数据库索引:是一个提高数据检索和操作,以额外的写和存储空间为代价维护的数据结构.
数据库逻辑存储和磁盘的关系.
A. 磁盘空间被划分为许多大小相同块(Block)或者页(Page).
B. 一个表的这些数据块以链表的方式串联在一起.
C. 数据是以行(Row)为单位一行一行的存放在磁盘上的块中,如图所示.
D.在访问数据时,一次从磁盘中读出或者写入至少一个完整的Page.

当数据库检索数据的时候需要一行一行的读取数据直到查找到匹配的数据.
对于数据的检索过程极大的影响了对数据操作效率
开源节流优化的办法
1.减少数据存储占用的空间
2.减少对无效数据的访问
Key的产生
我们对于数据访问的时候是基于某一列或是几列访问数据的,并不需要匹配整个行
图中ID列就能确定整行数据,所以能确认一行数据的列叫做KEY
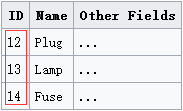
(图片来自于WikiPedia)
Dense index
把key拿出来单独存放并且每个key添加指针指向原来的数据块
在检索数据的时候不再需要全表扫描,只需要进行全索引扫描(依次读取所有的索引数据块当找到匹配的键值的时候根据该行的指针读取该行的数据块进行操作)

图片来自于(MySQL代码研究)
Dense index进化
这样的查询还是不能满足生产中的需求通过对key的排序来减少磁盘IO扫描
折半查找法
这种搜索算法每一次比较都使搜索范围缩小一半,可在最坏的情况下用0(logn)完成搜索任务;
优点:是比较次数少,查找速度快,平均性能好;
缺点: 是要求待查表有序表,且插入删除困难,因此,折半查找方法适用于不经常变动而查找频繁的有序表;
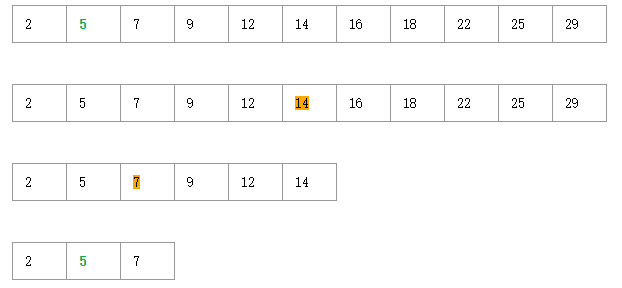
在这个数组里面我们要找到5,优先找到数组的中间位置,第6位是数组的中间位置,14比5大折半,中间位置是7比5大折半,找到5
折半块查找
A. 对Dense Index排序
B. 需要一个数组按顺序存储索引块地址。以块为单位,不存储所有的行的地址。
C. 这个索引块地址数组,也要存储到磁盘上。将其单独存放在一个块链中,如下图所示。
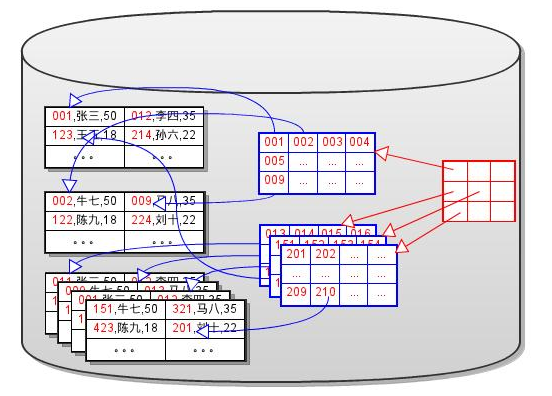
图片来自于(MySQL代码研究)
Sparse Index
将每一个块,每一行的数据单独拿出来这样就可以在数组上进行折半查找了
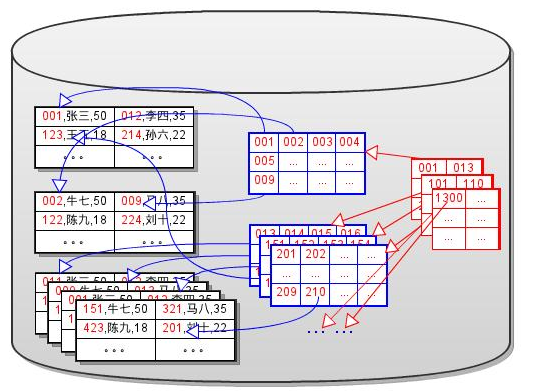
图片来自于(MySQL代码研究)
多层Sparse Index
因为Sparse Index本身是有序的,所以可以为Sparse Index再建sparse Index
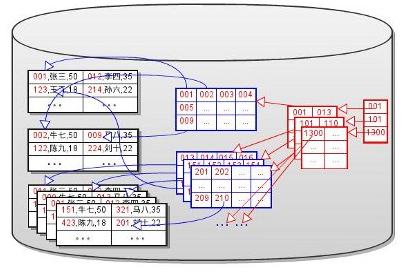
图片来自于(MySQL代码研究)
A.这个最上层的Sparse Index称作整个索引树的根(root).
B.每次进行定位操作时,都从根开始查找.
C.每层索引只需要读出一个块.
D.最底层的Dense Index或数据称作叶子(leaf).
E.每次查找都必须要搜索到叶子节点,才能定位到数据.
F.索引的层数称作索引树的高度(height).
G.索引的IO性能和索引树的高度密切相关。索引树越高,磁盘IO越多。
Dense Index和Sparse Index的区别
A. Dense Index包含所有数据的键值,但是Sparse Index仅包含部分键值。Sparse Index占用更少的磁盘空间。
B. Dense Index指向的数据可以是无序的,但是Sparse Index的数据必须是有序的。
C. Sparse Index 可以用来做索引的索引,但是Dense Index不可以。
D. 在数据是有序的时候,Sparse Index更有效。因此Dense Index仅用于无序的数据。
E. 索引扫描(Index Scan)实际上是对Dense Index层进行遍历。
簇索引(Clustered Index)和辅助索引(Secondary Index)
如果数据本身是基于某个Key来排序的,那么可以直接在数据上建立sparse索引,
而不需要建立一个dense索引层(可以认为数据就是dense索引层)。 如下图所示:
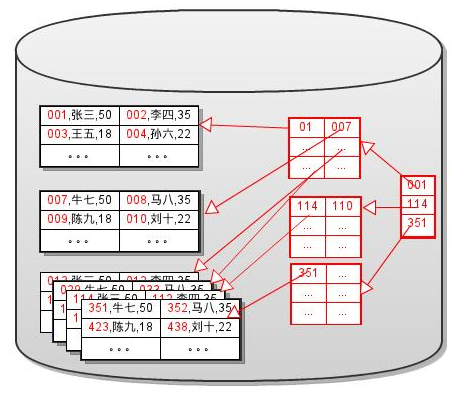
图片来自于(MySQL代码研究)
这个索引就是我们常说的“Clustered Index”,而用来排序数据的键叫做主键Primary Key.
A. 一个表只能有一个Clustered Index,因为数据只能根据一个键排序.
B. 用其他的键来建立索引树时,必须要先建立一个dense索引层,在dense索引层上对此键的值,进行排序。这样的索引树称作Secondary Index.
C. 一个表上可以有多个Secondary Index.
D. 对簇索引进行遍历,实际上就是对数据进行遍历。因此簇索引的遍历效率比辅组索引低。如SELECT count(*) 操作,使用辅组索引遍历的效率更高。
范围搜索(Range Search)
由于键值是有序的,因此可以进行范围查找。只需要将数据块、Dense Index块分别以双向链表的方式进行连接, 就可以实现高效的范围查找。如下图所示:
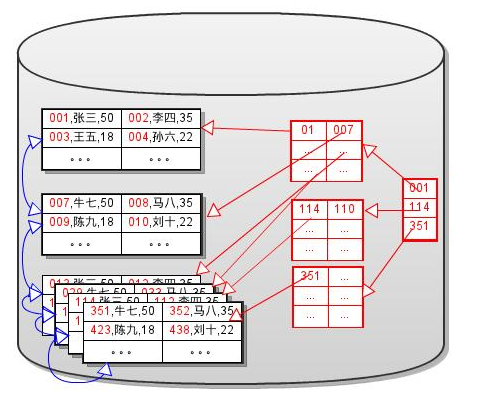
图片来自于(MySQL代码研究)
范围查找的过程:
A. 选择一个合适的边界值,定位该值数据所在的块
B. 然后选择合适的方向,在数据块(或Dense Index块)链中进行遍历。
C. 直到数据不满足另一个边界值,结束范围查找