这篇文章出自facebook,主要探索了如何利用类别型特征(categorical features)并且构建一个深度推荐系统。值得注意的是,文章还特别强调了工业实现上如何实现并行,也很良心地给出了基于Pytorch和Caffe2的模型实现。
引言
目前的个性化推荐系统深度模型主要有两种方式:
- 推荐系统角度:这类系统使用内容过滤,即由专家对物品分类,然后根据用户的喜好进行匹配推荐。该领域随后发展为协同过滤方法,或者是其它基于邻居和隐语义(Latent factor)方法。
- 预测分析角度:这类方法依靠统计模型基于给定数据对事件进行分类或者预测发生概率。这类方法使用embedding对类型数据转换为稠密向量
本文提出的推荐方法是上述两种方法的结合,该模型(DLRM)使用embedding处理稀疏特征,并使用MLP处理稠密特征,然后显式考虑这些特征的交互,最后再使用一个MLP预测事件概率。
模型设计与架构
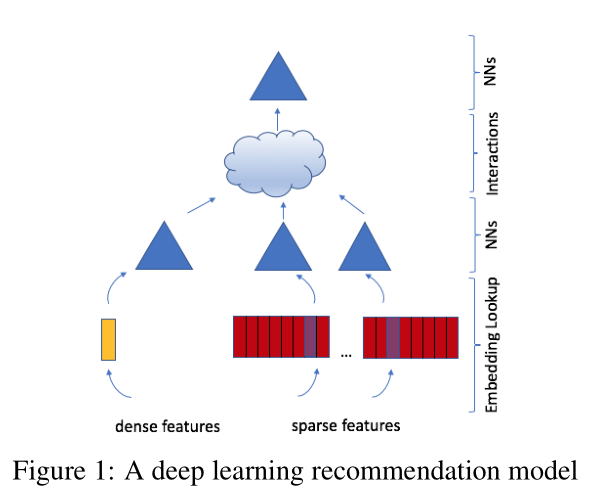
模型整体的架构如图所示,主要组件包括Embeddings,Matrix Factorization,Factorization Machine以及Multilayer Perceptrons。
Embeddings的思路很简单,就是每个稀疏特征都会转换成一个one-hot或者n-hot向量,然后利用这个向量在embedding表中查询:
Multilayer Perceptrons用于更复杂的特征交互和预测,形式如下:
Matrix Factorization主要是用于学习用户和物品的向量表示,其学习目标可以用下式表示:
其中(r_{ij} in mathbb{R}表示第)i(个物品和第)j$个用户的得分, (mathbf{w}_i) 和 (mathbf{v}_j) 分别表示物品和用户的向量
Factorization Machine用于对特征进行交叉,对稀疏数据比较有利:
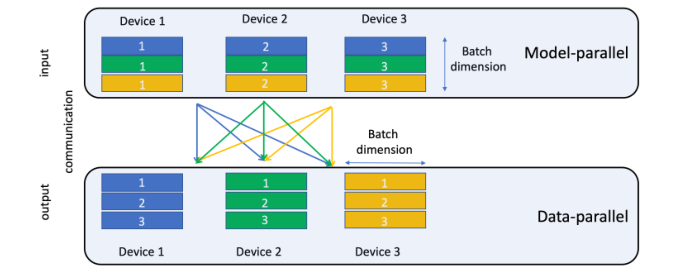
并行
在DLRM中,稀疏特征(类别型特征)都要转换为embedding,这部分产生了大量参数,因此整个模型需要并行处理。本文中,DLRM同时使用模型并行和数据并行。其中,模型并行用于embedding模块,数据并行用于MLP模块。由于现有的PYtorch和Caffe2中都没有这方面实现,因此论文也给出了自己的方案。
数据和实验
论文使用了三种类型的数据,随机数据、合成数据和公开数据集。论文的实验在Big Basin AI platform上进行,使用了8块Nvidia Tesla V100 16GB GPU,对精度也有一些调整。实验的代码已经在GitHub上公开。最终的实验结果如下图所示:
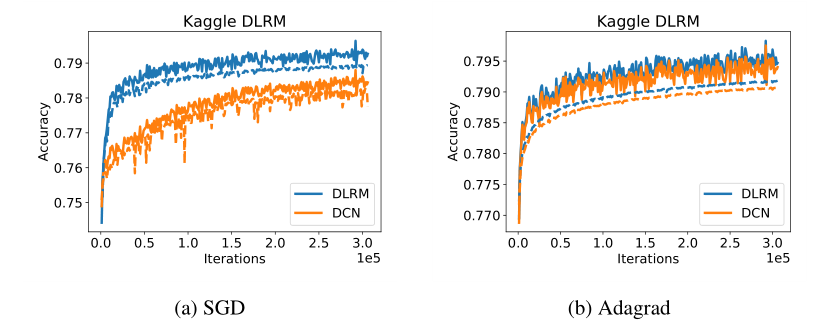
其中数据集是Criteo Ad Kaggle数据集,DCN是指Deep and Cross network。
结论与感想
看到这篇论文是因为paperweekly的推荐,但是通读下来并没有太多惊艳的地方,模型构建方式也比较地传统。但对于工程实现来说应该具有不错的指导价值,尤其是也有实现的代码。