生成数据:
############################# 使用StandardScler进行数据预处理 ####################################### #导入numpy import numpy as np #导入画图工具 import matplotlib.pyplot as plt #导入数据集生成工具 from sklearn.datasets import make_blobs #先创建50个数据点,让他们分为两类 X,y = make_blobs(n_samples=40,centers=2,random_state=50,cluster_std=2) #用散点图绘制数据点 plt.scatter(X[:, 0],X[:, 1],c=y,s=30,cmap=plt.cm.cool) #显示图像 plt.show()
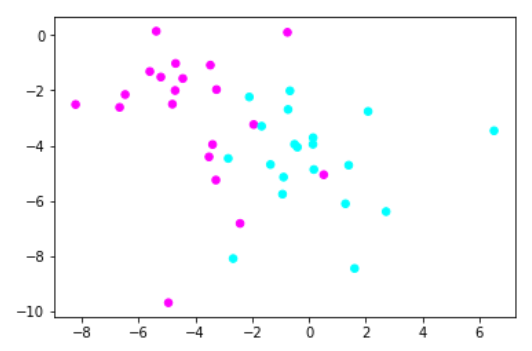
1.使用StandardScaler进行数据预处理
#导入StandardScaler from sklearn.preprocessing import StandardScaler #使用StandardScaler进行数据预处理 X_1 = StandardScaler().fit_transform(X) #用散点图绘制经过预处理的数据点 plt.scatter(X_1[:, 0],X_1[:, 1],c=y,cmap=plt.cm.cool) #显示图像 plt.show()
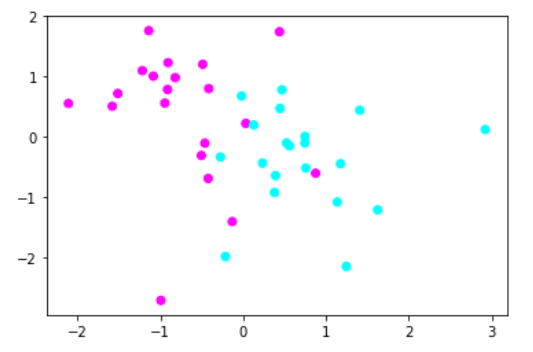
2.使用MinMaxScaler进行数据预处理
############################# 使用MinMaxScler进行数据预处理 ####################################### #导入数据集生成工具 from sklearn.datasets import make_blobs #先创建50个数据点,让他们分为两类 X,y = make_blobs(n_samples=40,centers=2,random_state=50,cluster_std=2) #导入MinMaxScaler from sklearn.preprocessing import MinMaxScaler #使用MinMaxScaler进行数据预处理 X_2 = MinMaxScaler().fit_transform(X) #用散点图绘制数据点 plt.scatter(X_2[:, 0],X_2[:, 1],c=y,cmap=plt.cm.cool) #显示图像 plt.show()
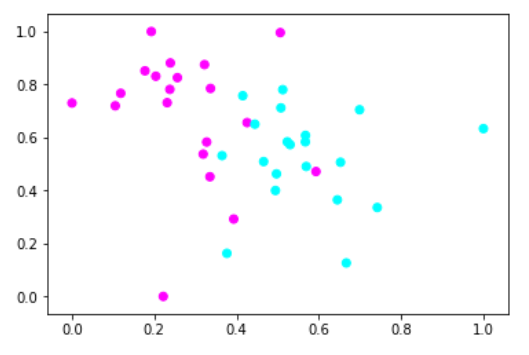
3.使用RobustScaler进行数据预处理
############################# 使用RobustScler进行数据预处理 ####################################### #导入数据集生成工具 from sklearn.datasets import make_blobs #先创建50个数据点,让他们分为两类 X,y = make_blobs(n_samples=40,centers=2,random_state=50,cluster_std=2) #导入RobustScaler from sklearn.preprocessing import RobustScaler #使用MinMaxScaler进行数据预处理 X_3 = RobustScaler().fit_transform(X) #用散点图绘制数据点 plt.scatter(X_3[:, 0],X_3[:, 1],c=y,cmap=plt.cm.cool) #显示图像 plt.show()
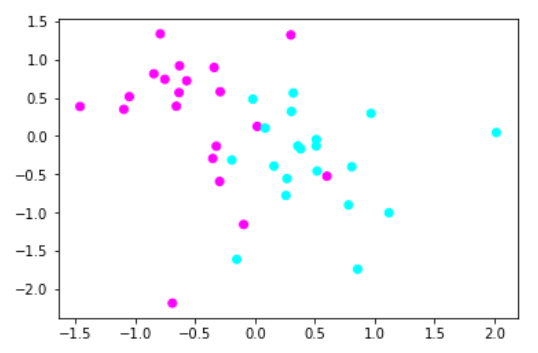
4.使用Normalizer进行数据预处理
############################# 使用Normalizer进行数据预处理 ####################################### #导入数据集生成工具 from sklearn.datasets import make_blobs #先创建50个数据点,让他们分为两类 X,y = make_blobs(n_samples=40,centers=2,random_state=50,cluster_std=2) #导入RobustScaler from sklearn.preprocessing import Normalizer #使用MinMaxScaler进行数据预处理 X_4 = Normalizer().fit_transform(X) #用散点图绘制数据点 plt.scatter(X_4[:, 0],X_4[:, 1],c=y,cmap=plt.cm.cool) #显示图像 plt.show()
通过数据预处理提高模型准确率
1.导入数据集
############################# 通过数据预处理提高模型准确率 ####################################### #导入红酒数据集 from sklearn.datasets import load_wine #导入MLP神经网络 from sklearn.neural_network import MLPClassifier #导入数据集拆分工具 from sklearn.model_selection import train_test_split #建立训练集和测试集 wine = load_wine() X_train,X_test,y_train,y_test = train_test_split(wine.data,wine.target,random_state=62) #打印数据形态 print(X_train.shape,X_test.shape)
(133, 13) (45, 13)
2.使用MLP神经网络模型
#设定MLP神经网络的参数
mlp= MLPClassifier(hidden_layer_sizes=[100,100],max_iter=400,random_state=62)
#使用MLP拟合数据
mlp.fit(X_train,y_train)
#打印模型得分
print('模型得分:{:.2f}'.format(mlp.score(X_test,y_test)))
模型得分:0.93
3.使用MinMaxScaler进行数据预处理
#使用MinMaxScaler进行数据预处理
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train_pp = scaler.transform(X_train)
X_test_pp = scaler.transform(X_test)
#重新训练模型
mlp.fit(X_train_pp,y_train)
#打印模型得分
print('模型得分:{:.2f}'.format(mlp.score(X_test_pp,y_test)))
模型得分:1.00
注 : 我们在使用MInMaxScaler拟合了原始的训练数据集,再用它去转换原始的训练数据集和测试数据集
切记不要用它先拟合原始的测试数据集,再去转换测试数据集,这样就失去了数据转换的意义.
总结 :
StandardScaler的原理是,将所有数据的特征值转换为均值为0,而方差为1的状态,这样就可以确保数据的"大小"都是一致的.
MinMaxScaler的原理是,可以想象成把数据压进了一个长和宽都是1的方格子中了.
RobustScaler的原理是,和StandardScaler比较近似,但是它并不是均值和方差来进行转换,而是使用中位数和四分位数.
Normalizer的原理是,将所有样本的特征向量转化为欧几里得距离为1,即把数据的分布变成一个半径为1的圆,或者是一个球.
在进行数据预处理后,模型的准确率大大提高了,特别对那些需要进行数据预处理的模型,效果是显著的.
文章引自 : 《深入浅出python机器学习》