过拟合
模型的泛化能力:训练集、测试集。训练集上学到的模型在测试集上的性能。
本节课研究的是:源域和测试域来自相同的分布,独立同分布。
迁移学习transfer Learnig:源域和测试域来自不同的分布,就是迁移学习,很复杂。
欠拟合和过拟合都不行。
不过现实中条件有限,无法得知数据的真实分布,所以通常使用大容量模型+正则化来得到不错的结果。
关于统计学习statistical learning:随机变量(x,y)的联合概率分布Pxy(X=x,Y=y);条件概率Pxy(Y=y|X=x0)、Pxy(Y=y|X=x1)。
统计学习三要素
方法=模型+策略+算法:统计学习方法都是由模型、策略和算法构成,这称为统计学习三要素。
模型期望

以上表达式描述的就是样本服从真实分布情况下,样本(随机变量)X在以 Θ Theta Θ为参数的模型中输出的期望(平均的概率输出),极限情况下即为1。
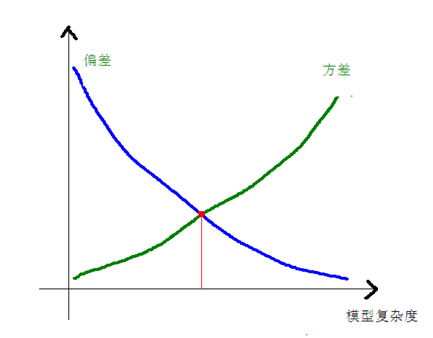
偏差—方差权衡
误差分解:噪声、偏差和方差。
理想模型、随机误差、学习误差。
学习误,模型期望,偏差+方差
偏差:理想模型和现实模型之间的差距。取一个期望,离靶心很近。关注数据和靶心的离散程度。
方差:与过拟合密切相关。关注数据本身的离散程度。
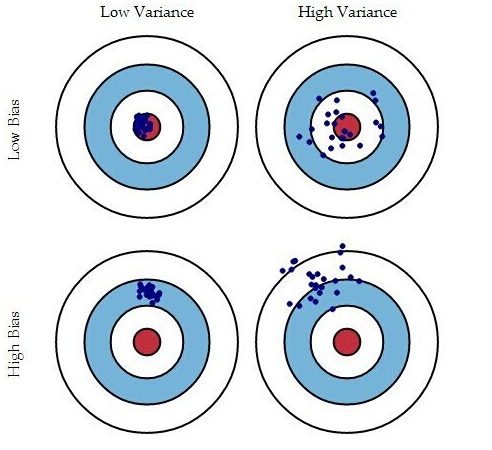
偏差-方差与模型复杂度:
欠拟合解决办法:更换描述能力更强的模型。
过拟合解决办法:扩增训练集、正则化、减少模型复杂度。
训练集大小的影响等等。
模型选择
简单结论:不存在通用的学习算法。每个学习算法都有其特定的任务,为了学习成功,要采用一些关于任务的先验知识。
交叉验证(cross validation)超参数里面找到最优解,找到最好的参数。
数据集划分:训练集、验证集和测试集。
注意:现在一般可能在测试集上面进行调参,但是因为看过测试集了,数据偷看,所以测试集间接参与了模型的训练,没有把测试集的标签来测试模型,但是用测试集的标签来训练模型。为什么选择这个超参数?可能使用了测试集,选好测试集,然后进行训练和测试,这是一个问题。
训练集和测试集都是公开的,那么性能需要存疑。这种做法本身是不规范的,虽然大家是这么做的,可能性能不准。
机器学习公开的比赛,会公布训练集,然后自己提高模型到server,这个服务器是网络公开的。
正则化
基于最小均方误差的最小二乘法,加入正则项的改良最小二乘法(岭回归)
正则化通过惩罚模型来实现简单的模型。
正则化系数的影响,学习的是参数W,训练的是超参数(正则化系数)。
1、超参数?
【超参数的值不是学习出来的】:大多数机器学习算法都有超参数,可以设置来控制算法行为。超参数的值不是通过学习算法本身学习出来的。
【超参数如果学习太难优化】:有时一个选项被设为学习算法不用学习的超参数,是因为它太难优化了。更多的情况是该选项必须是超参数,是因为它不适合在训练集上学习。
【超参数是我们自己设定的】:这适用于控制模型容量的所有超参数。如果在训练集上学习超参数,这些超参数总是趋向于最大可能的模型容量,导致过拟合。
参考链接:https://blog.csdn.net/qq_16137569/article/details/81504853
https://www.cnblogs.com/noluye/p/11241843.html
https://blog.csdn.net/qq_30335773/article/details/107535793
https://www.cnblogs.com/Renyi-Fan/p/13792258.html