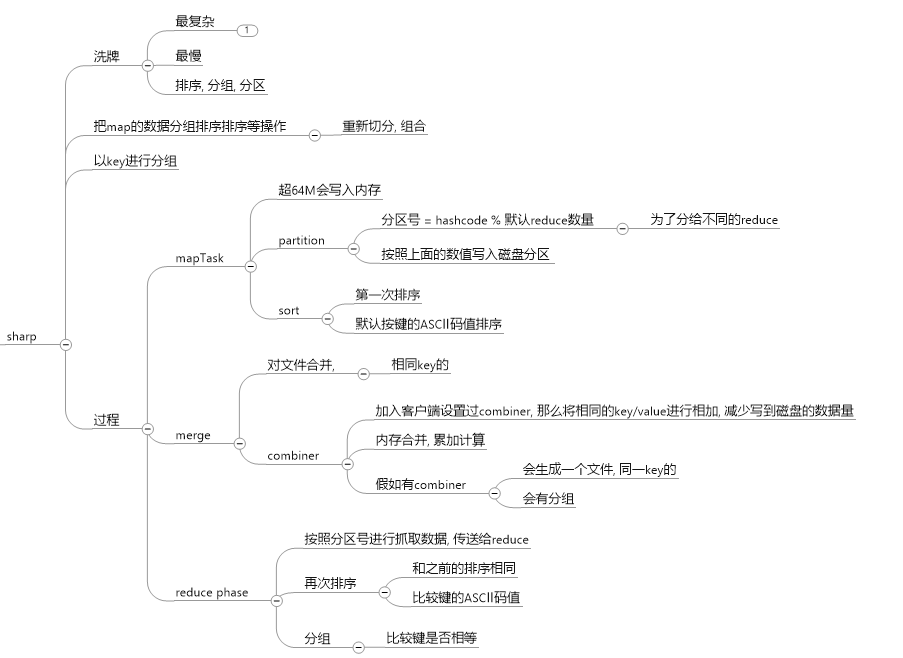

shuffle过程详解:
3、 Shuffle a) 分区(partition,HashPartition:根据key的hashcode值 和 Reduce的数量 模运算),可以自定义分区,运算速度要快。一定要解决数据倾斜和reduce的负载均衡。 b) 排序:默认按照字典排序。WriterCompartor(比较) c) 合并:减少当前mapper输出数据,根据key相同(比较),把 value 进行合并。 d) 分组(key相同(比较),value组成一个集合)(merge)

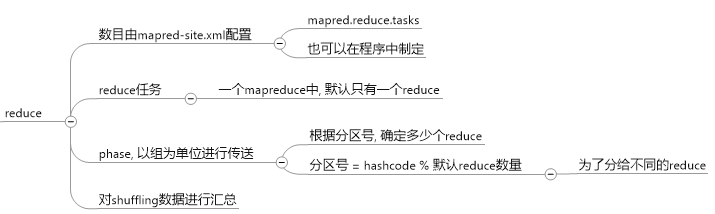
reduce: 对结果进行计算, 输出
执行过程并不是非常严格, 就是切分后可能不会等切分完成, 就开始map的过程了
yarn安装
hadoop2.x以后, 计算框架放在在yarn上
1, yarn-site.xml
<property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yarncluster</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>192.168.208.106</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>192.168.208.107</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>192.168.208.106:2181,192.168.208.107:2181,192.168.208.108:2181</value> </property>
2, mapred-stie.xml, 把mapreduce的环境放在yarn中
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
3, yarn-site.xml, 制定mapreduce运行在哪个框架上
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
NodeManager 和 Datanode在一块, 不需要配置, 自动分辨并启动
4, 启动, 在NN上启动
start-yarn.sh
5, 手动启动备用ResourceManger
yarn-daemon.sh start resourcemanager
6, 访问
wenbronk.hdfs.com:8088/cluster
打开standby, 会立马重定向到active
全部启动执行
start-all.sh