1.自动类型转换
当2个不同类型的数据进行运算的时候,默认向更高精度转换
数据类型精度从低到高:bool < int < float <complex
1,1强制类型转换
# Number 部分 int : 整型 浮点型 布尔类型 纯数字字符串 float : 整型 浮点型 布尔类型 纯数字字符串 complex: 整型 浮点型 布尔类型 纯数字字符串(复数) bool : (容器类数据类型 / Number类型数据 都可以) # 容器类型部分 str: (容器类型数据 / Number数据类型都可以) list: 字符串 列表 元组 集合 字典 tuple: 字符串 列表 元组 集合 字典 set: 字符串 列表 元组 集合 字典 (注意相同的值,只会保留键) dict: 使用二级列表,二级元组,二级集合(里面的容器数据只能是元组)
1.2 字典和集合的注意点
1.2.1 字典的键和集合中的值都是唯一值,不可重复:
为了保证数据的唯一性,
用哈希算法加密字典的键得到一个字符串。
用哈希算法加密集合的值得到一个字符串。
如果重复,他们都是后面的替换前面的,自动去重。
1.2.2版本导致的区别:
3.6版本之前都是 字典和集合都是无序的
3.6版本之后,把字典的字面顺序记录下来,当从内存拿数据的时候根据字面顺序重新排序,所以看起来像有序,但本质上无序
1.2.3可哈希的数据:
可哈希数据(不可变的数据类型):Number(int float bool complex),str,tuple
不可哈希数据(可变的数据类型):list set dict
2.数据在内存中的缓存机制
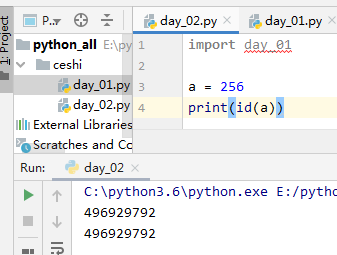
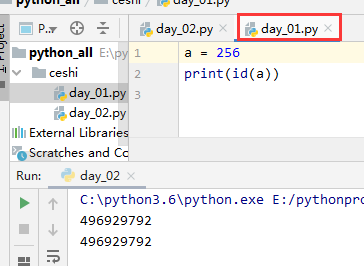
2.1在同一文件(模块)里,变量的存储缓存机制(仅对3.6版本)
#--->Number 部分 1.对于整型而言,-5~正无穷范围内的相同值,id一致 2.对于浮点数而言,非负数范围内的相同值,id一致 3.布尔值而言,值相同情况下,id一致 4.复数在 实数+虚数 这样的结构中永不相同,除非只有虚数的时候,id一致 #--->容器类型部分 1.字符串 和 空元组 相同的情况下,地址相同 2.列表,元组,字典,集合无论什么情况 ,id都不一致(只有空元组除外)
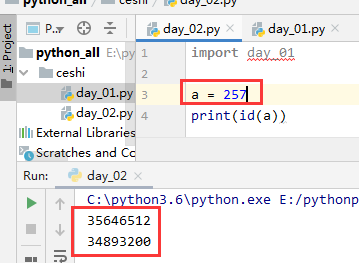
2.2不同文件(模块)里,部分数据驻留小数据池中(仅对3.6版本)
小数据池,只针对:int ,str,bool,空元组(),None关键字,这些数据类型有效 #(1)对于int而言 python在内存中创建了-5~256范围的整数,提前驻留在了内存的一块区域 如果是不同文件(模块)里的两个变量,声明同一个值,在-5~256这个范围里, 那么id一致,让两个变量的值同时指向一个值的地址,节省空间

#(2)对于str来说: 1.字符串的长度为0或1,默认驻留小数据池 2.字符串的长度>1,且只含有大小写字母,数字,下划线时,默认驻留小数据池

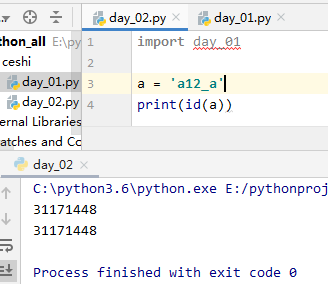

3.用*号得到的字符串,分两种情况 1)乘数等于1时:无论什么字符串*1,都默认驻留小数据池 2)乘数大于1时:乘数大于1时,仅包含数字,字母,下划线时会被缓存,但字符串长度不能大于20(乘以乘数后得到的字符串)
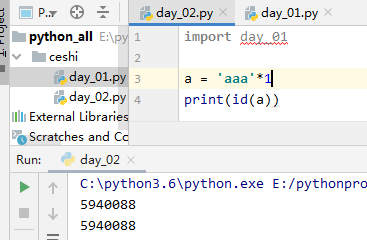
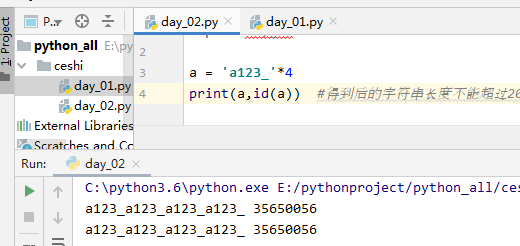
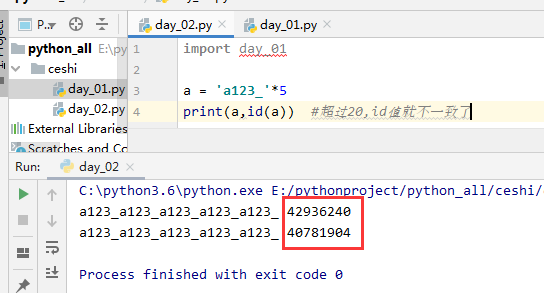
#(3)指定驻留
#从sys模块引入intern函数,让a,b两个变量指向同一个值
from sys import intern
a = intern('大哥&*^^1234'*10)
b = intern('大哥&*^^1234'*10)
print(a is b)
#可以指定任意字符串加入到小数据池中,无论声明多少个变量,只要值相同,都指向同一个数据池

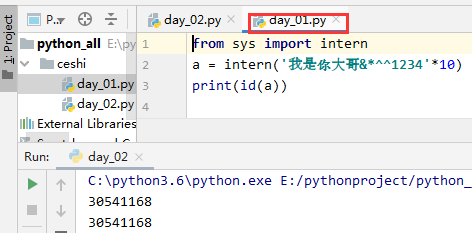
2.3缓存机制的意思
无论是变量缓存机制还是小数据池的驻留机制,都是为了节省内存空间,提升代码效率
总结:今天主要讲了6个部分
1.set_dict的作用
2.变量的缓存机制
3.Number强制类型转换
4.Number自动类型转换
5.容器类型的强制转换
6.字典的强转
第一部分:.set集合的作用(无序,自动去重),集合的元素不可获取,同时也不能修改,定义一个空的集合,需要用set()。字典的作用(键值对的存储形式,表面上有序,实际上无序),获取字典的中的值通过字典的key获取:变量名[‘key值’],修改字典的值:变量名['key值'] = 新v值。定义一个空的字典,dictvar = {}。字典的键和集合 的值要求不可变的数据类型即int,float,bool,complex,str,tuple。
第二部分:针对3.6版本Number类型的缓存机制,如int整型数值在-5~正无穷范围内相同的值,id都是相同的。浮点型,数值为非负数的相同值,id都是相同的。布尔值,值相同的情况下,id都是相同的。复数,在实数+虚数 这样的结构中永远不相同(除非只有虚数的情况下,id是相同的)。然后就是容器类型部分的缓存机制,字符串和空元组相同值的情况下,id都是相同的。列表,元组,字典,集合在任何情况下,id都是不相同的(除了空元组)
第三部分:Number类型的强转,int强制转换成整型的有(float,bool,全数字字符串,),float强制转换成浮点型的有(int,bool,全数字字符串,),complex强制转换成复数的有(int,float,bool,全数字字符串),bool强制转换成布尔类型的有(任何类型都可以),以及布尔类型为假的十种情况(0,0.0,'',False,0j,().[],{},set(),None)
第四部分:Number类型自动转换,默认从低精度往高精度转,依次从最低顺序是bool,int,float,complex
第五部分:容器类型的强制转换(str,tuple,list,dict,set),str字符串,容器类型数据及Number数据都可以转换,只要在原有数据类型上套上引号即可。顺带讲了如何原型化输出字符串,需要用到repr函数,用法repr(得到的结果)。list列表,如果是字符串,会把每一个字符串中的字符单独作为一个元素添加到列表中,如果是字典,只保留键,然后添加到列表,如果是其他容器,改成列表括号[]就可以。tuple元组,如果是字符串,会把每一个字符串中的字符单独作为一个元素添加到列表中,如果是字典,只保留键,然后添加到列表,如果是其他容器,改成元组括号()就可以。set集合,如果是字符串,会把每一个字符串中的字符单独作为一个元素添加到集合中,如有重复的字符,会自动去重,如果是字典,只保留键,添加到集合中,如果是其他数据类型,改成集合括号{}即可
第六部分:介绍了二级容器,多级容器,包括二级列表,二级元组,二级集合,二级字典,其中二级集合中,集合嵌套集合的时候,二级集合需要用元组()来表示。多级容器时,可通过索引下标获取对应的值。字典的强转,强制转为字典时,必须是等长的二级容器,且元素个数为2,超过即报错。可以转换字典的二级容器数据,外层可以是列表或元组或集合,里面的容器是元组或列表(推荐使用)。外层是列表或元组,里面是集合,语法上允许,有局限性,因为二级容器集合是无序的,会导致kv的值随机互换(不推荐使用)。外层是列表或元组或集合,里面是字符串,语法上允许,但有局限性,原因是字符串的长度不能超过2位,超过即会报错(不推荐使用)。