本文是arxiv上一篇较短的文章,之所以看是因为其标题中半监督和文本分类吸引了我。不过看完之后觉得所做的工作比较少,但想法其实也挺不错。
大多数的半监督方法都选择将小扰动施加到输入向量或其表示中,这种方式在计算机视觉上比较成功,但对于离散型的文本却不适合。为了将这个方法应用于文本输入,本文将神经网络(M)进行拆分:(M=U circ F)。其中(F)被冻结(freeze),用于特征提取和基于droput添加噪声,(U)则可以是任意的半监督算法。同时,论文还对(F)逐渐解冻(unfreeze),避免预训练模型的灾难性遗忘。
引言
大多数半监督算法依赖于一致性或者平滑约束,强制模型对输入及加了轻微扰动的输入的预测一致。在CV问题中,图片可以表示成稠密连续向量,然而在文本分类任务中,每个单词被表示成one-hot形式,这种方法不合适。即使使用word embedding,文本的潜在表示还是离散的。并且,给每个单词独立加入扰动的话,会导致扰动后的单词没有实际意义。
针对上述问题,本文提出将一个神经网络分解为两部分,即(M = U circ F)。其中(F)作为特征编码器和扰动函数(比如可以使用语言模型),(U)可以是任意的半监督算法。(F)通常是领域无关的,而(U)则是领域特定的。这也是论文题目叫做layer partitionning的原因。
方法
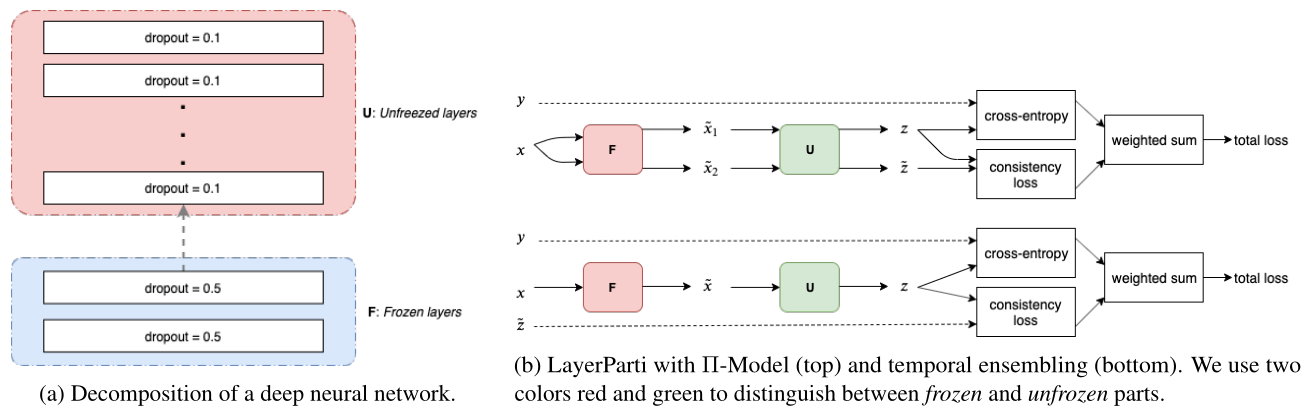
上图左边部分就是整个模型的示意图,论文使用ULMFiT作为(F)特征编码器,将每个输入转化到连续的向量空间,然后再由(U)((prod)模型,Temporal Emsebling等)进行学习。
同时(F)还用于给输入施加噪声。但作者没有使用通用的( ilde{x} leftarrow x + epsilon)这种方式,而是使用dropout作为噪声。作者认为(F)在通用领域预训练,比通用的方式包含更多的文本信息,对到此加入噪声使happy变成sad这种方式可能会完全改变文本性质。
接下来就是如何训练(U)的事情了,论文列举了两个模型,分别是(prod)-Model和temporal ensembling model。它们都是半监督学习算法,示意图如上图右边部分。
训练到一定程度,作者提出逐渐解冻(F)中的网络,这是因为此时(U)已经在({F(x)})上训练饱和,可以让(F)同样也学到一些任务相关的特定特征了。
实验
论文使用Internet Movie Dataset(IMDb)和TREC-6数据集,主要是进行情感分类。