1、AVL
1.基本概念
AVL是平衡二叉查找树,它或者是一颗空树,或者是具有下列性质的二叉树:它的左子树和右子树都是平衡二叉树,且左子树和右子树的深度之差的绝对值不超过1。
若将二叉树结点上的平衡因子BF(Balance Factor)定义为该结点的左子树的深度减去它的右子树的深度,则平衡二叉树上所有结点的平衡因子只能是-1,0,1。
2.插入删除操作
平衡二叉查找树,在添加或者删除的结点的过程中,如果失去平衡,则需要进行平衡调整。调整的过程中,要保持根大于左,小于右的特性。
3.应用场景
最早的平衡二叉树之一。应用相对其他数据结构比较少。windows对进程地址空间的管理用到了AVL树。
2、B-
1.基本概念
B-树是一种平衡的多路查找树。B-树中所有结点孩子结点个数的最大值称为B-树的阶,通常用m表示,从查找效率考虑,要求m>=3。
一颗m阶的B-树,或者为空树,或为满足下面特性的m叉树:
(1)树中每个结点至多有m课子树。
(2)若根结点不是叶子结点,则至少有两颗子树。
(3)除根之外的所有非叶子结点至少有m/2(向上取整)颗子树。
(4)所有的非叶子结点内关键字互不相等,且从小到大排列。
(5)所有叶子结点都出现在同一层次上,并且不带信息(可以用空指针表示),可以看做查找失败到达的位置。
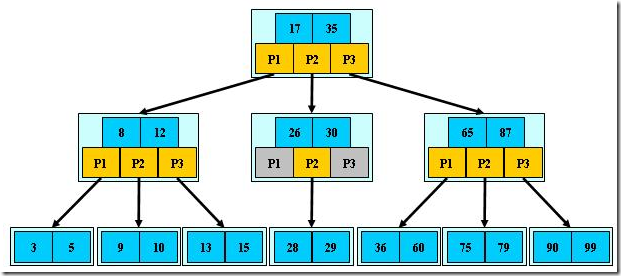
如图,m为3,3阶B-树
2.具体性质
(1)B-树中,具有n个关键字的结点含有n+1个分支。
(2)m阶B-树中,每个结点(除根结点以外)中,关键字的个数是{m/2(向上取整)-1}<= n <= m-1。根结点的关键字个数是1<= n <=m-1。
(3)在B-树中,下层结点的关键字取值总是落在 由上层关键字所划分的区间内。
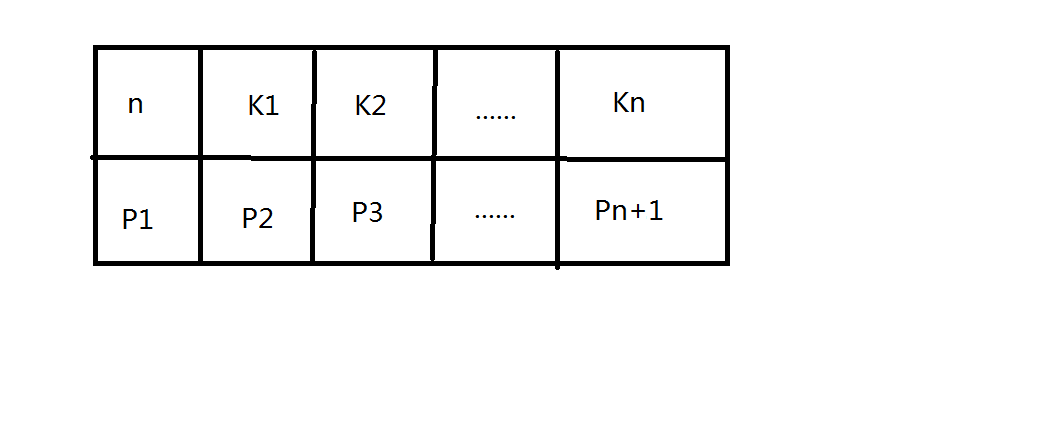
下图,如每个结点的结构,n为关键字的个数,P该节点的孩子结点,P1的取值范围 是小于K1,P2的取值范围 是大于K1 小于K2 依次类推
3.应用场景
MongoDB使用B-树,可以从它的设计角度来考虑,它并不是传统的关系性数据库,而是以Json格式作为存储的nosql,目的就是高性能,高可用,易扩展。它摆脱了关系模型,是聚合型数据库,而 B-树恰好 key 和 data 域聚合在一起。所以MongoDB使用B-树,所有节点都有Data域,只要找到指定索引就可以进行访问,无疑单次查询平均快于Mysql(但侧面来看Mysql至少平均查询耗时差不多)。
尽可能少的磁盘 IO 是提高性能的有效手段。
4.插入删除操作
对于B-树的插入操作,B-的插入总是发生在叶子结点上,为了保持B-树的特性,有结点拆分(取中间关键字,独立成根结点或并入根结点)。
对于B-树的删除操作,为了保持B-树的特性和删除的操作应发生在最下层的叶子结点上,有与叶子结点交换关键字,有向兄弟结点借关键字,有结点合并的操作。
可以参考https://blog.csdn.net/qq_23217629/article/details/52510485
3、B+
1.基本概念
B+树是B-树的一种变形,与B-树对比起来看。
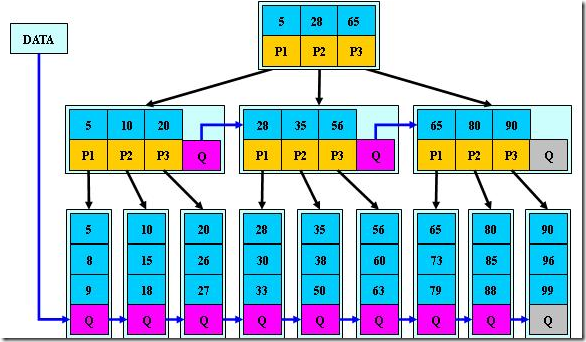
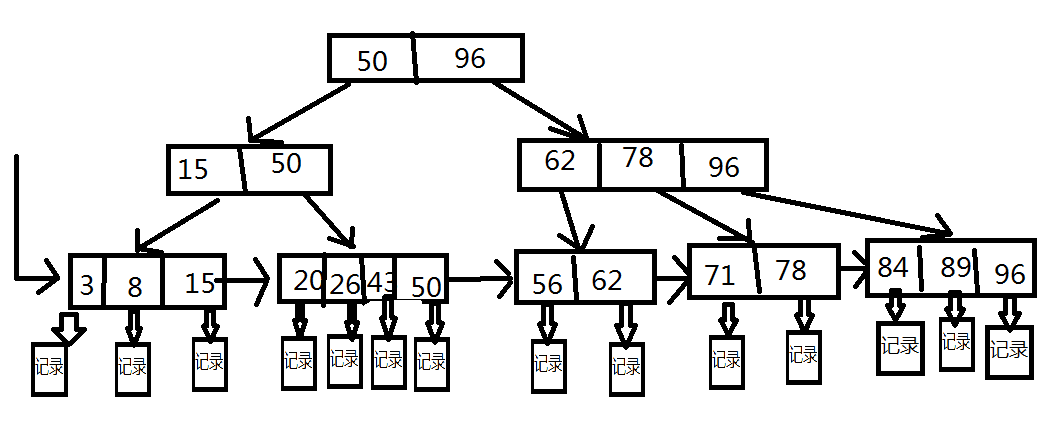
在不同的教材中,B+的构造有不同的样子,大致分了两类,主要区别是在结点上关键字的取值范围。我更偏向后面这种。
一颗m阶的B+树和m阶的B-树的差异在于:
(1)有n颗子树的结点中含有n个关键字。
(2)所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小到大排列。
(3)所有非叶子结点可以看成是索引部分,结点中仅含有其子树中的最大或者最小关键字。
2.具体性质
(1)在B+树中,具有n个关键字的结点含有n个分支
(2)在B+树中,每个结点(除根结点外)中的关键字个数n的取值范围在m/2(向上取整) <= n <= m,根结点的关键字个数的取值范围是1 <= n <=m。
(3)在B+树中,有一个指针指向关键字最小的叶子结点,所有叶子结点链接成一个线性链表。
3.应用场景
B+ 树通常用于数据库和操作系统的文件系统中。NTFS, ReiserFS, NSS, XFS, JFS, ReFS 和BFS等文件系统都在使用B+树作为元数据索引。B+ 树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。B+ 树元素自底向上插入。
B-树和B+树最重要的一个区别就是B+树只有叶节点存放数据,其余节点用来索引,而B-树是每个索引节点都会有Data域。这就决定了B+树更适合用来存储外部数据,也就是所谓的磁盘数据。
从Mysql(Inoodb)的角度来看,B+树是用来充当索引的,一般来说索引非常大,尤其是关系性数据库这种数据量大的索引能达到亿级别,所以为了减少内存的占用,索引也会被存储在磁盘上。Mysql是通过磁盘IO次数,来衡量效率。当查询数据的时候,最好的情况就是很快找到目标索引,然后读取数据。而B+树除了叶子节点其它节点并不存储数据,节点小,磁盘IO次数就少。另外,B+树所有的Data域在叶子节点,一般来说都会进行一个优化,就是将所有的叶子节点用指针串起来。这样遍历叶子节点就能获得全部数据,这样就能进行区间访问啦。
4、红黑树
1.基本概念
红黑树是一种自平衡的二叉排序树,除了具有二叉排序树的性质,以下性质:
1.结点是黑色或者红色
2.根结点是黑色
3.每个叶子结点都是黑色的空节点(NIL结点)
4.每个红色结点的子节点都是黑色的(从每个叶子结点到根结点的路径上不能有连续两个红色的结点)
5.从任意结点到每个叶子结点的所有路径上都包含相同数量的黑色结点(黑高)。
这五条性质很重要

2.操作
红黑树的操作主要有两个反色和旋转。旋转分为左旋转和右旋转。
红黑树的插入和删除会带来一系列的调整操作,比较复杂。
可以参考 http://www.sohu.com/a/201923614_466939
3.应用场景
红黑树的应用也很多,在JDK中的集合类TreeMap和TreeSet底层都是红黑树实现的,在Java8中,连HashMap也用到红黑树。
主要是了解一下B-,B+以及红黑树是个什么样子,方便以后看mysql,mongdb的原理和hashmap源码,水平有限,没有深入讲解。