| Master URL | Meaning |
|---|---|
| local | 在本地运行,只有一个工作进程,无并行计算能力。 |
| local[K] | 在本地运行,有K个工作进程,通常设置K为机器的CPU核心数量。 |
| local[*] | 在本地运行,工作进程数量等于机器的CPU核心数量。 |
| spark://HOST:PORT | 以Standalone模式运行,这是Spark自身提供的集群运行模式,默认端口号: 7077。详细文档见:Spark standalone cluster。 |
| mesos://HOST:PORT | 在Mesos集群上运行,Driver进程和Worker进程运行在Mesos集群上,部署模式必须使用固定值:--deploy-mode cluster。详细文档见:MesosClusterDispatcher. |
| yarn-client | 在Yarn集群上运行,Driver进程在本地,Executor进程在Yarn集群上,部署模式必须使用固定值:--deploy-mode client。Yarn集群地址必须在HADOOPCONFDIR or YARNCONFDIR变量里定义。 |
| yarn-cluster | 在Yarn集群上运行,Driver进程在Yarn集群上,Work进程也在Yarn集群上,部署模式必须使用固定值:--deploy-mode cluster。Yarn集群地址必须在HADOOPCONFDIR or YARNCONFDIR变量里定义。 |
用户在提交任务给Spark处理时,以下两个参数共同决定了Spark的运行方式。· –master MASTER_URL :决定了Spark任务提交给哪种集群处理。· –deploy-mode DEPLOY_MODE:决定了Driver的运行方式,可选值为Client或者Cluster。
Standalone 模式运行机制
Standalone集群有四个重要组成部分,分别是:
- Driver:是一个进程,我们编写的Spark应用程序就运行在Driver上,由Driver进程执行;2) Master(RM):是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责;3) Worker(NM):是一个进程,一个Worker运行在集群中的一台服务器上,主要负责两个职责,一个是用自己的内存存储RDD的某个或某些partition;另一个是启动其他进程和线程(Executor),对RDD上的partition进行并行的处理和计算。4) Executor:是一个进程,一个Worker上可以运行多个Executor,Executor通过启动多个线程(task)来执行对RDD的partition进行并行计算,也就是执行我们对RDD定义的例如map、flatMap、reduce等算子操作。
Standalone Client 模式
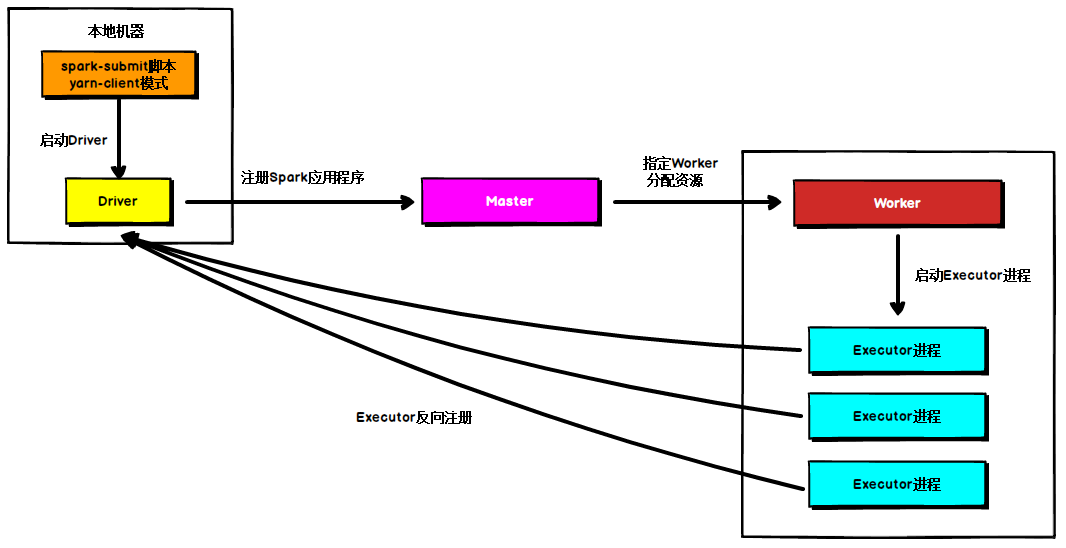
在Standalone Client模式下,Driver在任务提交的本地机器上运行,Driver启动后向Master注册应用程序,Master根据submit脚本的资源需求找到内部资源至少可以启动一个Executor的所有Worker,然后在这些Worker之间分配Executor,Worker上的Executor启动后会向Driver反向注册,所有的Executor注册完成后,Driver开始执行main函数,之后执行到Action算子时,开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
Standalone Cluster模式
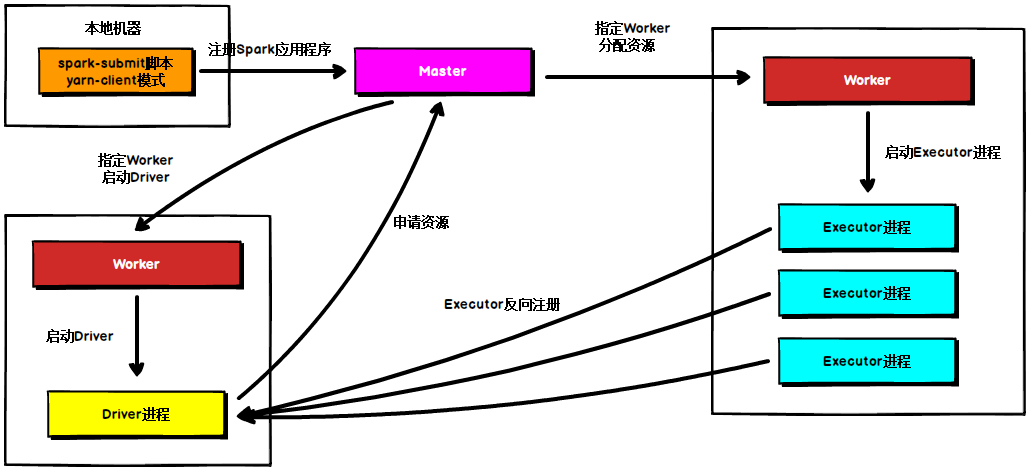
在Standalone Cluster模式下,任务提交后,Master会找到一个Worker启动Driver进程, Driver启动后向Master注册应用程序,Master根据submit脚本的资源需求找到内部资源至少可以启动一个Executor的所有Worker,然后在这些Worker之间分配Executor,Worker上的Executor启动后会向Driver反向注册,所有的Executor注册完成后,Driver开始执行main函数,之后执行到Action算子时,开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。注意Standalone的两种模式下(client/Cluster),Master在接到Driver注册Spark应用程序的请求后,会获取其所管理的剩余资源能够启动一个Executor的所有Worker,然后在这些Worker之间分发Executor,此时的分发只考虑Worker上的资源是否足够使用,直到当前应用程序所需的所有Executor都分配完毕,Executor反向注册完毕后,Driver开始执行main程序。
Yarn 模式运行机制
Yarn Client 模式

在YARN Client模式下,Driver在任务提交的本地机器上运行,Driver启动后会和ResourceManager通讯申请启动ApplicationMaster,随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster的功能相当于一个ExecutorLaucher,只负责向ResourceManager申请Executor内存。
ResourceManager接到ApplicationMaster的资源申请后会分配container,然后ApplicationMaster在资源分配指定的NodeManager上启动Executor进程,Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
Yarn Cluster 模式
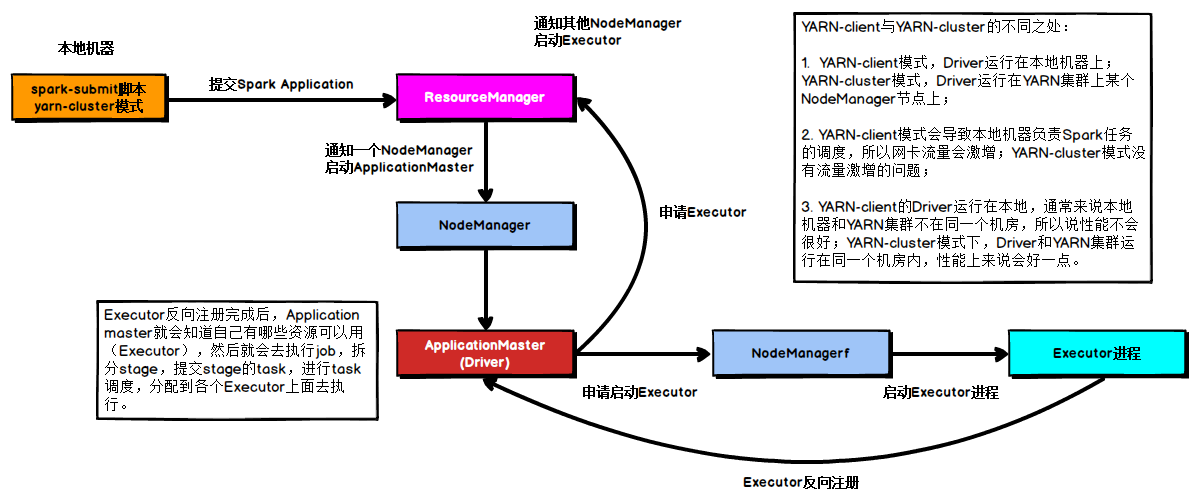
在YARN Cluster模式下,任务提交后会和ResourceManager通讯申请启动ApplicationMaster,随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster就是Driver。
Driver启动后向ResourceManager申请Executor内存,ResourceManager接到ApplicationMaster的资源申请后会分配container,然后在合适的NodeManager上启动Executor进程,Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
作者:十一喵先森
链接:https://juejin.im/post/5e1c414fe51d451cad4111d1
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我的解释:
Standalone Cluster模式
spark集群----一个公司.腾讯
master----老板
worker----部门
driver---项目经理
execotur---执行器---程序员
application---自己编写的程序---客户提要求
流程:
任务提交后,
Master(老板)会找到一个Worker(部门)启动Driver(项目)进程
把application(客户的需求)提交给driver(项目经理),
driver(项目经理)去spark(公司)集群中找到master(老板)要资源,需要多部门配合.
master(老板)会根据调度算法找到可用的多个worker(部门),
Driver(项目经理)在worker(部门)中启动executor(程序员)程序.
Driver(项目经理)开始执行main函数,之后执行到Action算子时,开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor(程序员)上执行
Yarn Cluster 模式
Application---需求
ApplicationMaster(Driver)---项目经理
Executor---程序员
yarn---公司
ResourceManager---老板
NodeManager---部门
流程:
本地机器提交application(需求)到resourcemanager(老板),
resourcemanager(老板)在NodeManager(部门)上启动ApplicationManster(项目),就是driver.
ApplicationMaster(项目经理)向ResourceManager(老板)申请Executor(程序员)内存,
在合适的多个NodeManager(部门)上启动Executor(程序员)进程,
Driver(项目经理)开始执行main函数,
并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor(程序)上执行。